
摘要:
Lyft 实现了一套 AI 驱动的本地化系统,用以加速其应用与网页内容的翻译工作。该系统采用大语言模型结合人工审核的双路径流水线,可在数分钟内完成绝大多数的内容处理,这能够提升国际版本的发布速度,保证品牌一致性,并高效处理地区性习惯用语、法律文本等复杂场景。
Lyft 实现了一套AI驱动的本地化系统,用以加速其应用与网页内容的翻译工作,它能够在支撑全球化扩张的同时兼顾翻译质量与文化适配性。系统通过批量翻译流水线来处理约 99%的面向用户的内容,针对 95%的翻译任务设定了 30 分钟作为服务等级目标。像行程聊天等实时翻译则采用独立的低延迟优化流程。
此前,Lyft 严重依赖人工翻译流程,随着公司进入新市场且产品迭代速度加快,这一模式逐渐成为瓶颈。新系统将大语言模型(LLM)与自动评估、人工审核相结合,在大幅缩短交付周期的同时,保持语气、风格与法律文本的一致性。
批量翻译流水线采用双路径架构,源文本会同时提交至翻译管理系统(TMS)进行人工监管,并交由基于 LLM 的工作模块快速生成译稿。这一模式使得 AI 生成译文可立即投入使用,保障版本发布不受阻,同时翻译管理系统仍然会保留系统记录。语言专家异步审核译文,通过后的版本将替换初始输出,确保质量与一致性。
该流水线支持多条文本并行处理,并可进行多轮迭代优化。系统将职责划分为 Drafter 与 Evaluator 两个角色:Drafter 会产出多个版本的候选译文,Evaluator 则从准确性、流畅度、品牌契合度等维度进行评判,选出最优方案,或对较低置信度的结果发起重试。这种生成与评估解耦的设计,提升了错误检出能力并能够减少偏差。系统还会注入上下文信息,包括 UI 元数据、占位符、地区差异考量等因素,以保障翻译质量,同时通过确定性约束规则,严格把控安全、法律与风格的要求。
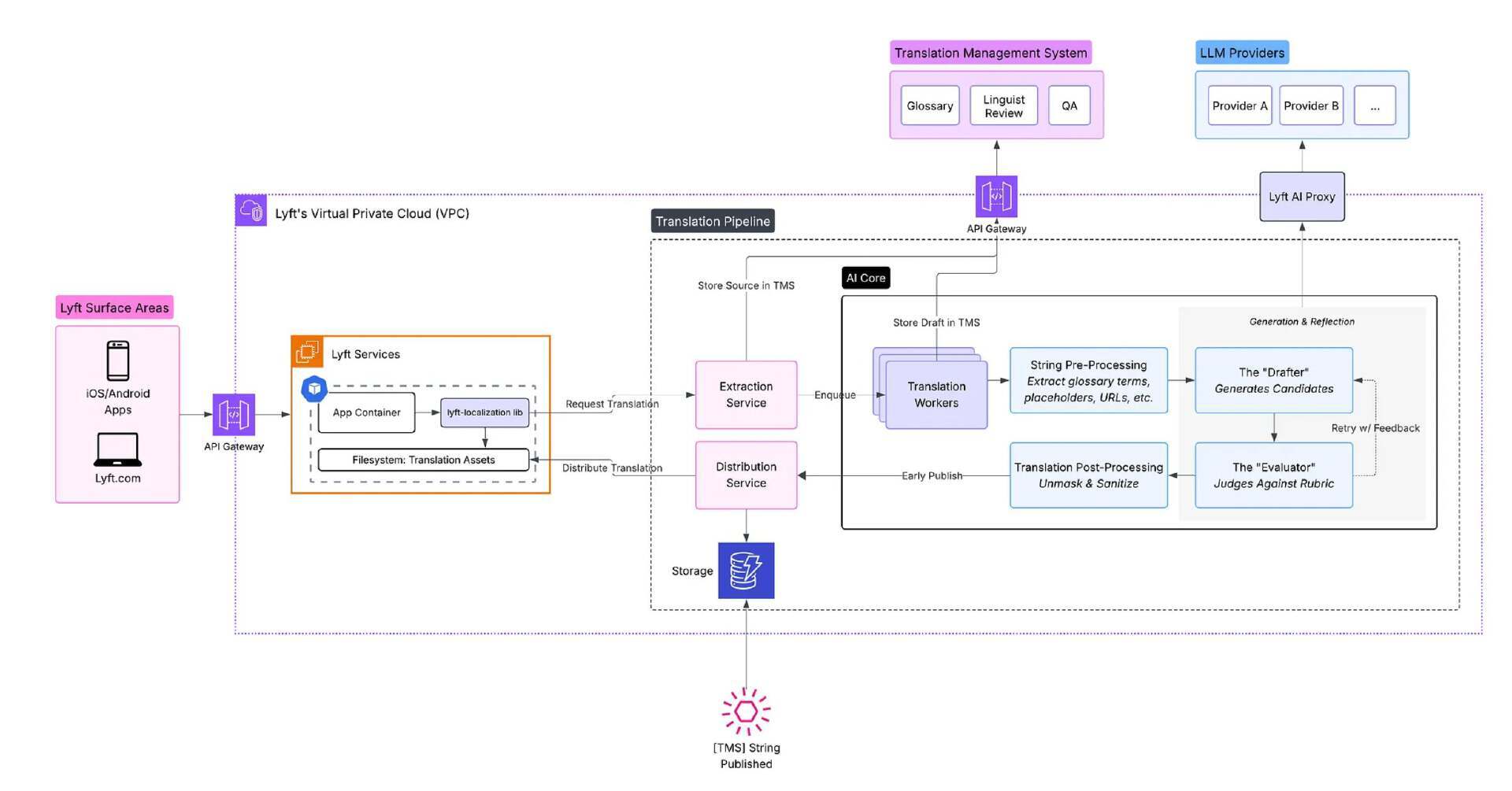
批量翻译流水线的组件(来源:Lyft博客文章)
Lyft 的工程师表示,该系统已将大部分内容的翻译周期从数天缩短至分钟级,提升了各语言版本的发布效率。该架构还支持提示词分批上线,可在小批量测试新的 AI 翻译策略后再全面部署,从而保证生产环境的稳定性。
像行程聊天消息这样的实时翻译采用另一套专注于低延迟的架构。批量翻译可依托更丰富的上下文信息与迭代评估,而实时翻译模型则优先保证用户即时反馈。
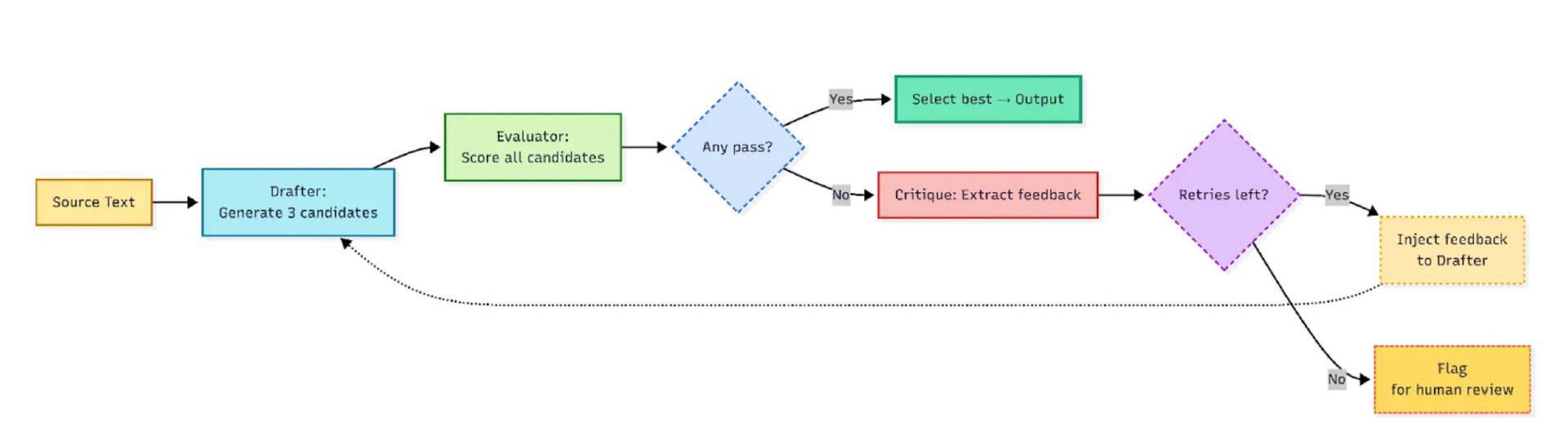
迭代式本地化工作流程(来源:Lyft的博客文章)
Lyft 的本地化系统将 AI 融入批量与实时翻译流程。大语言模型负责首轮翻译,减轻人工审核人员工作量;审核人员对结果进行校验,确保准确性、风格合规与文化适配。系统持续采集翻译质量、模型表现、审核一致性等指标,用于模型调优与后续翻译的优化。
约 95%的译文经人工审核后仅需少量修改即可上线。剩余 5%为复杂场景,如地区习惯用语、法律声明、品牌专属用语等,必须依靠人工把控以确保准确性和一致性。通过对这些结果的追踪,Lyft 能够量化翻译质量、优化 AI 模型,并在多语言环境下维持稳定可靠的生产级译文。
查看英文原文:Lyft Scales Global Localization Using AI and Human-in-the-Loop Review




