
Uber 构建了HiveSync,这是一个分片式批量复制系统,能够使 Hive 和 HDFS 数据在多个区域之间保持同步,它每天处理数百万个 Hive 事件。HiveSync 确保了跨区域数据的一致性,实现了 Uber 的灾难恢复策略,并消除了由次要区域闲置而导致的低效问题——此前次要区域需承担与主区域一样的硬件成本,而 HiveSync 在维持高可用性的同时彻底解决了这一问题
HiveSync 基于开源项目 Airbnb ReAir构建并做了一些扩展,包括实现了分片、基于DAG的编排以及控制平面和数据平面的分离。ETL作业现在只在主数据中心执行,而 HiveSync 处理跨区域复制,实现了近乎实时的一致性,保持了灾难应对能力和分析访问权限。分片功能允许将表和分区划分为独立的单元,从而实现并行复制和细粒度容错。
HiveSync 将控制平面(负责编排作业和管理关系元数据存储中的状态)与数据平面(执行HDFS和Hive文件操作)分离。Hive Metastore 事件监听器负责捕获 DDL 和 DML 变更,将它们记录到MySQL中,并触发复制工作流。任务以有限状态机的形式呈现,支持任务重启与健壮的故障恢复机制。
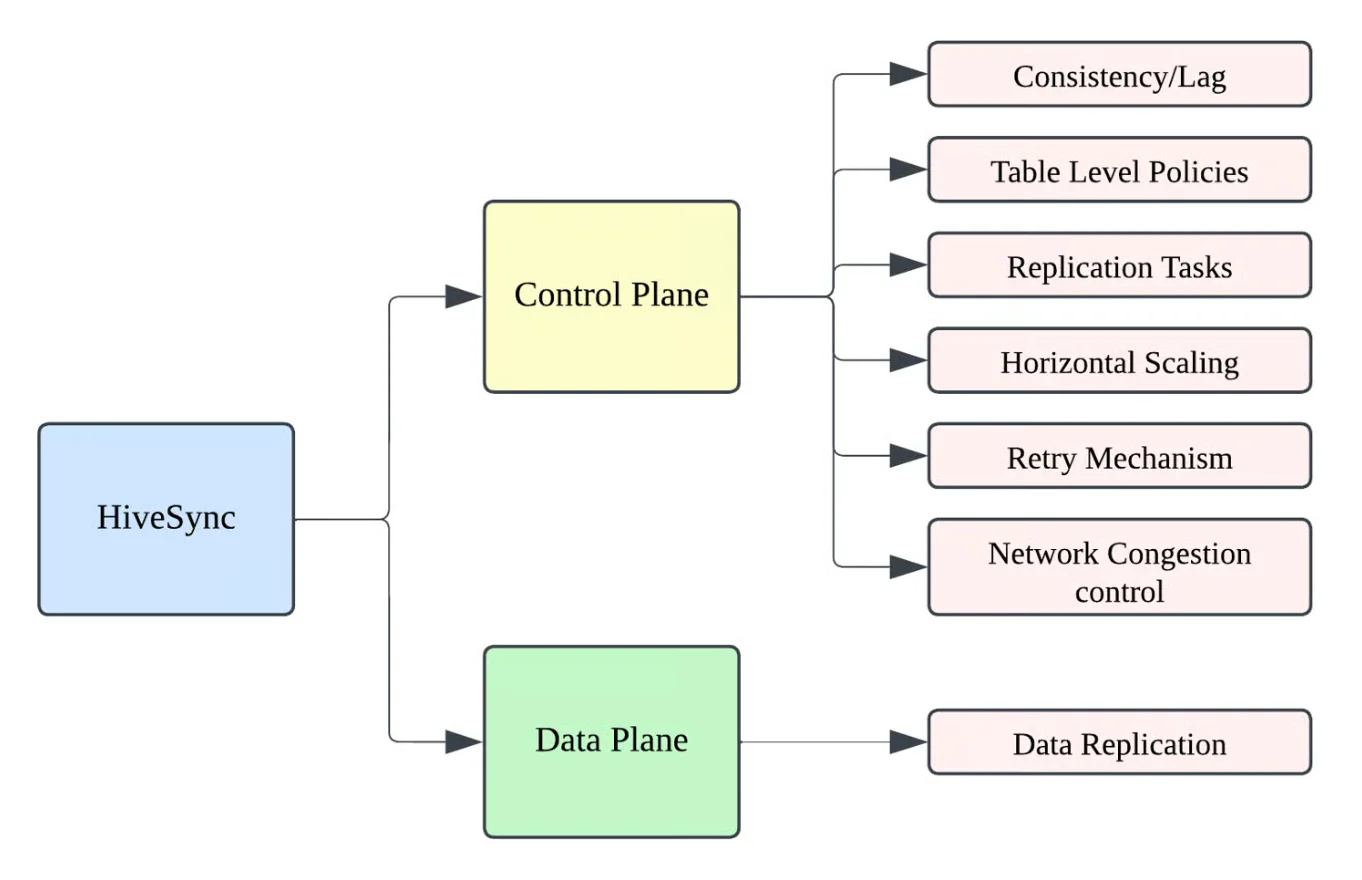
HiveSync 架构:控制平面和数据平面分离(来源:Uber博文)
HiveSync 有两个主要组件:HiveSync 复制服务和数据修复服务。复制服务使用 Hive Metastore 事件监听器实时捕获表和分区变更,将它们异步记录到 MySQL 中。这些审计条目被转换为异步复制作业,以有限状态机的形式执行,为确保可靠性,状态会被持久化。Uber 使用了混合策略:规模比较小的作业使用RPC以提高效率,而规模比较大的作业则利用YARN上的 DistCp。DAG 管理器强制执行分片级的排序和锁定,而静态和动态分片技术则实现了水平扩展,确保复制过程一致且无冲突。
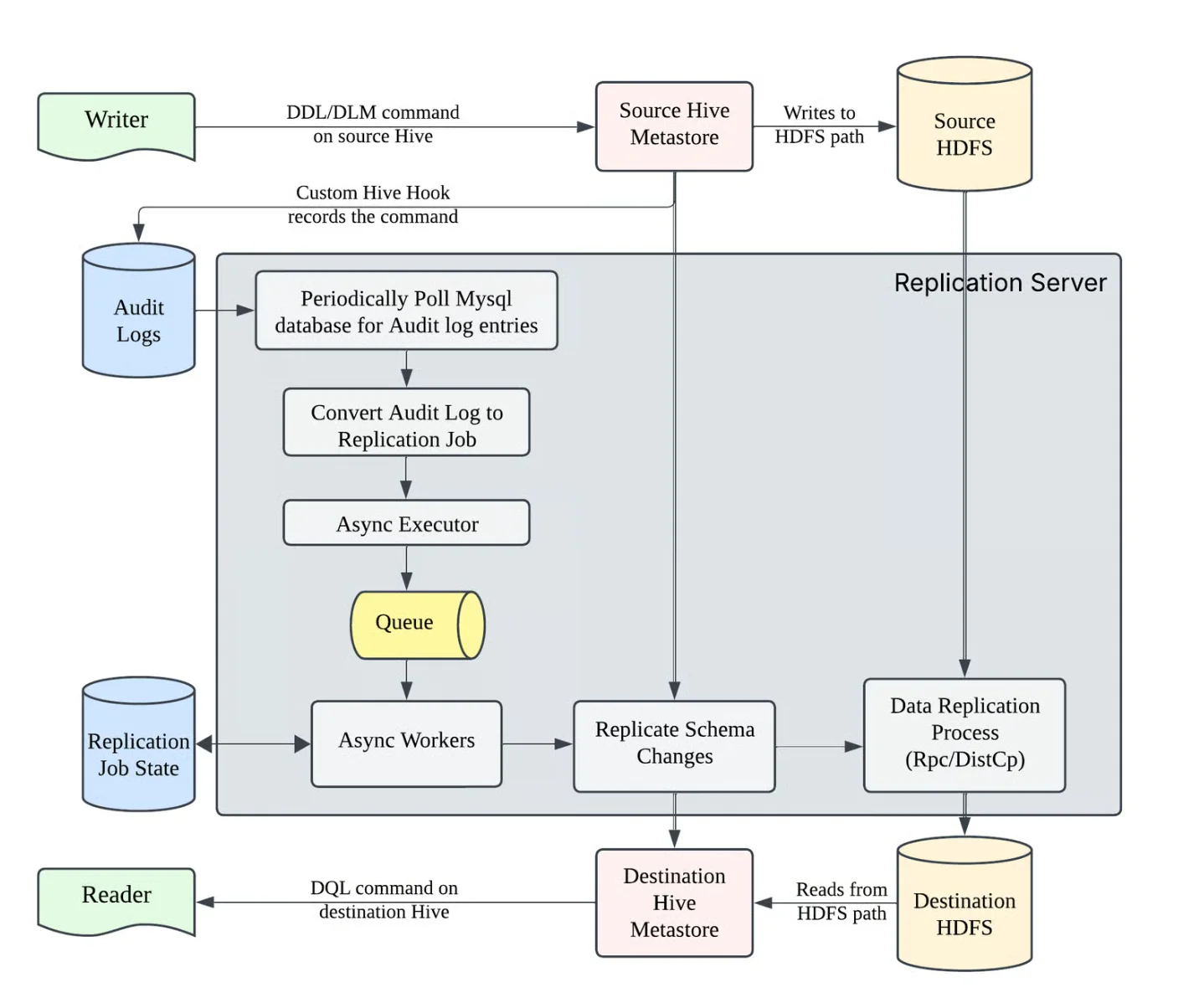
HiveSync 复制服务(来源:Uber博文)
数据修复是一个持续检测异常的服务,如缺失的分区或非预期的 HDFS 更新,恢复数据中心 1(DC1)和数据中心 2(DC2)之间的一致性,从而保证数据的正确性。HiveSync 保证了每四小时一次的复制 SLA,99百分位的延迟大约为 20 分钟,并支持一次性复制,用于在切换到增量复制之前,一次性地将历史数据集导入新区域或集群。Uber 的数据修复服务会扫描 DC1 和 DC2,检测异常(如缺失或多余的分区),并修复任何不匹配的情况,从而确保跨区域的一致性,目标是准确性超过 99.99%。
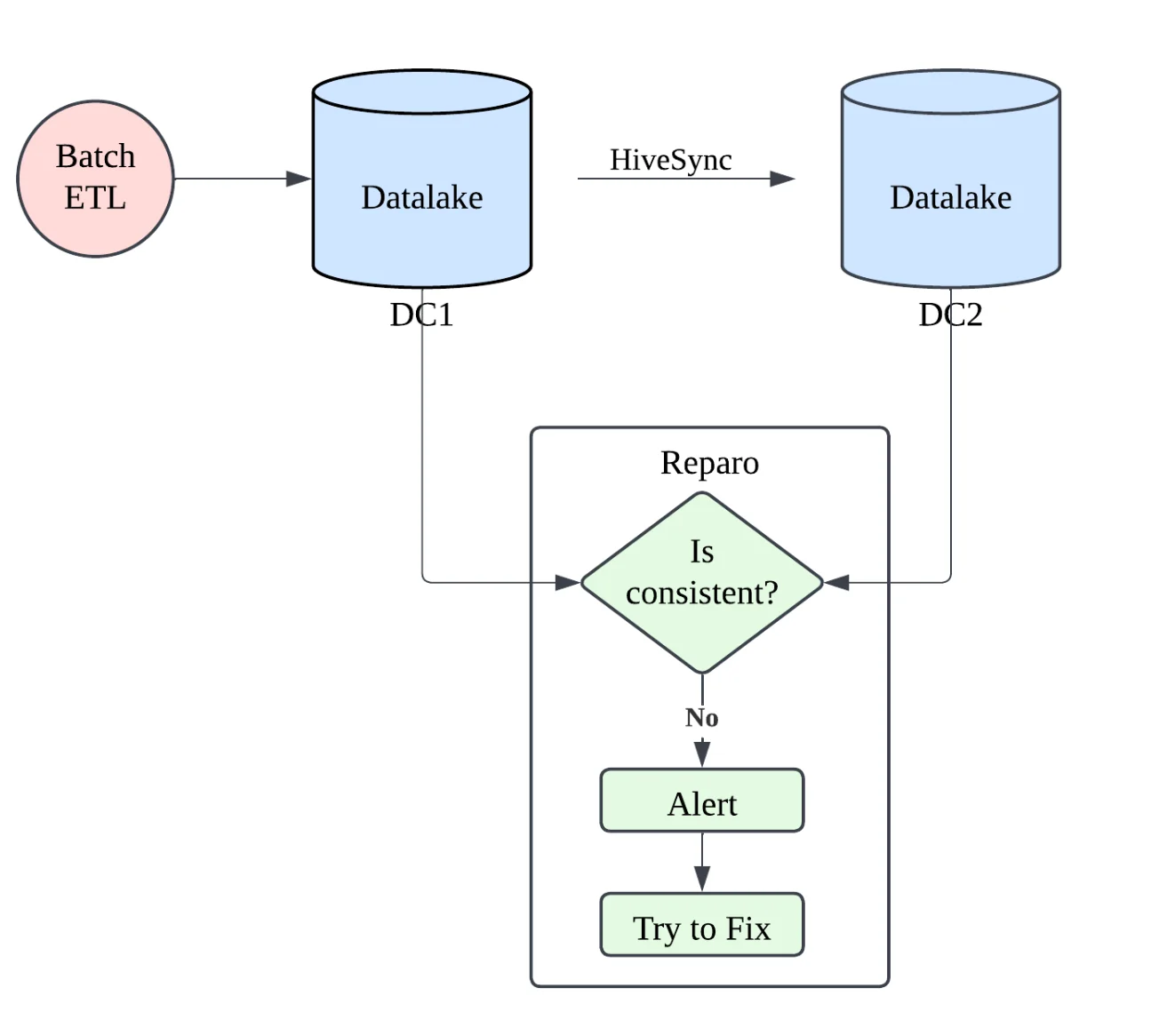
数据修复服务分析和解决数据中心之间的不一致性(来源:Uber博文)
HiveSync 的规模很大,管理着 80 万个 Hive 表,总计约 300PB 的数据,单表数据量从几 GB 到数十 PB 不等,单表分区数从几百到一百万多不等。每天,HiveSync 处理超过 500 万个 Hive DDL 和 DML 事件,跨区域复制约 8PB 的数据。
展望未来,随着批量分析和 ML 管道迁移到谷歌云平台,Uber 计划将 HiveSync 扩展到云端复制场景,进一步利用分片、编排和数据一致性技术来高效地维护其 PB 级数据的完整性。
原文链接:




