
今天,火山引擎正式推出新一代模型:豆包大模型 1.8。该模型面向多模态 Agent 场景进行了深度优化:
更强 Agent 能力:Tool Use 能力、复杂指令遵循能力、OS Agent 能力都实现了大幅增强。
多模态理解升级:大幅提升了视觉理解的基础能力,可以低帧率理解超长视频。此外在视频运动理解、复杂空间理解、文档结构化解析能力上也都有所提升。
原生支持智能上下文管理:可以配置上下文压缩策略,当任务轮次过长时,模型会根据策略智能清除低价值的历史工具调用信息,确保多步骤任务稳定完成。
据介绍,豆包 1.8 上下文窗口达到了 256k,意味着它能同时承接较长篇幅的对话上下文,更好地连贯理解连续的信息。此外,该模型的最大输入 Token 长度为 224k、最大输出 Token 长度为 64k,同时它的最大思考内容 Token 长度也为 64k,这是它在内部处理信息、梳理逻辑时的容量上限。
运行效率方面,豆包 1.8 的 TPM(每分钟处理 Token 数)达到了 5000k,而 RPM(每分钟请求数)为 30k。
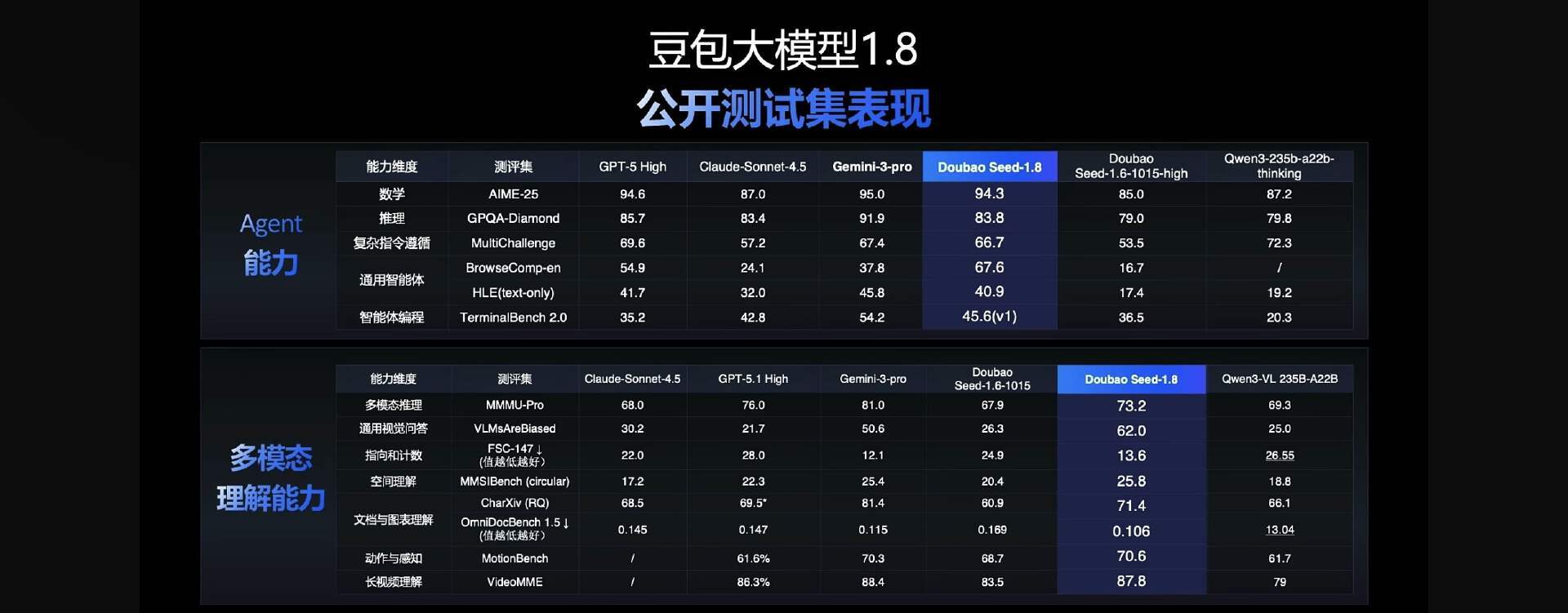
谭待表示,这些能力让豆包 1.8 在 AIME 2025 等 Agent 评测集上稳步提升,在通用智能体测评 Benchmark 上取得全球领先成绩;在多模态理解方面,于视觉判断准确性、空间理解、文档解析、视频运动识别等多项能力上超越 Gemini 3,在其他任务上也都处于全球第一梯队水平。
演示中,豆包 1.8 成功规划流程,调用十余个工具,在多个电商平台完成耳机的全网比价与最优选择。此能力可广泛应用于电商、生活服务及企业自动化流程。另外,面对一段 1 小时 4 分钟的监控视频,豆包 1.8 能快速低帧率浏览,精准定位事故画面,分析出肇事车辆与时间。该能力可拓展至在线教育、安全巡检、产品质检等领域。
谭待表示,豆包 1.8 的推出,将帮助企业更便捷地构建复杂 Agent,而更多、更智能的 Agent,必将为千行百业创造前所未有的价值。”
据悉,截至今年 12 月,豆包大模型的日均 tokens 调用量已突破 50 万亿,自发布以来实现了 417 倍增长;与去年 12 月相比,实现了超过 10 倍的增长。
“这不仅仅是豆包大模型的速度,更是整个 AI 行业加速发展的缩影。不断攀升的 tokens 调用量,也驱动着火山引擎的 AI 产品持续完善。”谭待表示。
在多模型方面,谭待表示,从理解到创造,豆包大模型同样拥有全球领先的图像与视频生成能力,覆盖了从图像创作与编辑、视频生成、数字人制作到 3D 模型生成的完整创作链条。无论是在线视频、短剧制作,还是智能终端交互、商品营销与产品设计,都在广泛使用豆包的 Seedream(生图) 和 Seedance(生视频) 模型。
在图像领域,字节已经发布了新一代豆包生图模型 Seedream 4.5。它在复杂指令遵循、画面元素保持能力上大幅提升,并融入了更丰富的世界知识,表现再上新台阶。它能够将不同人物、物体与场景照片智能组合,生成创意合影;将汽车渲染成精致的分解结构图;轻松制作多卡通角色的主题拼图;实现逼真的模特虚拟试穿,并生成媲美专业设计的产品营销海报。
在视频创作领域。Seedance 1.0 更强大继任者 Seedance 1.5 Pro 正式登场。其核心特点:音画同步输出、多人多语言对白配音,以及更强的影视级叙事张力。
根据介绍,相较于 1.0 版本,1.5 Pro 最大的特点是“音画同出”,即实现了声音与画面在时间、语义上的精准同步。它能根据画面中角色的数量和身份,精准匹配口型,解决了行业常见的“张口不发声”或口型不匹配的问题。同时,它原生支持多种语言及中国各地方言,为内容创作带来极大的实用性与丰富性。
回归视觉本身,模型不仅要生成高清画面,更需驾驭影视级镜头语言和叙事张力,捕捉细腻的微表情。Seedance 1.5 Pro 在这方面也大幅增强,能通过一段提示词,生成充满细节和情感张力的画面。
为了进一步提升创作效率,Seedance 系列即将上线 “Draft 样片”功能。用户可先快速生成低分辨率样片,验证创意和关键要素,满意后再生成最终成片。这将帮助用户将整体创作效率提升 65%,并减少 60% 的无效创作成本。

面向企业的“推理代工”
据统计,在 2025 年,已有超过 100 万家企业及个人使用了火山引擎的大模型服务,覆盖百余个行业,其中已有超过 100 家企业在火山引擎的累计 tokens 使用量突破了 1 万亿。今天,火山引擎再次面向企业推出了一系列优惠和新服务。
首先,火山引擎正式推出“豆包助手 API”。它将豆包 APP 核心的对话、思考、搜索、创作等 Agent 能力,以 API 形式开放,让企业可以“开箱即用”。首批与文本相关的四项能力已上线火山方舟,未来还将开放更多多模态理解、深度研究、视频通话等能力。
谭待表示,豆包 APP 不仅是国内用户规模最大的 AI 应用,从技术角度看,更是中国最复杂、难度最高的 AI Agent 之一。其背后对话、解读、搜索、研究等能力,均由一套复杂的 Agent 系统驱动,并经历了数亿用户的长期打磨。
鉴于企业内部使用大模型的部门和模型种类越来越多,火山引擎还推出了业界首个 「AI 节省计划」。火山引擎上所有按量付费的大模型,包括豆包及各类开源模型,均可参与。企业各部门可享受统一价格优惠,且不同模型的用量可合并累计,打破尝试新模型的冷启动成本顾虑。据介绍,该计划采用阶梯折扣,用量越多节省越多,最高可节省 47%的成本。
推理代工
其次,火山方舟正式推出“推理代工”服务。针对典型的开源大模型结构,火山方舟提供经过大规模验证的系统能力,包括极致的弹性伸缩、全栈推理优化与分布式缓存等整套支持。
具体来说,用户上传加密后的模型参数后,无需运维底层 GPU,无需进行复杂的网络与调度配置,只需关注模型本身。根据火山方面测试,当企业选择以云上集群替代自建集群时,硬件与运维成本可下降约一半;而进一步采用方舟推理代工服务后,对比在云上租赁 GPU 算力,客户可获得额外 1.6 倍左右的吞吐提升。
“这背后依赖于火山引擎充沛的 GPU 资源池与长期的推理优化投入。算力池规模越大,调度效率越高,单位成本就越低。我们能够在分钟级完成百卡到千卡的算力伸缩,以应对突发流量。”火山引擎智能算法负责人吴迪说道。
吴迪表示,着眼于长远,AI 产业的推理与训练走向分工与分层是大势所趋。
他解释道,对于大多数团队而言,低成本、高吞吐地“推理好”一个大模型,可能比“后训练好”一个模型更为困难。在建设初期,企业往往需要投入数百万人民币,经历数月的上线周期,并面临复杂的运维挑战。当业务进入规模化扩张阶段,除了线性增长的硬件成本,还有许多易被忽视的隐形成本:例如,规模化对运维团队提出更高要求、模型迭代与升级带来难以预估的成本,以及新业务爆发式增长时,推理资源往往措手不及。




