
作者 |韩钦亭,Freewheel lead engineer
引 言
在软件开发中,性能优化一直是开发者面临的核心挑战之一。尽管传统的 Profiling 工具如火焰图、调用栈分析等能帮助开发者定位性能瓶颈,但如何快速理解报告并制定优化策略仍高度依赖个人经验。
为此,我们在已有 Profiling 平台的基础上,引入了 AI 智能辅助模块,帮助开发者快速分析结果并获取针对性的性能优化建议。
本文将分享该功能的设计思路、工程实现与应用成效,并探讨 AI 在性能优化场景下的未来潜力。
背景与挑战
2.1 既有 Profiling 平台回顾
在上篇文章《快速定位线上性能问题:Profiling 在微服务应用下的落地实践》中,我们已经构建了完整的性能分析体系:
支持 CPU、Heap、Goroutine 等多维度分析;
集成火焰图等可视化工具;
实现了自动化报告生成和归档。
该平台在高并发保障、发布回归验证等场景中发挥了重要作用,并积累了大量实践经验。
2.2 面临的主要痛点
尽管已有完善的 Profiling 基础设施,但在实际使用过程中,我们观察到以下共性问题:
报告复杂,解读门槛高 火焰图和调用栈信息密度大,依赖开发者对系统架构和运行时的深刻理解;
优化策略依赖个人经验 目前从报告到优化决策的过程,仍然严重依赖开发者个人的判断力与过往经验,缺乏统一、标准化的优化指导;
难以形成知识沉淀 优化过程碎片化,缺乏知识体系支撑,难以在团队中有效传承。
2.3 新需求的提出
随着大语言模型(LLM)在软件工程、代码生成等领域的持续深入,我们也在积极探索:是否可以借助 LLM 降低性能调优的门槛?尤其针对上述性能优化过程中的共性痛点,LLM 正好具备天然优势 —— 它擅长理解复杂上下文、归纳经验模式、生成结构化建议,这与我们在优化过程中所面临的瓶颈高度契合。
因此,我们提出了一个新的功能设想:
在现有 Profiling 平台中新增 AI 辅助模块,允许开发者提交代码片段,并结合 Profiling 报告,一键发送给 AI 模型,由 AI 自动生成可执行的性能优化建议,极大缩短分析与决策路径。
架构设计与实现
为了将「基于 AI 的智能性能优化建议」这一设想落地,我们在现有的 Profiling 平台基础上进行了功能扩展,围绕两个核心目标展开设计:
让 AI 结合业务代码理解 profiling 报告
让 AI 生成可执行的优化建议
最终,我们形成了一套简洁直观的交互方式和稳定可扩展的技术实现。
3.1 架构设计: 从 Profiling 到 AI 建议 的闭环
为了最大程度上贴合开发者的使用习惯,我们设计了最小可闭环的性能分析流程,涵盖从数据采集到优化建议生成的全链路能力,具体包括以下几个阶段:
数据输入
采集运行时 profiling 报告
关联热点函数与源代码片段
智能分析准备
自动转换二进制 pprof 为 AI 可读文本
动态构建分析 Prompt(含性能指标 + 代码上下文)
获取报告解读及优化建议
函数级优化(如内存预分配);
系统级建议(如并发策略调整);
趋势预测 (如优化效果预估)
报告解读:函数耗时分析等;
优化建议:
整体架构图如下:

3.2 交互流程: 开发者视角的优化之旅
具体的交互流程如下
执行 Profiling 分析:在已有的 Profiling 平台对特定服务执行 pprof 分析;
导出 Profiling 报告:分析完成后,可以一键导出 .txt 格式报告。限于合规性的要求,我们没有在已有 Profiling 平台直接提供 AI 的能力介入,而是提供了一个链接可直接跳转至 AI 分析平台;下图展示了报告导出与平台跳转的界面:
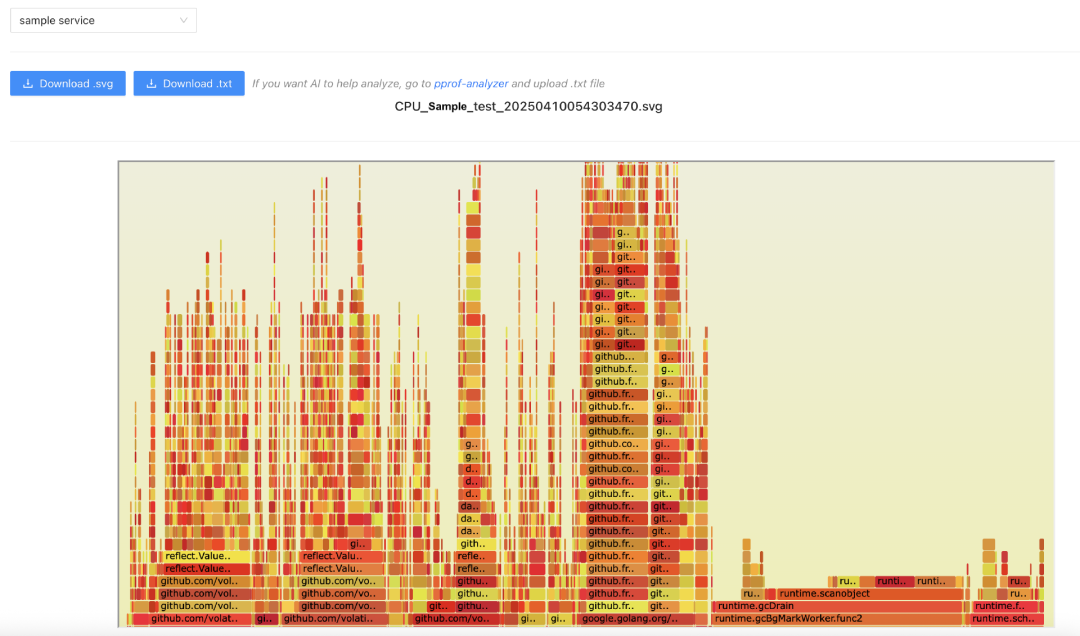
上传 Profiling 报告与代码片段:在我们自研的 AI 分析平台 Web 端,用户可上传 Profiling 报告并粘贴函数代码;
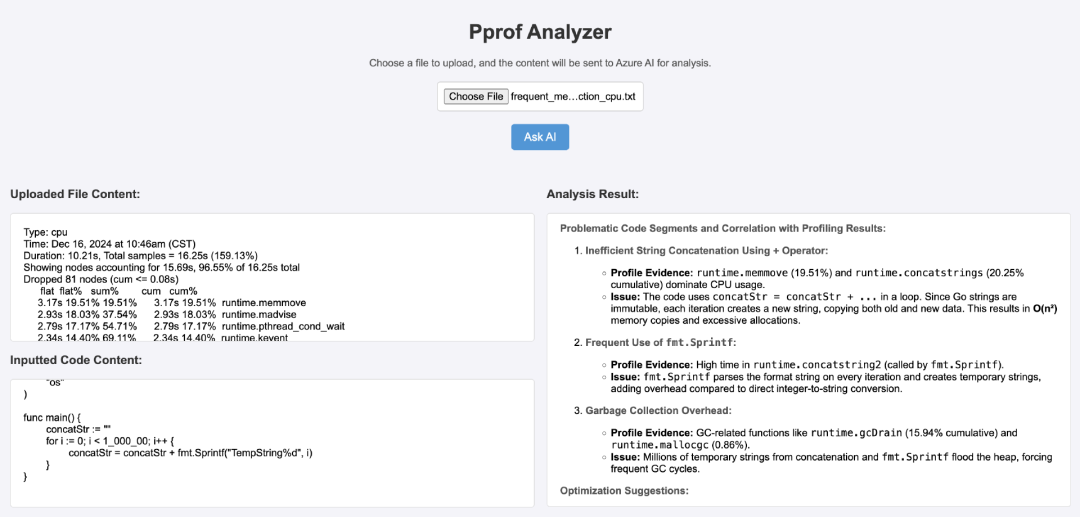
点击 Ask AI:平台将调用后端大模型服务进行性能分析,并在 Web 页面中返回报告解读与优化建议。
下图展示了该自研平台的上传与分析界面:
3.3 关键技术实现
3.3.1 数据适配层
传统的 profiling 数据(如 .pb.gz 的 pprof 文件)是二进制结构,AI 模型(尤其是大型语言模型)无法直接解析这些格式。为支持 AI 分析,我们需要对其转换为更适配的文本格式。
下表对常见 profiling 数据格式的可读性和 AI 适配性进行了对比:
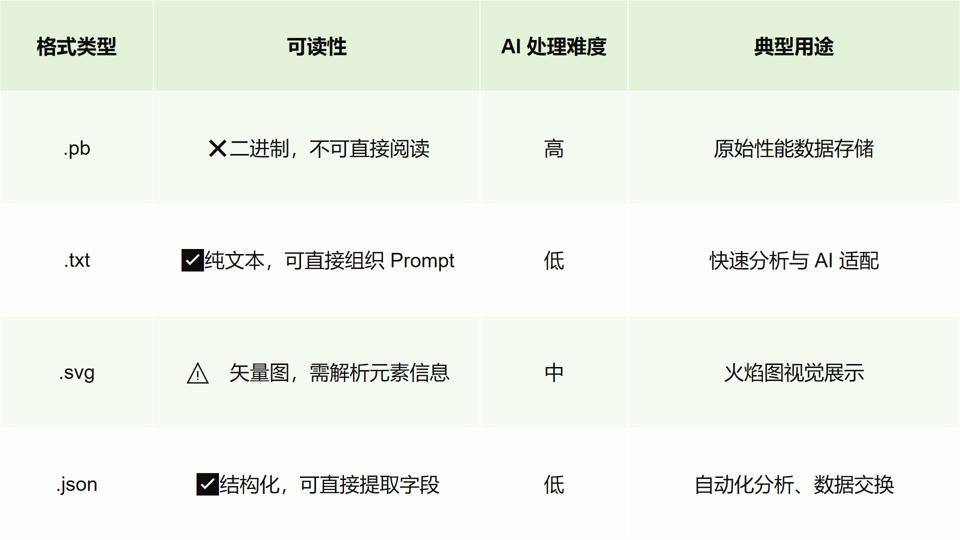
我们最终选择.txt 格式,在可读性、解析效率之间取得平衡。可以直接通过 go 语言提供的命令完成转换
go tool pprof -text <profile_data.pb.gz> > profiling.txt.txt 文件中包含以下关键信息:
热点函数:报告中的热点函数及其执行时间占比;
资源占比:不同模块或函数对 CPU 资源的使用比例。
示例片段如下所示:
flat flat% sum% cum cum% 50ms 6.41% 6.41% 50ms 6.41% internal/runtime/syscall.Syscall6 30ms 3.85% 10.26% 130ms 16.67% runtime.scanobject 20ms 2.56% 30.77% 100ms 12.82% runtime.mallocgc转换后的文本数据将通过以下 AI 交互流程生成优化建议
3.3.2 AI 交互层
在完成 profiling 数据的标准化转化后,我们进一步构建了 AI 交互层,将性能数据与代码上下文结合,通过 Prompt 工程驱动大语言模型,从而实现
性能瓶颈精准定位 - 将文本性能指标与上下文代码关联
性能优化建议生成 - 输出符合工程实践的优化方案
Prompt 结构设计
为了引导模型完成上述任务,我们设计了一套结构化的 Prompt 模版,确保输入上下文和输出结果的准确性、完整性与可控性。
动态上下文注入
当仅提供 profiling 报告时,AI 能够进行客观分析、识别关键性能瓶颈;
当额外提供源代码时,系统会自动追加代码上下文,并引导模型进一步结合代码结构,生成更具可操作性的优化建议。
输出规范化
为确保分析结果具备清晰的结构和可执行性,模型输出应满足以下四点规范:
识别问题代码段:根据 profiling 报告和代码片段,标明具体的性能瓶颈代码部分。
关联性能问题与 profiling 结果:将每个性能问题与 profiling 数据对应,标明函数名称和时间占比等关键指标。
提供优化建议:针对识别到的瓶颈,提供可执行的优化建议,并简要解释原因。
提供优化代码片段:如果可能,给出优化后的代码示例,并简要说明该优化会如何提高性能。
以下为实际构造的 Prompt 示例,用于提交至 AI 模型进行分析:
def build_prompt(pprof_content, code_snippet): messages = [ { "role": "system", "content": "You are a professional Go performance optimization expert skilled in analyzing pprof data to identify bottlenecks and provide actionable solutions." }, { "role": "user", "content": f""" Please help me analyze the following Go program's CPU profiling report and identify the performance bottlenecks. Below is the CPU profiling data generated by the go tool pprof: {pprof_content} """ } ] if code_snippet: messages.append({ "role": "user", "content": f""" **Here is the Go program code.** Please do the following: - Identify the problematic code segments based on the profiling report and code snippet. - Clearly correlate each performance issue with the profiling result (e.g., function name, time percentage). - Provide optimization suggestions with explanations. - If possible, show an optimized code snippet with a brief explanation of why it improves performance. **Code:** ```go {code_snippet} """ })return messages3.3.3 安全性与部署策略
为了确保数据安全与平台合规,我们采用以下架构:
客户端导出数据:用户下载 Profiling 报告至本地,数据仅用于后续在分析工具 Web 端上传;
分析工具 Web 端:部署仅内网可访问的静态页面,不接入公司生产环境,仅提供上传与展示能力;
后端 AI 分析服务:运行于非生产环境,通过 REST API 提供分析建议;
数据不上云、不入库:代码片段和生成优化建议不做持久化存储也不会上传至云端。
3.4 模型选型与评估
3.4.1 模型选择决策
在针对大规模性能诊断与代码优化场景选型时,我们重点参考了以下几个维度来评估大语言模型的实际能力与适用性:
性能报告解读能力:能否从 Profile 报告中准确识别出关键性能瓶颈(如 GC 开销、并发争用等),并结合资源耗时等信息做出判断。
代码上下文理解能力:模型是否具备将报告内容与源代码逻辑建立关联的能力,包括能否指出具体函数或调用路径中存在的问题。
优化建议的实用性:模型给出的建议是否具备工程可执行性,例如是否提出具体的限并发策略、数据结构调整等。
响应效率与使用成本:包括每次调用所需的时间与 Token 成本,是否支持高频运行,以及整体性价比。
3.4.2 模型能力对比分析
我们使用一段真实的 Go 代码及其对应的性能数据,选取 OpenAI-O1,DeepSeek R1、Claude 3.7 Sonnet 对数据样本进行评估。
性能数据摘要
flat flat% sum% cum cum% 1.50s 13.33% 13.33% 1.50s 13.33% runtime/internal/syscall.Syscall6 0.44s 3.91% 17.24% 1.54s 13.69% runtime.mallocgc 0.41s 3.64% 24.71% 1.01s 8.98% runtime.scanobject 0.18s 1.60% 29.87% 0.43s 3.82% runtime.mapassign_faststr 0.07s 0.62% 49.16% 1.38s 12.27% runtime.gcDrain 0.02s 0.18% 60.98% 1.10s 9.78% example.com/bio.(*SubItemBIO).setSubItemBasicInfo 0.01s 0.089% 63.11% 1.59s 14.13% database/sql.(*DB).queryDC 0.01s 0.089% 63.56% 1.07s 9.51% database/sql.withLock 0 0% 67.47% 1.62s 14.40% database/sql.(*DB).QueryContext 0 0% 67.47% 1.62s 14.40% database/sql.(*DB).query 0 0% 67.47% 0.69s 6.13% example.com/bio.(*SubItemBIO).getSubItemAlertInfos 0 0% 67.47% 0.65s 5.78% example.com/bio.(*SubItemBIO).getSubItemAlertInfos.func1相关代码节选
func (o *SubItemBIO) setSubItemBasicInfo(records ...){ subItems := make([]*SubItem, 0) for _, subItem := range records { alertInfos, err := o.getSubItemAlertInfos(subItem) if err != nil { return nil, err } subItem.AlertInfos = alertInfos subItems = append(subItems, modelToSubItem(subItem)) } ...}func (o *SubItemBIO) getSubItemAlertInfos(subItem) { result := make(map[string]string) getAlertInfos := func(subItemID, subItem.ProductID, subItem.VariantID int64, alertType string) error { luAlertInfoQuery := NewQueryBuilder().Build() // fetch lu alert info luAlertInfos, err := o.LuAlertInfoApi.FindAll(ctx, luAlertInfoQuery) luAlertInfoIds := getLuAlertInfoIDs(luAlertInfos) entityID := getEntityID(subItem.ProductID, subItem.VariantID, alertType) alertInfoQuery := NewQueryBuilder(subItemID, luAlertInfoIds,entityID).Build() // fetch alerts alerts, err := o.AlertInfoApi.FindAll(ctx, alertInfoQuery) luAlertIDToName := getLuAlertIDToName(luAlertInfos) for _, alert := range alerts { alertName := luAlertIDToName[alert.LuAlertID] result[alertName] = alert } } // Prduct alert infos if err := getAlertInfos(subItemID, subItem.ProductID, subItem.VariantID, "Product"); err != nil { ... } // Variant alert infos if err := getAlertInfos(subItemID, subItem.ProductID, subItem.VariantID, "Variant"); err != nil { ... }}3.4.2.1 OpenAI O1 示例输出

3.4.2.2 DeepSeek R1 示例输出
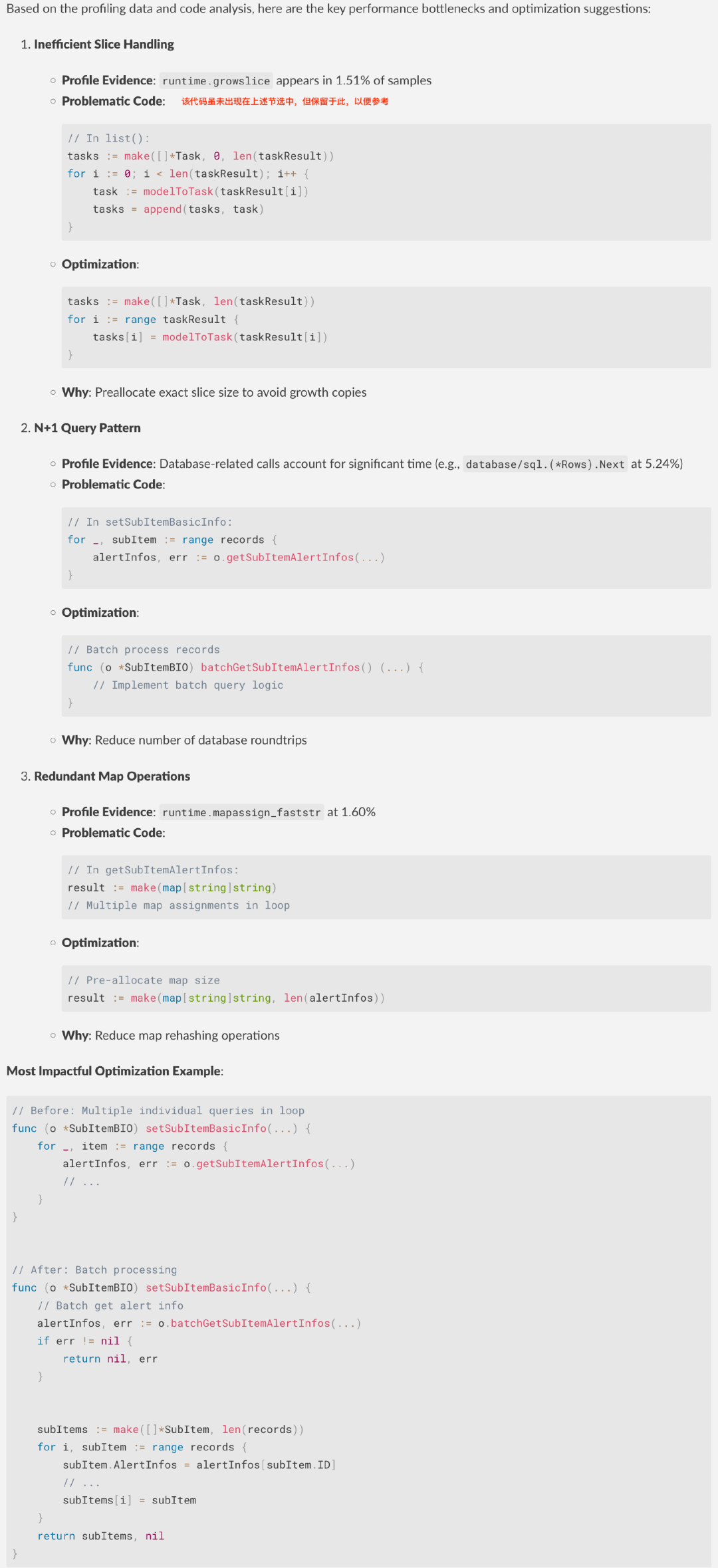
3.4.2.3 Claude 3.7 Sonnet 示例输出
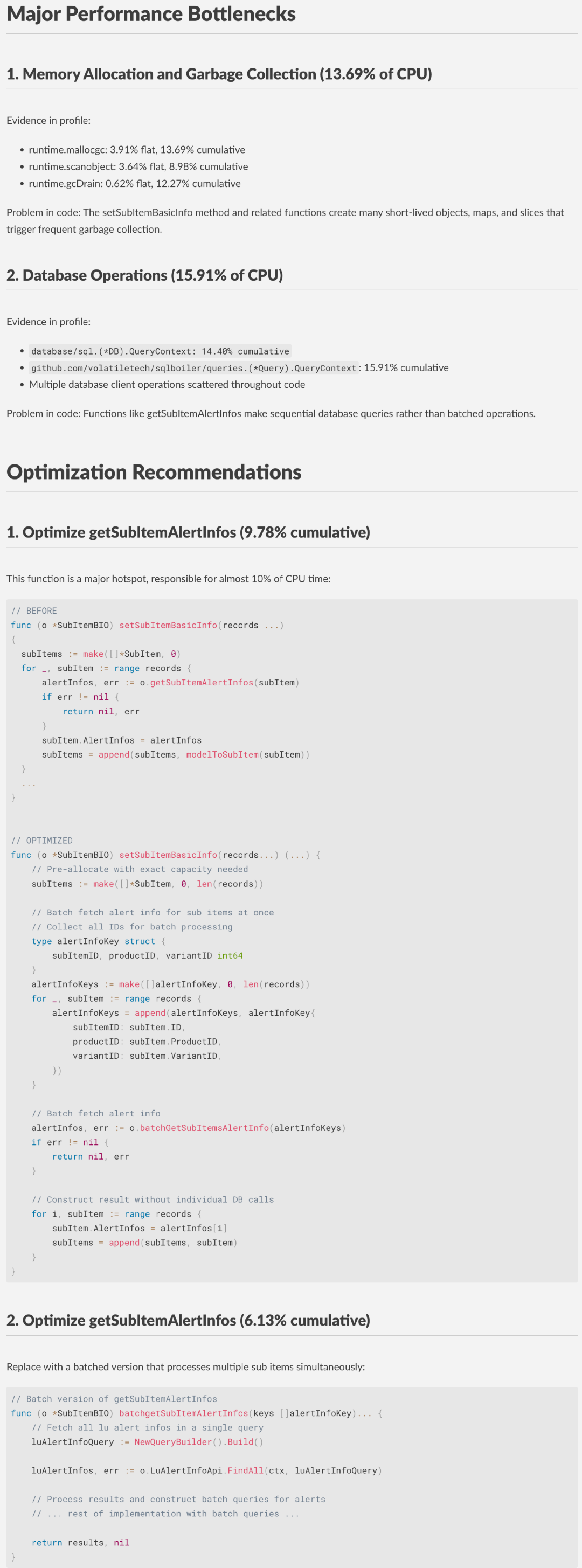
3.4.3 模型对比总结 ( 以 ~20K token 输入为例 )
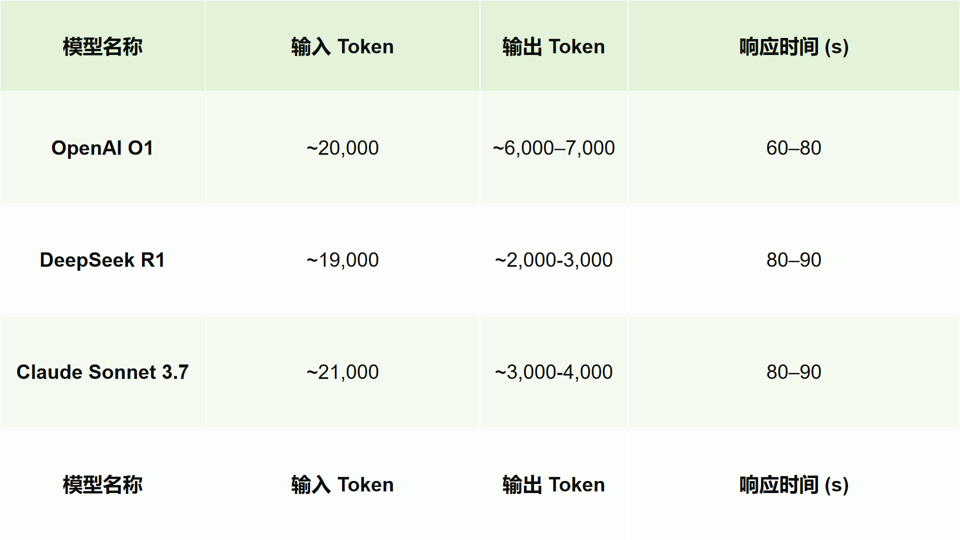
总体来看,三款模型在性能报告解读以及代码诊断方面均具备较高准确性,建议可执行,但通常需运行 2-3 次才能获得完整分析。其中 DeepSeek R1 的建议更精炼,适合有工程经验的开发者快速吸收。
使用场景推荐

此次模型评估基于代码分析与性能诊断场景展开,不同模型在输出丰富度、成本控制与建议质量上各有侧重。最终我们选择 DeepSeek-R1,主要出于在该场景下的性价比优势。但对于更需要上下文完整性的场景,OpenAI O1 与 Claude 3.7 依然具备优势,值得在多模型系统中灵活搭配使用。
实际案例:基于 AI 的 Service A/B 性能瓶颈定位与优化
4.1 场景描述
服务架构

Service A 的一个核心接口近期被发现存在性能瓶颈:
平均响应时间:约 2000ms
CPU 使用率峰值:可达 34%
该接口在日常小数据量访问场景中表现正常,P95 响应时间较低,未出现显著性能问题。但在处理个别大体量请求(如一次查询数千条记录)时,用户明显感受到响应延迟,P99 延迟指标显著偏高。因此,我们决定将其作为一次典型的优化实战案例。
为了定位问题,分别对上述两个服务进行了 CPU profiling,以下是 Service A 的 profiling 结果(节选):
flat flat% sum% cum cum% 50ms 6.41% 6.41% 50ms 6.41% internal/runtime/syscall.Syscall6 30ms 3.85% 10.26% 130ms 16.67% runtime.scanobject 20ms 2.56% 30.77% 100ms 12.82% runtime.mallocgc 10ms 1.28% 53.85% 300ms 38.46% example.com/internal/proto/client.(*subItemClient).ListByItemID 10ms 1.28% 79.49% 140ms 17.95% runtime.gcDrain 0 0% 100% 110ms 14.10% runtime.schedule对应的代码片段
// FetchOrderData 加载主订单数据并处理其下的任务结构func FetchOrderData(ctx context.Context, req RequestInput) error { data, _ := OrderService.GetByExternalID(ctx, req) return loadTasksConcurrently(ctx, data.ID)}// loadTasksConcurrently 并发加载所有任务及其下属条目func loadTasksConcurrently(ctx context.Context, orderID int64) error { tasks, _ := TaskService.ListByOrderID(ctx, orderID) for _, task := range tasks { go func(t Task) { loadItemsConcurrently(ctx, t.ID) }(task) } return nil}// loadItemsConcurrently 并发加载条目并处理其子项信息func loadItemsConcurrently(ctx context.Context, taskID int64) { items, _ := ItemService.ListByTaskID(ctx, taskID) for _, item := range items { go func(it Item) { _ = SubItemService.ListByItemID(ctx, it.ID) }(item) }}4.2 AI 视角下的性能问题剖析与建议
基于 Service A 的 profiling 数据与代码分析,DeepSeek 提出了如下优化方向:

对 Service B 的性能诊断与优化建议,详见第 3.4 节中的实测案例。
4.3 代码优化方案
下图汇总了 DeepSeek 对 Service A 和 Service B 的性能瓶颈与对应优化建议:
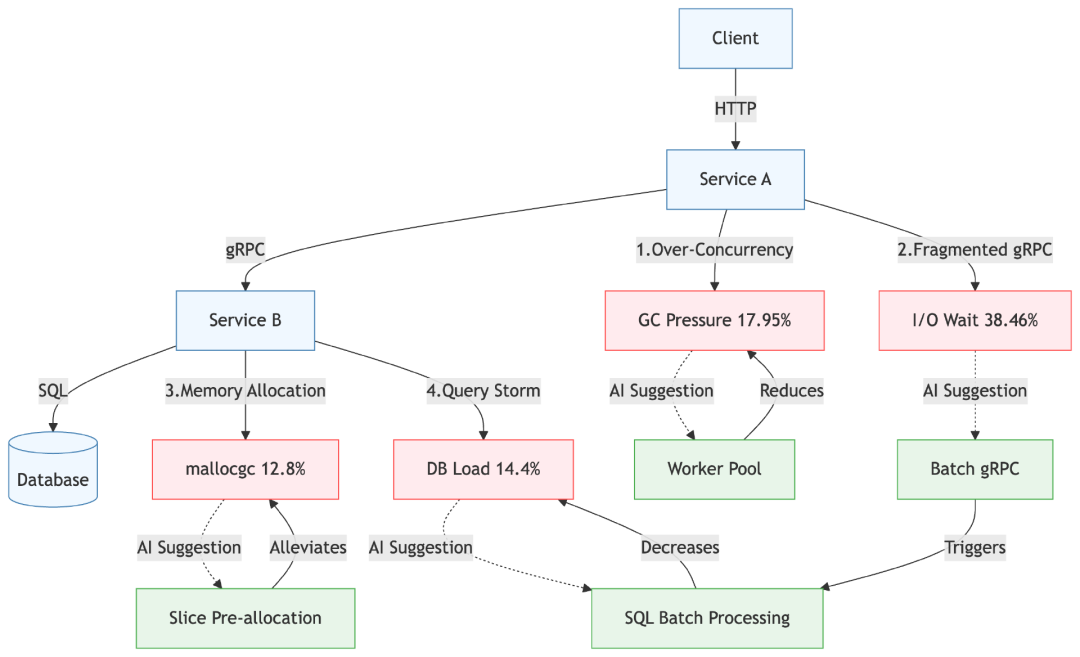
在实际落地过程中,我们并未机械套用 DeepSeek 的优化建议,而是结合自身业务场景和系统架构,进行了有针对性的系统性重构。我们借鉴其“批量查询与降低并发深度”的核心思想,在 Service B 中引入 Batch Query 机制,对存在层级结构的数据进行统一查询,从源头上避免了 Service A 针对每个子元素重复发起请求的结构性开销。
重构后的查询链路不仅显著减少了 goroutine 数量,还有效降低了 GC 与网络调度开销,整体响应性能得到大幅提升。虽然最终方案未完全沿用 AI 提供的代码路径,但其提出的方向性建议对优化策略的形成具有重要参考价值。这也印证了两个结论:
AI 在技术分析深度上已具备实际工程落地能力,能准确识别性能瓶颈,并给出具备可执行性的建议
但其在业务理解与结构设计层面仍存在不足,难以提出贴合实际场景的高层次重构思路
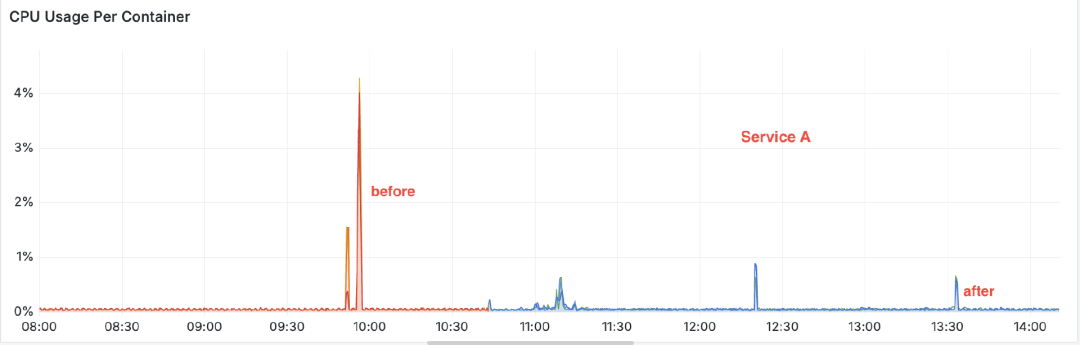
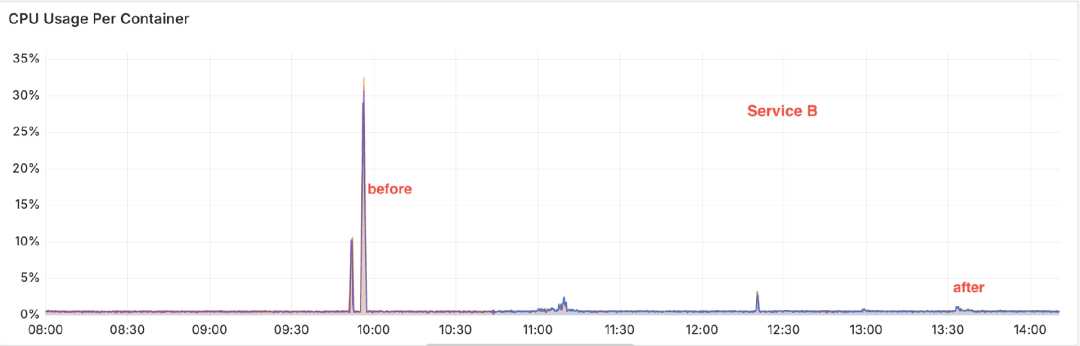
4.4 优化效果
接口的响应时间大幅下降
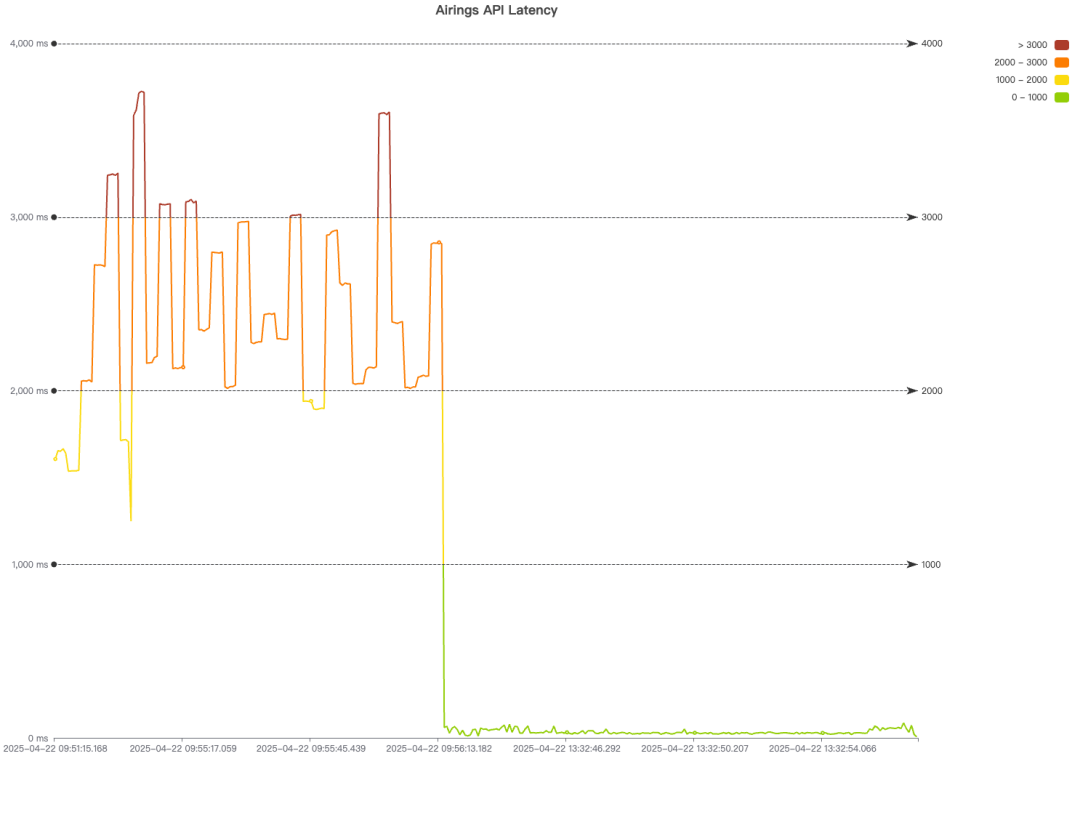
同时 CPU 的使用率大幅降低
未来展望:从辅助分析到自主优化
在本文撰写过程中,OpenAI 发布了 O3 模型,Anthropic 发布了 Claude 4,DeepSeek 也推出了 R1 v0528 升级版本。由于时间关系,我们暂未对这些新模型进行评估。但读者可以借鉴本文思路进行后续尝试和评估,并选择最契合自身需求的模型。
在实践中我们发现,AI 模型不仅可以解析复杂的 profiling 报告,还能结合代码上下文给出具体、可落地的优化建议。基于这一能力,我们正在推动 AI 从辅助分析走向自主优化,构建更智能的性能工程体系,未来重点将聚焦于以下几个方向:
扩展多语言能力,覆盖更广泛的技术栈
当前的分析能力主要集中在 Go 场景,下一步我们将扩展至 Java、C++ 等主流后端语言,逐步构建跨语言的性能分析和优化能力,以适配更广泛的后端系统环境。
引入业务语义与数据结构,增强 Prompt 表达力
性能瓶颈的本质往往与业务场景和数据结构紧密相关。我们将支持用户输入业务背景信息与数据库结构,结合 LLM 的上下文理解能力,构建更具语义相关性的 Prompt,从而生成更贴近实际的优化建议。
自动生成修复方案
借助代码补全与重构类 API,我们正在构建自动化修复能力,使模型不仅能指出性能瓶颈,还能“一键生成”优化后的代码片段,甚至直接发起 Pull Request,实现从“识别问题”到“解决问题”的闭环。




