
尽管众多机器学习团队已竭尽全力,但由于工具链的割裂——这常常导致数据与机器学习管道碎片化及基础设施管理复杂化——大多数模型仍无法投入生产环境。Snowflake 始终致力于帮助客户更轻松快速地将先进模型投入生产。2024 年,我们推出了超过 200 项人工智能功能,其中包括 Snowflake ML 中涵盖机器学习模型开发、推理及运维全流程的端到端机器学习功能套件。我们非常高兴今年能延续这一势头,正式宣布以下基于 GPU 的机器学习工作流能力已全面开放用于生产负载:
● 开发侧:基于容器运行时的 Snowflake Notebooks(现于 AWS 全面可用,Azure 公开预览版)优化了数据加载流程,可在完全托管的容器环境中(该环境运行于 Snowflake 安全边界内并支持对数据的即时安全访问)实现多 CPU 或 GPU 分布式模型训练与超参数调优。Snowflake ML 现新增合成数据生成与使用功能(当前为公开预览版);
● 推理侧:Snowpark 容器服务中的模型服务功能(现于 AWS 和 Azure 全面可用)为任意模型(无论其训练环境如何)提供基于 CPU 或 GPU 的高效分布式推理能力;
● 监控侧:ML 可观测性功能(现全区域全面可用)提供内置工具,用于对在 Snowflake 中运行或存储推理结果的模型进行性能指标监控(如性能表现与漂移现象)并设置告警机制;
● 治理侧:ML 对象与工作流现已全面集成 Snowflake Horizon 的治理能力,包括已全面可用的数据与机器学习血缘追溯功能。
2024 年 11 月至 2025 年 1 月期间,每周有超过 4,000 家客户使用 Snowflake 的 AI 能力。其中客户包括加拿大大型顾客忠诚计划 Scene+,该企业采用 Snowflake ML 来简化和优化其机器学习工作流。

图 1 Snowflake ML 客户构建示例精选
研发实践
在开发方面,基于容器运行时(Container Runtime)的 Snowflake Notebooks 专为大规模机器学习开发而设计,无需任何基础设施管理或配置,即具备卓越的训练性能。
通过使用 Snowflake Notebooks 容器运行时的默认开箱即用设置进行训练,我们的基准测试显示:针对表格数据,Snowflake 上的分布式 XGBoost 训练速度比托管式 Spark 解决方案快 2 倍。借助 Snowflake ML,数据科学家和机器学习工程师可大幅减少在基础设施与扩展性上的投入,从而将更多时间用于开发和优化机器学习模型,并快速实现业务影响。
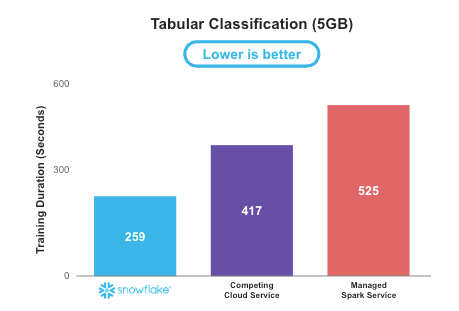
图 2 基准测试显示,在 5GB 表格数据集上,通过容器运行时(Container Runtime)的 Snowflake Notebooks 进行机器学习训练,相比托管 Spark 速度提升 2 倍(数值越低代表性能越优)
容器运行时通过以下特性,仅需数次点击即可抽象化基础设施管理并加速机器学习训练:
● 提供简洁的笔记本计算池配置选项,数据科学家可根据训练任务需求选择 CPU 或 GPU 计算池。所有客户账户自动预置了默认 CPU 与 GPU 计算池权限,这些计算池仅在笔记本会话激活期间运行,闲置时自动挂起。详见文档说明;
● 配备专为 CPU 和 GPU 优化的预集成镜像,预装支持机器学习开发的最新主流库与框架(包括 PyTorch、XGBoost、LightGBM、scikit-learn 等),数据科学家可快速启动 Snowflake Notebook 并立即投入工作;
● 通过 pip 安全访问开源仓库,并支持从 Hugging Face 等模型中心引入任意模型(参见示例);
● 提供优化的数据接入 API,支持将 Snowflake 表高效物化为 pandas 或 PyTorch DataFrame。通过多 CPU/GPU 并行处理,实现数据高效并行接入并以 DataFrame 形式呈现在笔记本中。详见技术文档;
● 提供分布式模型训练与分布式超参数优化 API,这些接口延展了 XGBoost、LightGBM 和 PyTorch 等开源框架的常用功能,可将处理任务分布式部署至多 CPU/GPU 环境,无需用户协调底层基础设施。
许多企业已在利用容器运行时(Container Runtime),以经济高效的方式构建先进的机器学习应用案例,并轻松调用 GPU 资源。客户包括 CHG Healthcare、是德科技(Keysight Technologies)和艾维途(Avios)。
CHG Healthcare
作为拥有 45 年行业经验的医疗人力调配企业,CHG Healthcare 借助人工智能/机器学习技术,为其覆盖 70 万名医疗从业者、涵盖 130 个医疗专业的劳动力调配解决方案提供支持。CHG 在 Snowflake ML 中构建并实现了端到端机器学习模型的量产化。
“事实证明,通过 Snowflake Notebooks 在容器运行时中使用 GPU,是我们满足机器学习需求最具成本效益的解决方案,”CHG Healthcare 的数据科学家 Andrew Christensen 表示。“我们非常认可 Snowflake ML 能够利用 Snowflake 的并行处理能力,它能兼容任何开源库,这为我们的工作流程提供了灵活性并提升了效率。”
是德科技(Keysight Technologies)
是德科技是电子设计与测试解决方案的领先供应商。公司全球收入超过 55 亿美元,客户遍及 13 个行业、超过 33,000 家,并持有 3,800 多项专利创新。是德科技利用 Snowflake ML 中的容器运行时构建了可扩展的销售与预测模型。
“在试用 Snowflake Notebooks on Container Runtime 后,我们可以说这一体验非常出色,”是德科技 IT 全球应用分析与自动化部门负责人 Krishna Moleyar 表示。“灵活的容器基础设施支持 CPU 和 GPU 的分布式处理,优化的数据加载以及与 [Snowflake] 模型注册表的无缝集成,显著提升了我们的工作流程效率。”
Avios
Avios 作为旅游奖励领域的领导者,拥有超过 4000 万会员和 1500 家合作伙伴,现采用容器运行时上的 Snowflake Notebooks 执行深度分析与数据任务,以满足业务所需的灵活性。
"容器运行时上的 Snowflake Notebooks 提供的灵活性和速度令我非常满意,"Avios 数据科学家 Olivia Brooker 表示,"我现在可以运行代码而无需担心超时或变量丢失问题。通过启用 PyPI 集成,还能使用更广泛的 Python 包,使我的分析和数据科学任务更具灵活性。"
为在构建模型时保护敏感数据集的隐私,或便捷生成新数据以增强训练效果,Snowflake 还支持简单且安全的合成数据生成功能(目前处于公开预览阶段)。这一强大能力使数据科学家能够在既不泄露敏感属性、也无需经历冗长繁琐审批流程的情况下,基于数据构建管道和模型。合成数据集保持与源数据集相同的特征,包括列名称、数量与数据类型,行数相同或更少。
生产环境中的模型服务
无论模型在何处构建,Snowflake ML 都能通过内置的安全与治理机制,轻松实现生产级规模的推理并管理模型生命周期。模型在 Snowflake 模型注册库完成注册后,可通过 Snowpark 容器服务(SPCS)中的模型服务功能无缝部署,进行分布式推理。该能力支持推理工作负载利用 GPU 计算集群,运行大型模型(如 Hugging Face 嵌入模型或其他 Transformer 模型),并能使用来自开源或私有仓库的任何 Python 包。您还可以将模型部署至 REST API 端点,供应用程序调用模型推理功能,满足低延迟应用需求(在线端点功能目前处于公测阶段)。通过模型注册库与推理解决方案,用户现在可以轻松使用在 Snowflake 内部或外部训练的任意机器学习模型:既可选择内置模型类型,也可通过自定义模型 API 接入其他任何类型的模型(包括预处理与后处理流水线以及分区模型),根据工作负载需求,在虚拟仓库或 SPCS 中运行可扩展的分布式推理。
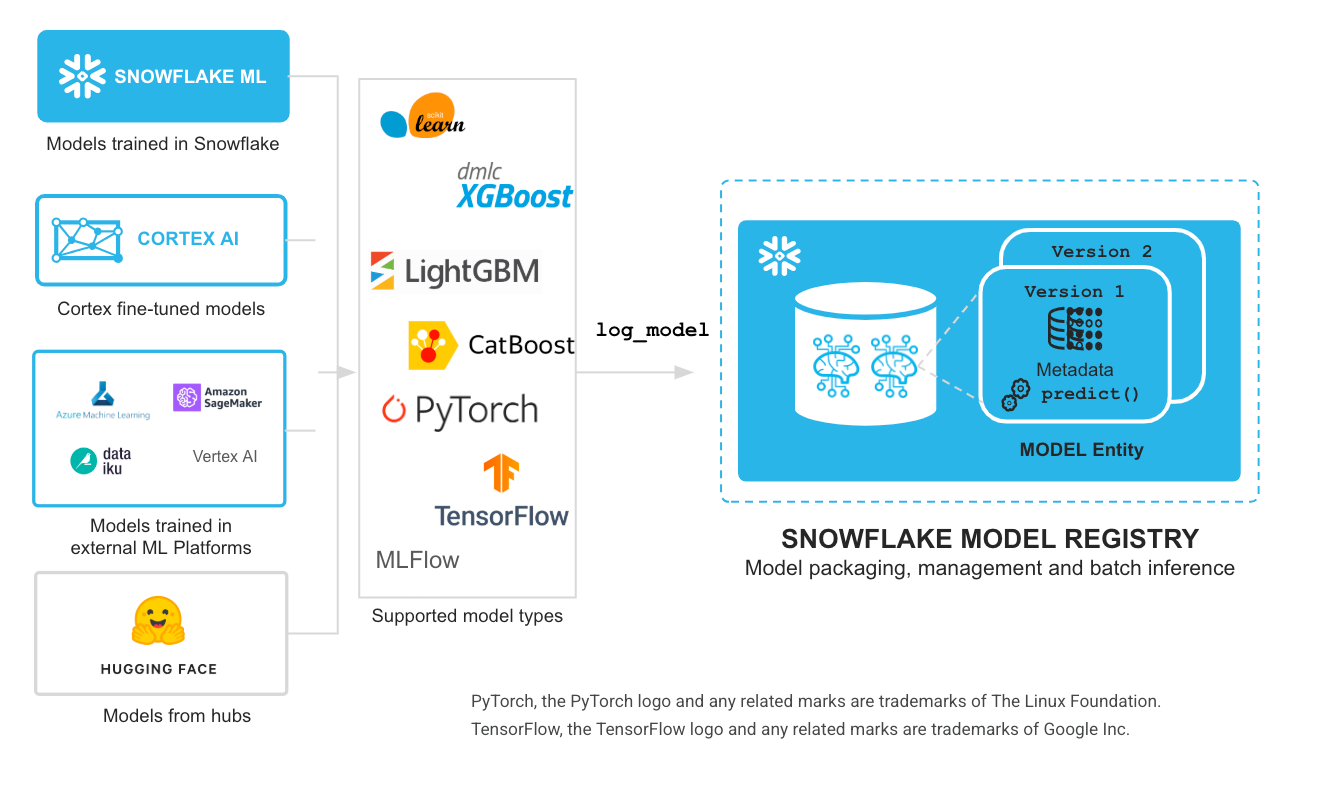
图 3 在 Snowflake 中实现任何模型的可扩展推理
沙特阿拉伯在线食品配送公司 Jahez Group 采用 SPCS 中的模型服务功能,将模型投入生产应用,以优化物流并确保订单在 30 分钟内送达客户,从而最大化客户满意度。
Jahez 集团高级数据工程师 Marwan AlShehri 表示:“Snowpark 容器服务中的模型服务极大助力了我们不同模型版本间的迭代周期,实现了快速更新并减少部署延迟。凭借对自动扩缩容能力的支持,模型生产化变得前所未有的简便。Snowflake 团队的卓越支持帮助我们实现了预估送达时间用例中亚秒级在线推理,以满足实时预测需求。这优化了骑手订单分配和配送流程,从而帮助我们降低成本并提升效率。”
监控与告警
在生产环境中,由于训练数据对现实世界的认知不完整、输入数据漂移以及数据质量问题,模型行为可能随时间发生变化。数据或环境的变化会对模型质量产生重大影响。
Snowflake 的机器学习可观测性功能支持对模型性能、模型分数漂移及特征值漂移进行监测,其前提是将推理/预测日志存储在 Snowflake 表中——无论模型在何处训练或部署。用户可通过 Python 或 SQL API 查询监测结果,并在与模型注册表关联的 UI 界面中查看监测数据,同时支持根据自定义阈值便捷设置告警。
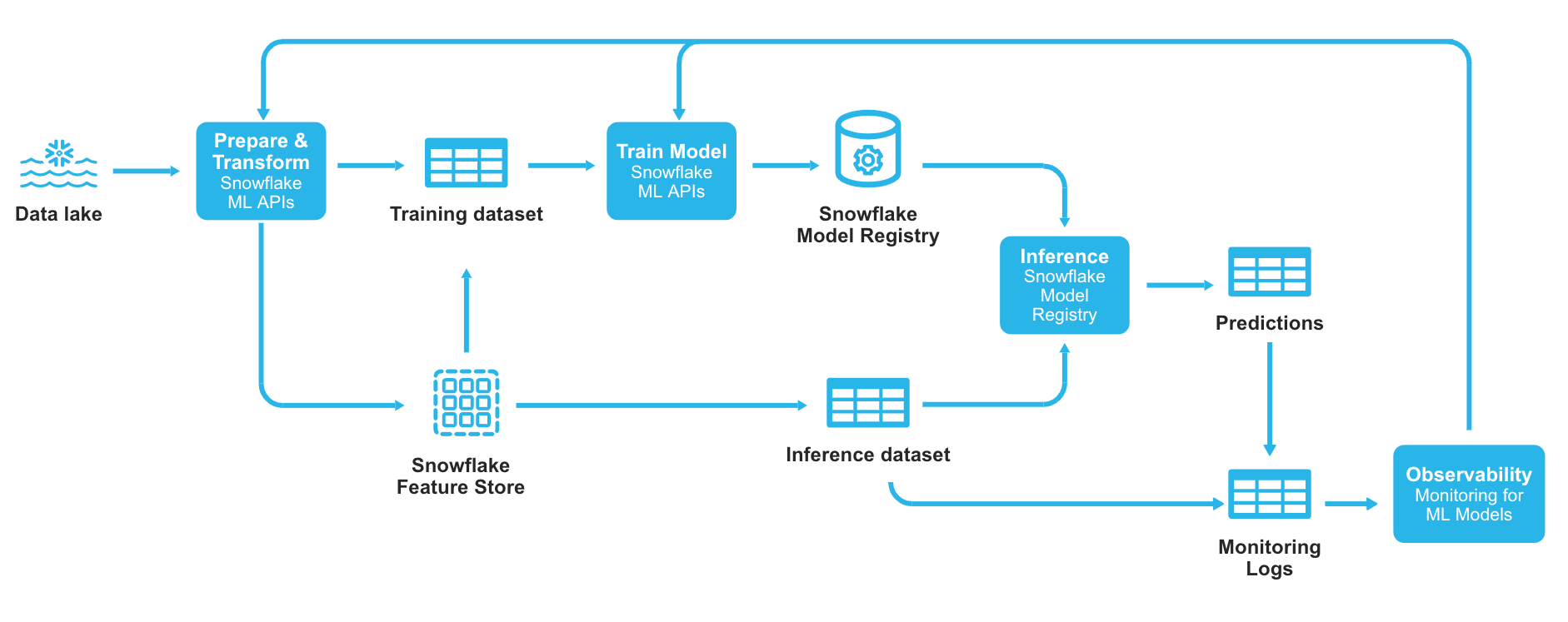
图 4 Snowflake ML 中集成了可观测性的端到端机器学习工作流
目前, 欧洲个性化照片产品与礼品行业领导者 Storio Group 为超过 1,100 万客户提供产品服务,现正利用 Snowflake 平台中的 MLOps 功能(包括机器学习可观测性)实现模型生产化。
Storio 集团高级机器学习工程师 Dennis Verheijden 表示:"在 Storio,我们仅用数月时间就在 Snowflake ML 平台上构建了一个可用、可扩展且治理完善的 MLOps 平台,从概念验证到生产部署全程落地。通过将全新的机器学习可观测性功能与 Snowflake 既有功能(如动态表和机器学习血缘追踪)相结合,我们成功实现了平台训练模型的自动化可观测性。其成果是:每个部署的模型都会自动生成监控看板,实时展示模型评估结果、版本对比以及特征随时间推移的漂移情况。这使得数据科学家能够专注于价值挖掘,而将可观测性与监控的实现工作交由平台自动处理。"
底层治理
Snowflake ML 的核心基础是与 Snowflake Horizon Catalog 的全面集成——该内置数据治理与发现解决方案集成了合规性、安全性、隐私保护及协作能力。Snowflake 中的所有数据、特征和模型均通过跨云的基于角色的访问控制(RBAC)进行治理,使企业能够大规模管理访问权限,将机密信息限制在适当的业务角色内。Snowflake 模型管理基于这一坚实的数据治理基础,为生产环境中的模型生命周期管理提供灵活且安全的方式。
为追踪机器学习数据和产物的完整血缘关系、访问历史及日志,Snowflake 的数据与机器学习血缘功能可轻松可视化数据从源到终点的流动过程。该血缘图全面支持 Snowflake 中创建的所有机器学习对象(特征、数据集和模型),实现机器学习流水线的全链路可追溯性,有助于满足合规审计要求,并提升机器学习工作负载的可复现性与稳健性。
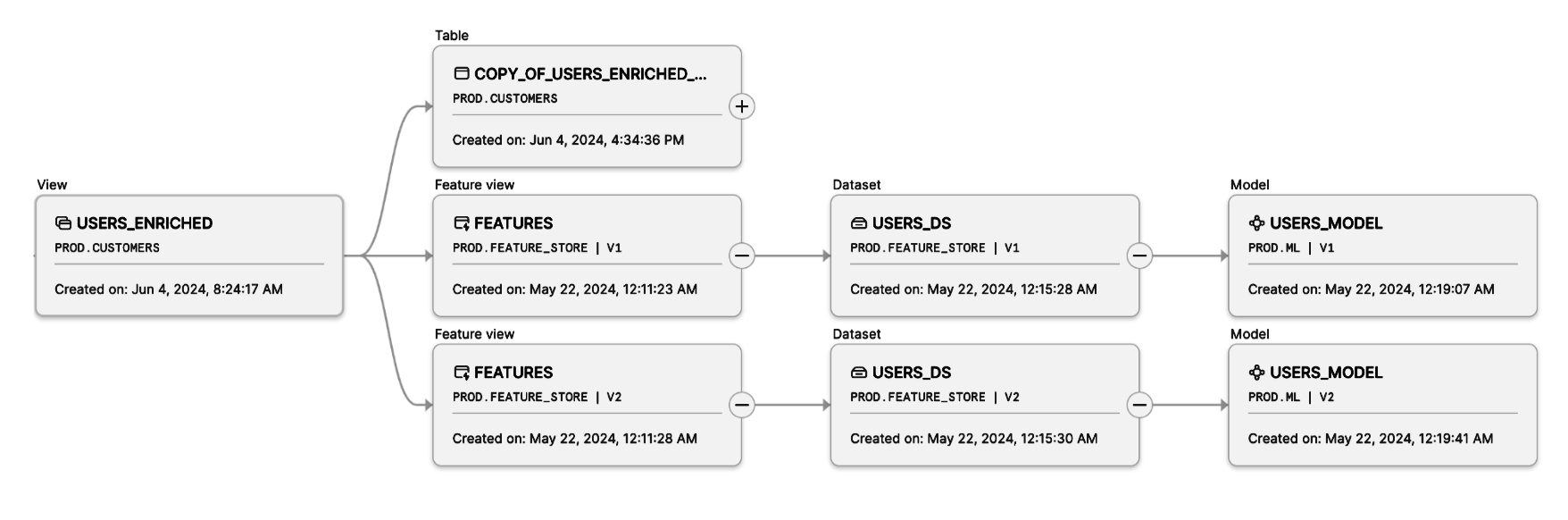
图 5 Snowsight 用户界面中的机器学习资产沿袭功能,可实现轻松复现、调试与审计
入门指南
随着这些最新功能的正式发布,数据科学家和机器学习工程师现可放心地在 Snowflake ML 中规模化部署生产环境工作流。
以下资源是快速上手新功能的最佳途径:
● 开发侧:通过容器运行时入门速成教程创建笔记本并构建简单机器学习模型,配合初学者视频同步学习;
● 推理侧:使用嵌入生成示例入门,并观看配套视频概述;
● 监控侧:根据机器学习可观测性入门速成教程实践,并观看专家演示视频。
针对更多高级应用场景,请参考以下解决方案:
● 使用 Snowflake 笔记本基于 GPU 训练 XGboost 模型;
● 在 Snowflake ML 中基于分布式 Pytorch 构建推荐模型;
● 使用 Snowflake ML 的分布式 Pytorch 实现缺陷检测。
原文地址:




