
本文作者为沃尔玛开发者 Ankur Ranjan 与 Sai Vineel Thamishetty 。二人长期关注 Apache Kafka 与流处理系统的演进,深入研究现代流处理架构面临的挑战与创新方向。文章不仅总结了 Kafka 的历史价值与当前局限,还展示了下一代开源项目 AutoMQ 如何借助云原生设计,解决 Kafka 在成本、扩展性与运维方面的痛点,为实时数据流架构提供全新视角。
注意:本文内容译自英语原文。若您希望获得最原汁原味、最准确的阅读体验,可点击底部【阅读原文】阅读英文文章。
Kafka:数据运营与数据分析之间的桥梁
我已经使用 Apache Kafka 多年,并且非常喜欢这个工具。作为一名数据工程师,我主要将它用作连接数据运营端与数据分析端的桥梁。凭借优雅的设计和强大的功能,Kafka 长期以来一直是流处理领域的标杆。
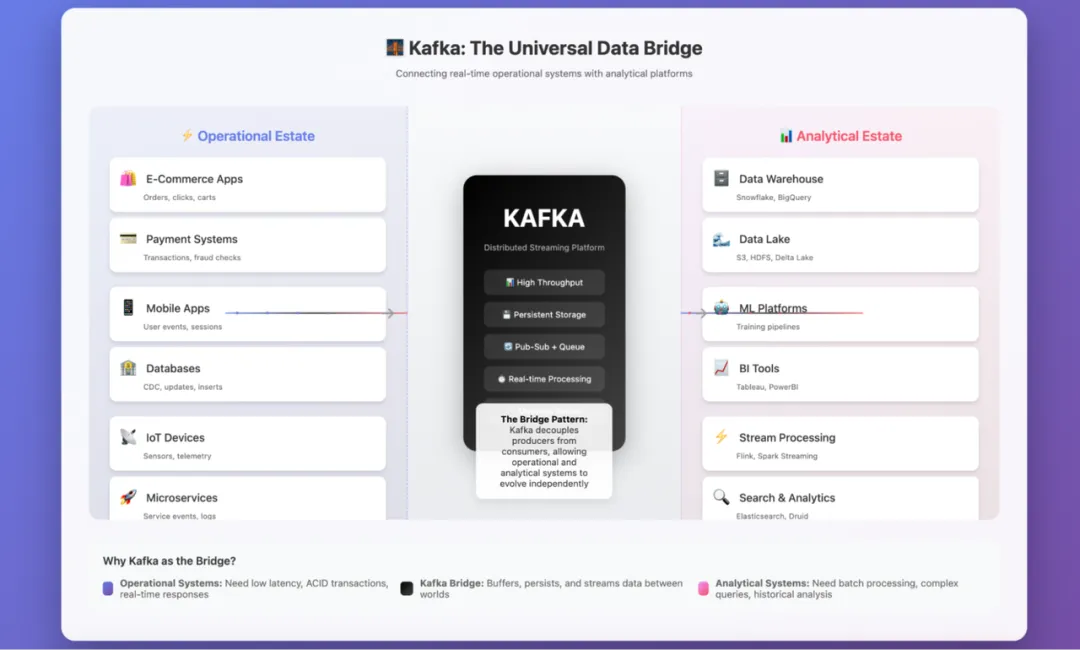
Kafka 扮演着连接数据运营端与数据分析端的桥梁角色。
自问世以来,Kafka 就凭借独特的分布式日志抽象,塑造了现代流处理架构。它不仅为实时数据流处理提供了无可比拟的能力,还围绕自身构建了完整的生态系统。
Kafka 的成功源于其核心优势:能够大规模地实现高吞吐量与低延迟处理。这一特性使其成为各类规模企业的可靠选择,并最终确立了其在流处理领域的行业标准地位。
但 Kafka 的发展之路并非一帆风顺。它的成本可能急剧攀升,而在流量高峰时段进行分区重分配等运维难题,更是令人头疼不已。
我至今还记得在沃尔玛工作时的经历:曾花费数小时排查一次恰逢流量高峰发生的分区重分配问题,那次经历几乎让我心力交瘁。
尽管成本居高不下,Kafka 在流处理领域的主导地位依然稳固。在如今云优先的大环境下,一个多年前基于本地磁盘存储设计的系统,至今仍是众多企业的核心支撑,这着实令人意外。
深入研究后我发现,背后的原因并非 Kafka “完美无缺”,而是长期以来缺乏合适的替代方案。其最大的卖点 —— 速度、持久性与可靠性,至今仍具有重要价值。
但只要使用过 Kafka,你就会知道:它将所有数据都存储在本地磁盘上。这一设计暗藏着一系列成本与挑战,包括磁盘故障、扩展难题、突发流量应对,以及受限于本地或私有部署存储容量等问题。
几个月前,我偶然发现了一个名为 AutoMQ 的开源项目。起初只是随意研究,后来却深入探索,彻底改变了我对流处理架构的认知。
因此,在本文中,我们希望分享两方面内容:一是 Kafka 传统存储模型面临的挑战,二是以 AutoMQ 为代表的现代解决方案如何通过云对象存储(而非本地磁盘)另辟蹊径解决这些问题。这一转变在保留 Kafka 熟悉的 API 与生态系统的同时,让 Kafka 具备更强的扩展性、更高的成本效益与更优的云适配性。
不容忽视的问题:Kafka 为何停滞不前
坦白说,Kafka 十分出色,它彻底改变了我们对数据流的认知。但每当我配置昂贵的 EBS 卷、看着分区重分配进程缓慢推进数小时,或是凌晨 3 点因某个 Broker 磁盘空间耗尽而被惊醒时,我总会忍不住思考:一定有更好的解决方案。
这些问题的根源何在?答案是 Kafka 的 shared-nothing 架构。每个 Broker 都像一个 “隐士”:独自拥有数据,将其小心翼翼地存储在本地磁盘上,拒绝与其他 Broker 共享。这种设计在 2011 年合情合理,当时我们使用私有部署服务器,本地磁盘是唯一的存储选择。但在如今的云时代,这就好比在所有人都使用谷歌云盘(Google Drive)的情况下,仍坚持使用文件柜存储数据。
这种架构实际带来了以下成本负担:
9 倍的数据冗余(没错,你没看错 ——Kafka 3 倍副本 × EBS 3 倍副本)。
分区重分配进程极其缓慢,如同看着油漆变干。
完全缺乏弹性 —— 尝试对 Kafka 进行自动扩展,你会发现整个周末都要耗费在这上面。
跨可用区(AZ)流量费用高到让首席财务官(CFO)头疼。
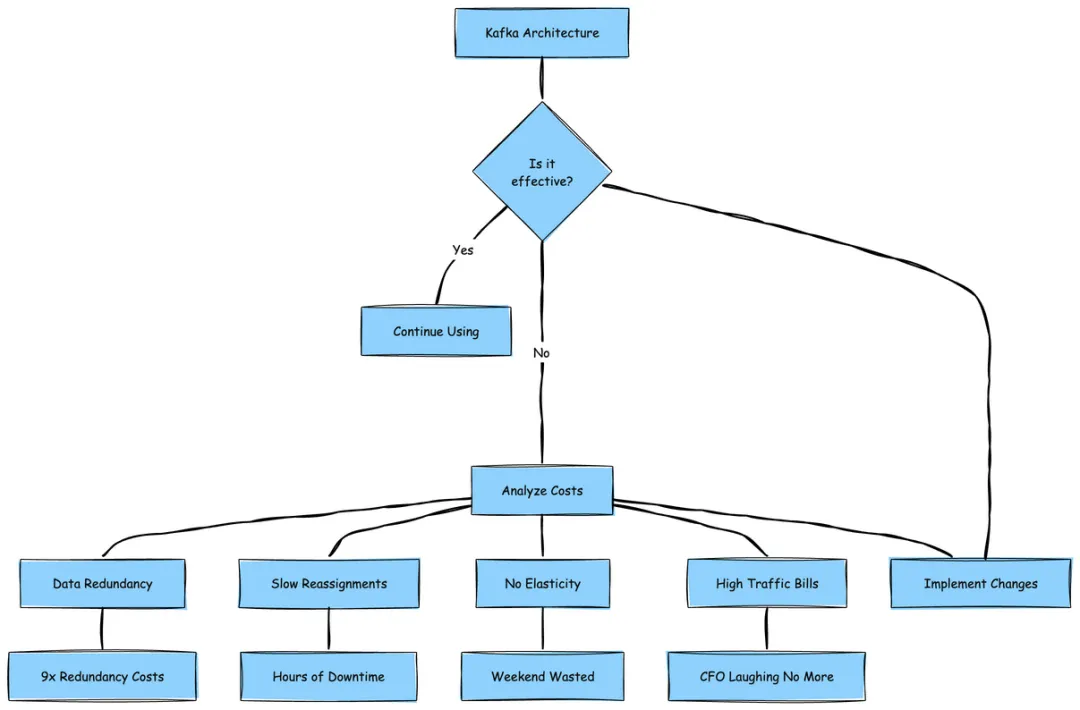
Kafka 的运维成本:Shared-Nothing 架构的代价
我想通过一个故事,直观展现 Kafka 的成本问题。
假设你运营着一个小型电商网站,每小时仅摄入 1GB 数据,包括用户点击、订单信息、库存更新等,数据量并不算大。在过去,你只需将这些数据存储在一台服务器上即可。但如今是 2025 年,为确保高可用性,你选择部署 Kafka。
而 Shared-Nothing 架构在此刻开始让你付出高昂代价。
Shared-Nothing 的真正含义
在 Kafka 的体系中,“Shared-Nothing” 意味着每个 Broker 都像一个 “多疑的隐士”,彼此之间不共享任何资源 —— 无论是存储、数据,还是其他任何东西。每个 Broker 都拥有独立的本地磁盘,自行管理数据,本质上把其他 Broker 当作 “恰好共事的陌生人”。
这就好比三个室友拒绝共享 Netflix 账号,反而各自付费订阅,将相同的节目下载到自己的设备上,并小心翼翼地守护着自己的密码。听起来成本很高?事实确实如此。
三重(甚至更严重的)打击
接下来,让我们看看成本问题有多棘手。
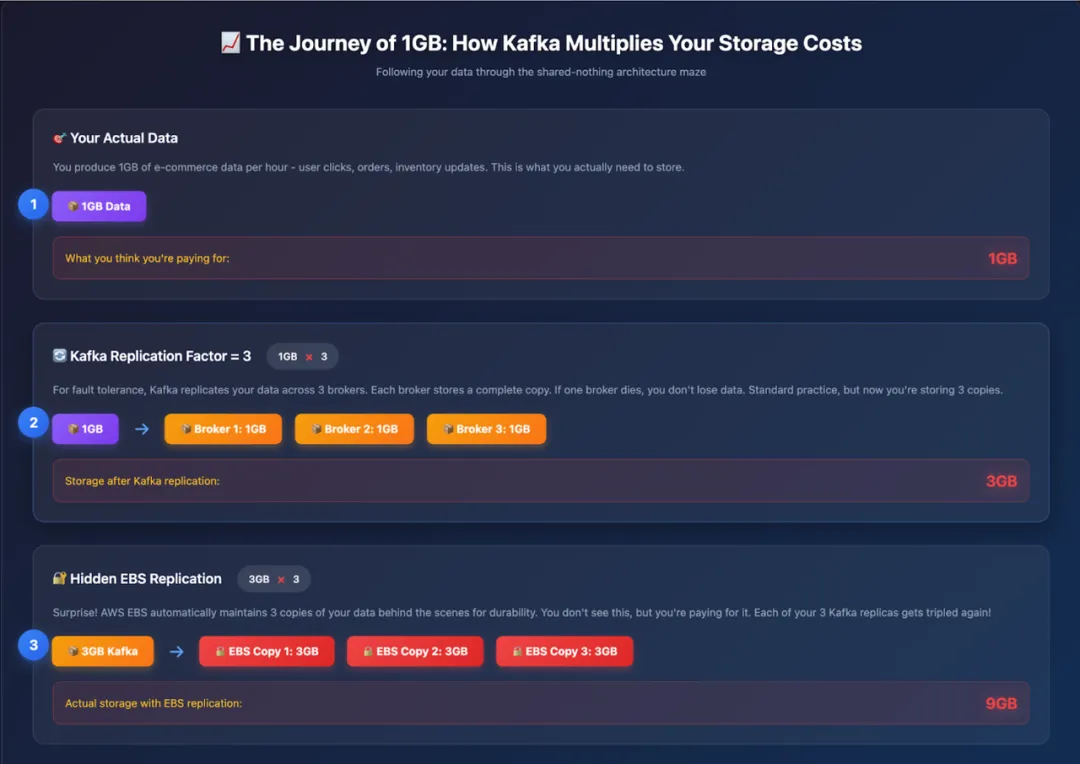
请仔细观察上图。
现在,让我们跟踪 1GB / 小时的数据在 Kafka 副本机制中的流转过程:
第 1 小时:应用产生 1GB 数据。
Kafka 副本(副本因子 RF=3):1GB 数据在 Broker 间复制为 3GB。
EBS 副本:这 3GB 数据的每个副本又被 AWS 复制 3 份,最终变为 9GB。
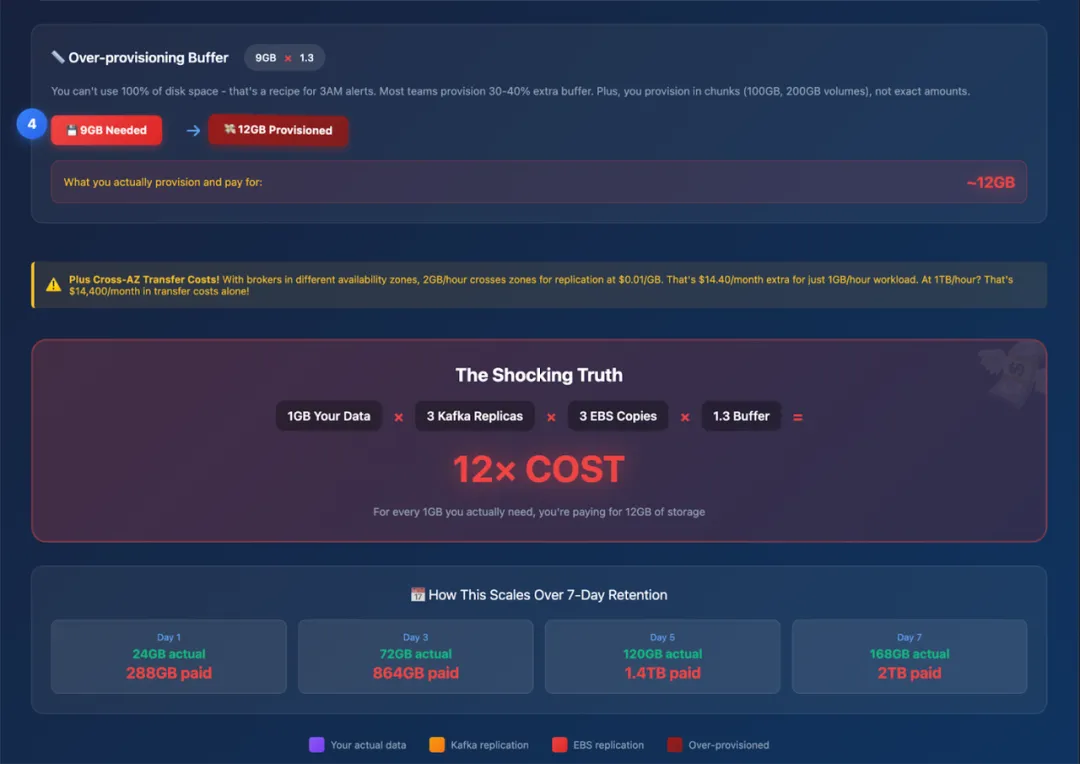
预留空间:为避免午夜告警,需额外预留 30%-40% 的缓冲空间,最终需配置约 12GB 存储。
也就是说,每摄入 1GB 数据,你需要为约 12GB 的存储付费
一周的数据流转(与费用消耗)
若设置 7 天的数据保留期(常见配置):
第 1 天:实际数据 24GB,需配置 288GB 存储。
第 3 天:实际数据 72GB,需配置 864GB 存储。
第 7 天:实际数据 168GB,需配置约 2016GB 存储。
更关键的是:即便你只需要消费最近 1 小时的数据,仍需为整整 7 天的数据存储与复制付费。
以上仅是粗略计算,旨在说明 Apache Kafka 的高成本问题。
雪上加霜的跨可用区成本
跨可用区复制让成本问题进一步恶化:
当数据摄入速率为 1GB / 小时(RF=3)时:
每小时有 2GB 数据跨可用区传输。
每月约产生 1460GB 跨区流量,按每 GB 约 0.02 美元计算(双向传输各按每 GB 约 0.01 美元计费),每月费用约 29 美元。
当数据摄入速率为 100MB / 秒(RF=3)时:
副本机制新增 200MB / 秒的跨可用区流量。
生产者向其他可用区的 Leader 节点写入数据,又新增约 67MB / 秒的跨区流量。
总跨区流量约为 267MB / 秒,每月流量达 700800GB。
仅跨可用区副本流量与生产者流量的月度费用就约为 1.4 万美元。
若消费者也跨可用区拉取数据,月度费用将攀升至约 1.75 万美元。
核心结论
在 2011 年,Shared-Nothing 架构合情合理。当时我们使用物理服务器与本地磁盘,存储区域网络(SAN)的性能无法与本地磁盘相比。
但在云时代,你需要为相同的数据支付 12 倍的存储费用,再加上网络费用与管理大量磁盘的运维成本。这就好比在 Netflix 时代仍购买 DVD,不仅如此,还为每张 DVD 购买 3 份副本,存放在 3 个不同的地方,并雇人确保这些副本同步更新。
如今情况已然不同。S3 已成为云存储的事实标准,具备低成本、高持久性与全局可用性的特点。正因如此,包括数据库、数据仓库乃至如今的流处理平台在内的各类系统,都在围绕共享存储架构进行重新设计。
AutoMQ、Aiven、Redpanda 等项目顺应这一趋势,将存储与计算解耦。它们不再在 Broker 间无休止地复制数据,而是利用 S3 保障数据持久性与可用性,既减少了基础设施重复建设,又降低了跨可用区网络成本。
这些项目均致力于减少资源重复、降低跨可用区成本,并采用云原生设计。目前,大多数试图降低 Apache Kafka 成本的新兴项目,实际上都采用了以下两种方案之一:
部分项目推动 Kafka 向全共享存储模型演进 ——Broker 变为无状态,存储完全依托 S3。
另一些项目则采用分层存储方案 —— 将旧数据段迁移至 S3/GCS 等远程存储,减少本地磁盘占用,但仍保留热数据层。
当然,在 S3 上运行 Kafka 也面临自身挑战,例如延迟、一致性与元数据管理等问题。我们将在后续内容中深入探讨这些挑战,并重点分析 AutoMQ 等开源新项目如何高效解决这些问题。
一定有更好的方案,对吧?
(剧透:答案是肯定的 —— 这正是我们深入探索的起点……)
Kafka 分层存储(Tiered Storage)方案的提出
Kafka 社区一直在积极讨论并开发分层存储功能(参见 KIP-405)。
在阐述我认为该设计可能存在缺陷的原因之前,先让我们用通俗的语言解释一下什么是分层存储。
传统上,Kafka Broker 将所有数据存储在本地磁盘中。这种方式速度快,但成本高且扩展性差 —— 一旦磁盘空间耗尽,你要么增加更多 Broker,要么更换更大容量的磁盘,这导致存储扩展与计算扩展深度绑定。
分层存储打破了这一模式,将数据分为两层:
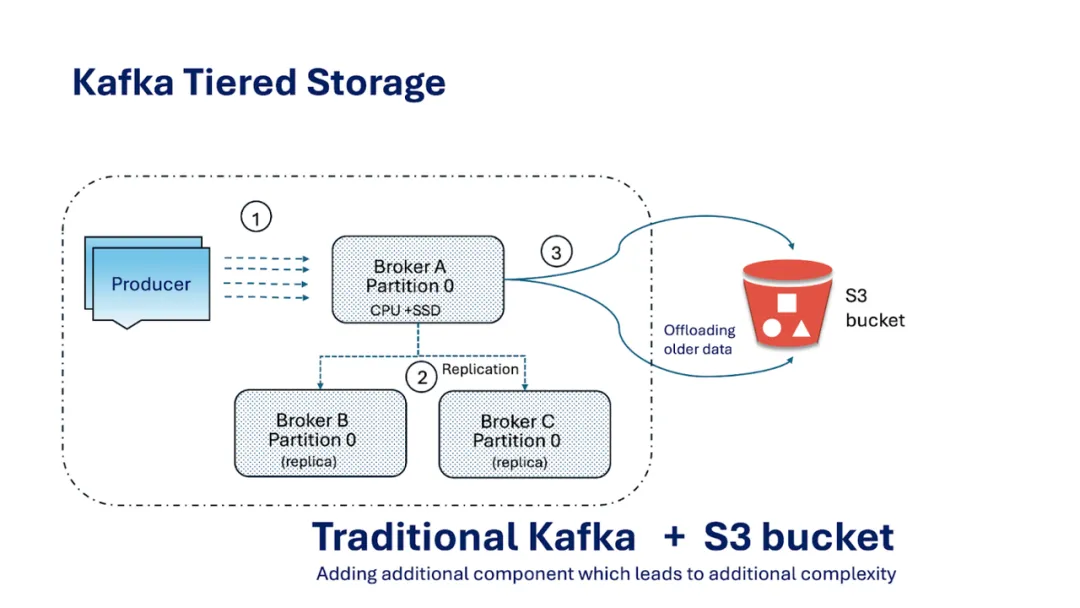
Kafka 分层存储的核心特点
热数据 / 本地层
该层位于 Kafka Broker 的本地磁盘中,存储最新数据,针对高吞吐量写入与低延迟读取进行优化。
冷数据 / 远程层
该层采用独立的、通常成本更低且扩展性更强的存储系统。旧数据段会被异步上传至这一远程层,从而释放 Broker 的本地磁盘空间。
数据流转
仅当日志段关闭后,才会将其上传至远程层。消费者可从任意一层读取数据;若 Broker 本地无目标数据,则 Kafka 会从远程层拉取数据。
分层存储宣称的优势
成本更低:旧数据存储在 S3/GCS 等远程存储中,而非昂贵的 Broker 本地磁盘。
弹性更强:存储与计算可实现更高程度的独立扩展。
运维更优:本地数据量减少,Broker 重启与恢复速度更快。
从理论上看,这是一个巧妙的折中方案:将热数据就近存储以保证性能,将冷数据迁移至远程存储以降低成本。
为何分层存储仍未真正解决问题
接下来,我将分享我的观点:我认为分层存储只是对深层问题的 “治标不治本”。
还记得我们提到的 1GB 电商数据最终膨胀至约 12GB 的案例吗?分层存储无法解决这一根本性问题。这就好比在房屋地基开裂时,却只对厨房进行翻新。
让我们逐一分析其中原因。
问题 1:难以摆脱的 “热数据长尾”
Kafka 必须将活跃数据段存储在本地磁盘中,这一规则始终不变。只有当数据段 “关闭” 后,才可能被迁移至远程层。
一个活跃数据段的大小可能是 1GB,在黑色星期五等流量高峰时段甚至可能达到 50GB。若乘以 3 倍副本因子(RF=3),仅单个分区就需要在昂贵的本地磁盘中存储 150GB 数据。
因此,尽管旧数据被迁移至远程存储,但热数据长尾依然存在,且数据量可能非常庞大。
问题 2:分区重分配仍令人头疼
新增 Broker?重新平衡分区?分层存储仅能起到微小的缓解作用。
举例来说:
无分层存储时:可能需要迁移 500GB 数据,耗时长达 12 小时,过程痛苦。
有分层存储时:可能仅需迁移 100GB 热数据,耗时缩短至 2-3 小时。
不可否认,分层存储确实有所改善。但如果你的网站在结账高峰期出现故障,等待数小时迁移数据仍然无法接受。扩展瓶颈依然存在。
问题 3:隐性的复杂性代价
我的工程师思维这样总结道:
“现在我需要管理两个存储系统,而不是一个。我既要排查本地磁盘问题,又要处理 S3 相关问题。监控指标翻倍,告警数量翻倍。有时数据甚至会卡在两层之间无法流转。”
分层存储并未简化运维,反而增加了更多移动部件。这就好比为了整理凌乱的书桌,却买了一张新的书桌 —— 问题并未得到根本解决。
我的结论
分层存储设计巧妙,也确实能降低存储成本,但它无法解决 Kafka Shared-Nothing 架构中计算与存储深度耦合的根本问题。你仍需为热数据层成本、扩展摩擦与运维复杂性付出代价。
真正值得思考的问题并非 “如何降低 Broker 磁盘成本”,而是 “Broker 是否真的需要拥有磁盘”。
这正是 AutoMQ 等项目进一步探索的方向 —— 让 Broker 实现无状态,由共享云存储保障数据持久性。
但是……Broker 仍是有状态的,不具备云原生特性
随着我对 Kafka 的使用不断深入,我开始质疑其核心设计假设。
回顾我们此前讨论的 Kafka 各类缺陷,它们都指向一个缺失的关键特性:真正的云原生能力。
即便引入了分层存储,Kafka Broker 依然是有状态的,存储与计算仍紧密耦合。扩展或恢复 Broker 时,仍需进行数据迁移。
为了让 Kafka 真正实现云原生,社区开始探索 Diskless Kafka(参见 KIP-1150),实现计算与存储的完全解耦。
这就好比谷歌文档(Google Docs):不再将文件保存到本地硬盘,而是将所有数据存储在共享云空间中。Broker 不再 “拥有” 数据,仅负责连接共享存储。
试想这样的场景:
无需管理本地磁盘。
Broker 崩溃时无需恐慌 —— 不会有任何数据丢失。
无需再经历痛苦的分区重分配。
新增 Broker?只需接入集群即可。
移除 Broker?毫无问题 —— 数据安全地存储在其他位置。
这不就能解决我们此前讨论的半数难题吗?以上仅为我的个人思考,你或许能提出更优的方案。欢迎在评论区分享你的想法,或通过私信与我交流。
Diskless Kafka 才是破局之道
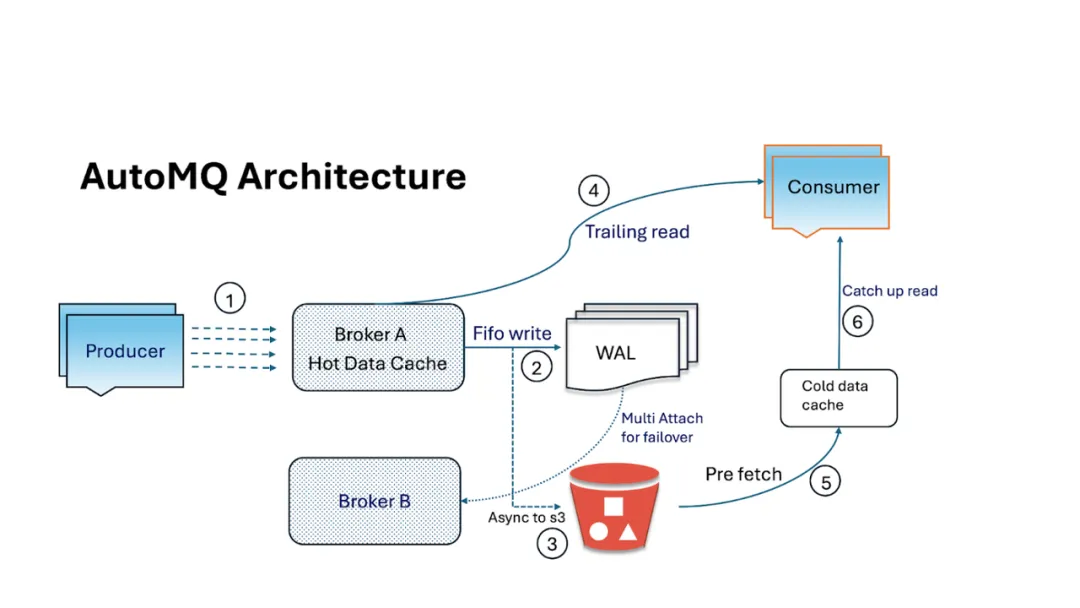
尽管 Apache Kafka 尚未推出 Diskless 版本,但 AutoMQ 等开源项目已实现了这一功能 —— 而我个人最欣赏的一点是,AutoMQ 与 Kafka API 实现了 100% 兼容。
早在 2023 年,AutoMQ 团队就着手打造真正云原生的 Kafka。他们很早就意识到,Amazon S3(及兼容 S3 的对象存储)已成为耐用云存储的事实标准。
AutoMQ 与 Kafka 实现 100% 兼容,但对存储层进行了彻底重构:
所有日志段均存储在云对象存储(如 S3)中。
Broker 变得轻量且无状态,仅作为协议路由器。
数据的可信来源不再是 Broker 磁盘,而是共享存储。
既然云服务商已提供近乎无限的容量、跨可用区副本与 “11 个 9” 的持久性,为何还要重新构建复杂的存储系统?AutoMQ 充分利用 S3(或兼容存储)保障数据持久性,Broker 仅负责数据的传入与传出。
这一设计带来了显著优势:
轻松扩展:计算与存储可独立扩展。新增 Broker 以提升吞吐量,存储则在云中自动扩展。
快速重平衡:无需进行数据迁移。新增或移除 Broker 时,仅需重新分配 Leader 即可。
更高持久性:云对象存储无需在 Broker 上维护 3 倍副本,即可提供数据冗余。
运维简化:Broker 可随时替换。若某个 Broker 故障,只需启动新的 Broker,无需进行副本同步。
换言之,Broker 变得像 “牛群” 一样可替代,而非需要精心呵护的 “宠物”。
我最喜欢用这样的比喻来形容:这就好比谷歌文档,不再将文件保存到本地 “C 盘”,而是将所有数据存储在共享云盘中。Broker 仅提供访问能力 —— 数据本身始终安全地存储在云中。
AutoMQ 摒弃了每个 Broker 在本地磁盘囤积数据的模式,提出了共享存储理念:所有 Kafka 数据存储在一个公共云仓库中,任何 Broker 均可访问。这并非空想 ——AutoMQ 已通过与 Kafka 完全兼容的分支实现了这一设计,有效解耦了 Kafka 架构中的计算与存储。
本质上,他们选择站在 “巨人”(云服务商)的肩膀上,而非重复 “造轮子”。既然 S3 等服务已开箱即用地提供近乎无限的容量、跨可用区副本与极高的耐用性,为何还要从零构建复杂的存储系统?
要理解 AutoMQ 的创新,不妨想象 Kafka 以谷歌文档的模式运行:Broker 不再将数据保存到本地 “C 盘”,而是写入一个所有人共享的云盘。具体而言,AutoMQ 的 Broker 是无状态的,仅作为轻量级 “交通警察”,解析 Kafka 协议并实现数据与存储之间的路由。Kafka 日志段不再存储在 Broker 磁盘中,而是以云对象存储(S3)作为可信来源。这一设计带来了诸多显著优势。
首先,数据持久性大幅提升 —— 你可利用 S3 内置的副本机制与可靠性,无需在不同 Broker 上维护 3 份数据副本。其次,成本显著降低 —— 大规模使用对象存储的成本远低于部署大量本地 SSD(尤其是考虑到这些 SSD 还需维护 3 倍副本)。此外,扩展变得几乎 “即插即用”。
需要更高吞吐量?只需新增更多 Broker 实例(计算资源),并将其指向同一存储即可;无需通过大规模数据迁移来重新平衡分区。Broker 变得像 “牛群” 一样可替代,而非 “宠物”—— 若某个 Broker 故障,新的 Broker 可立即启动并提供数据服务,因为数据安全地存储在其他位置。这正是 Kafka 此前一直难以实现的云弹性。正如一位 Kafka 云架构师所言:“存储在云中自动扩展,Broker 只需提供数据传入与传出的处理能力。”
最后,让我们总结 AutoMQ Diskless 架构带来的优势。
Diskless 架构优势
轻松扩展:计算(Broker)与存储独立扩展。新增 Broker 以提升吞吐量,存储则在云中自动扩展。无需再过度配置磁盘空间,按实际使用付费即可。
快速重平衡:无需迁移分区数据。新增或移除 Broker 时,仅需重新分配 Leader,过程几乎即时完成。
更高持久性:对象存储提供 “11 个 9” 的耐用性,远优于 Broker 副本机制。
运维简化:Broker 故障无关紧要,只需替换即可。无需数据恢复或副本同步。
延迟挑战
理论上,Diskless Kafka 堪称完美,但它存在一个问题:对象存储会引入延迟。
低延迟是 Kafka 的核心优势,而直接向 S3 或 GCS 写入数据会导致延迟增加,并产生 API 开销。
AutoMQ 在此处做出了明智的设计:引入预写日志(Write-Ahead Log,WAL)抽象。消息首先追加到一个小型、耐用的 WAL(基于 EBS/NVMe 等块存储)中,而长期持久性则由 S3 保障。这一设计在保持 Broker Diskless 特性的同时,有效降低了延迟。
能否进一步优化?
在某些场景中,延迟至关重要,例如金融系统、高频交易、低延迟分析等。对于这些场景,即便是 AutoMQ 的 WAL 方案,也需要进一步创新。
AutoMQ 已表示将推出更深入的专有 / 商业解决方案:
直接写入 WAL:每条消息均写入耐用的云原生 WAL。
Broker 随后从缓存或内存中提供读取服务。
WAL 卷容量较小(如 10 GB),若某个 Broker 故障,可快速将其挂载到新的 Broker 上。
这与 Kafka 的分层存储有何不同?
分层存储:数据首先写入 Broker 磁盘,在 Broker 间复制,之后才将旧数据段迁移至 S3。
AutoMQ 的 Diskless 方案:完全无需 Broker 磁盘。数据持久性由云存储层直接保障,无需进行副本迁移。
若某个 Broker 故障,只需将其 WAL 卷挂载到新的 Broker 上,新 Broker 即可无缝接续旧 Broker 的工作。存储的生命周期超越计算。
这是一个重大的思维转变:计算资源可随时替换,存储则保持稳定。
在部分场景中,延迟的影响至关重要。因此,上述方案可能并非完美适配,仍需进一步优化。深入研究后我发现,AutoMQ 已针对这类场景提供了相应解决方案,但该方案似乎属于其专有 / 商业产品范畴。
这一解决方案可能看似复杂,但彰显了真正的工程智慧,是下一代基于 S3 的 Diskless Kafka 方案。
当然,与 SSD / 本地磁盘相比,S3 的速度确实较慢。此外,还需提升向云存储(S3)写入数据的效率,以减少 API 开销。
这与 Kafka 的分层存储是否相同?
我的第一反应也是如此:“等等,这难道不与 Kafka 将数据迁移至 S3 的分层存储方案一样吗?”
事实并非如此。二者的区别如下:
在启用分层存储的 Kafka 中,数据仍需先写入 Broker 本地磁盘,Broker 间的副本复制(ISR)仍是必需步骤,之后才会将旧数据段迁移至 S3。
在 AutoMQ 中,完全无需本地磁盘。数据直接写入云原生存储中的 WAL,无需副本复制,因为云卷本身已具备耐用性与冗余能力。
因此,这并非简单的优化,而是一种完全不同的设计。
若 Broker 故障怎么办?
这是一个很好的问题,也是我们接下来的 “顿悟” 时刻。
在 Kafka 中,若某个 Broker 故障,需重新分配分区并同步副本,过程十分痛苦。
而 AutoMQ 的处理方式完全不同:
每个 Broker 本质上是一个挂载了耐用云卷(EBS 或 NVMe)的计算实例。
假设 Broker A 正在向其 WAL(EBS)卷写入数据,突然发生故障。
无需担心,数据仍安全地存储在 WAL 卷中。
集群会迅速将该 WAL 卷挂载到 Broker B 上,Broker B 可无缝接续 Broker A 的工作。
整个过程无数据丢失、无副本迁移、无需等待。
本质上,在 AutoMQ 中,存储的生命周期超越 Broker。计算资源可随时替换,存储则保持稳定。
这与 Kafka 的设计理念存在巨大差异。AutoMQ 将计算与存储彻底解耦,这正是其设计的精妙之处。若你想深入了解,可查阅其官方文档。
最后的思考
若你能读到此处,感谢你的耐心阅读!
我们一直在探讨的理念简单却极具影响力:若用云存储取代本地磁盘,作为类 Kafka 系统的基础,会带来怎样的改变?
这一转变将大幅减少运维难题:
无需再进行 Broker 重分配。
无需再为磁盘告警惊慌失措。
扩展变得 “即插即用”。
令人振奋的是,AutoMQ 等项目正朝着这一方向探索,同时保持与 Kafka API 及工具的兼容性。
今日好文推荐
LangChain 彻底重写:从开源副业到独角兽,一次“核心迁移”干到 12.5 亿估值
“神级模型”Gemini 3.0实力刷屏!联手谷歌全新氛围编程工具重塑前端,如今只差官宣
著名物理学家、诺贝尔物理学奖得主杨振宁逝世;知乎又崩了!年内第三次“宕机”来袭;苹果AI又一核心高管跳槽Meta | Q资讯




