
Cloudflare 最近分享了他们是如何使用SaltStack(Salt)管理庞大的全球服务器集群的。在这篇博客文章中,他们讨论了解决“一粒沙(grain of sand)”问题所需的工程任务。它的关注点在于要从数百万次状态应用中找出某个配置错误。Cloudflare 的站点可靠性工程(SRE)团队重新设计了其配置的可观测性,他们将故障与部署事件关联起来。这项工作将发布延迟减少了 5%以上,并减少了手动分析问题相关的工作。
作为配置管理(configuration management,CM)的工具,Salt 能够确保了跨数百个数据中心的数千台服务器保持在期望的状态。在 Cloudflare 的规模下,即使 YAML 文件中的一个微小语法错误或“Highstate”运行期间的瞬时网络故障,都可能阻碍软件发布。
Cloudflare 面临的主要问题是预期配置与实际系统状态之间的“偏离(drift)”。当 Salt 运行失败时,它影响的不仅仅是一台服务器,它可能会阻止在整个边缘网络中推出关键的安全补丁或性能特性。
Salt 使用了带有ZeroMQ的主控/受控(master/minion)设置。这使得很难找出为什么特定的受控端(代理)没有向主控端报告状态,这简直就像大海捞针。Cloudflare 总结了几个破坏此反馈循环的常见故障模式:
无声故障:受控端在状态应用期间可能会崩溃或挂起,导致主控端无限期地等待响应。
资源耗尽:繁重的 pillar 数据(元数据)查找或复杂的 Jinja2 模板可能会使主控端的 CPU 或内存不堪重负,导致 job 丢失。
依赖地狱:包状态可能会因为上游仓库无法访问而失败,但错误消息可能埋藏在数千行日志的深处。
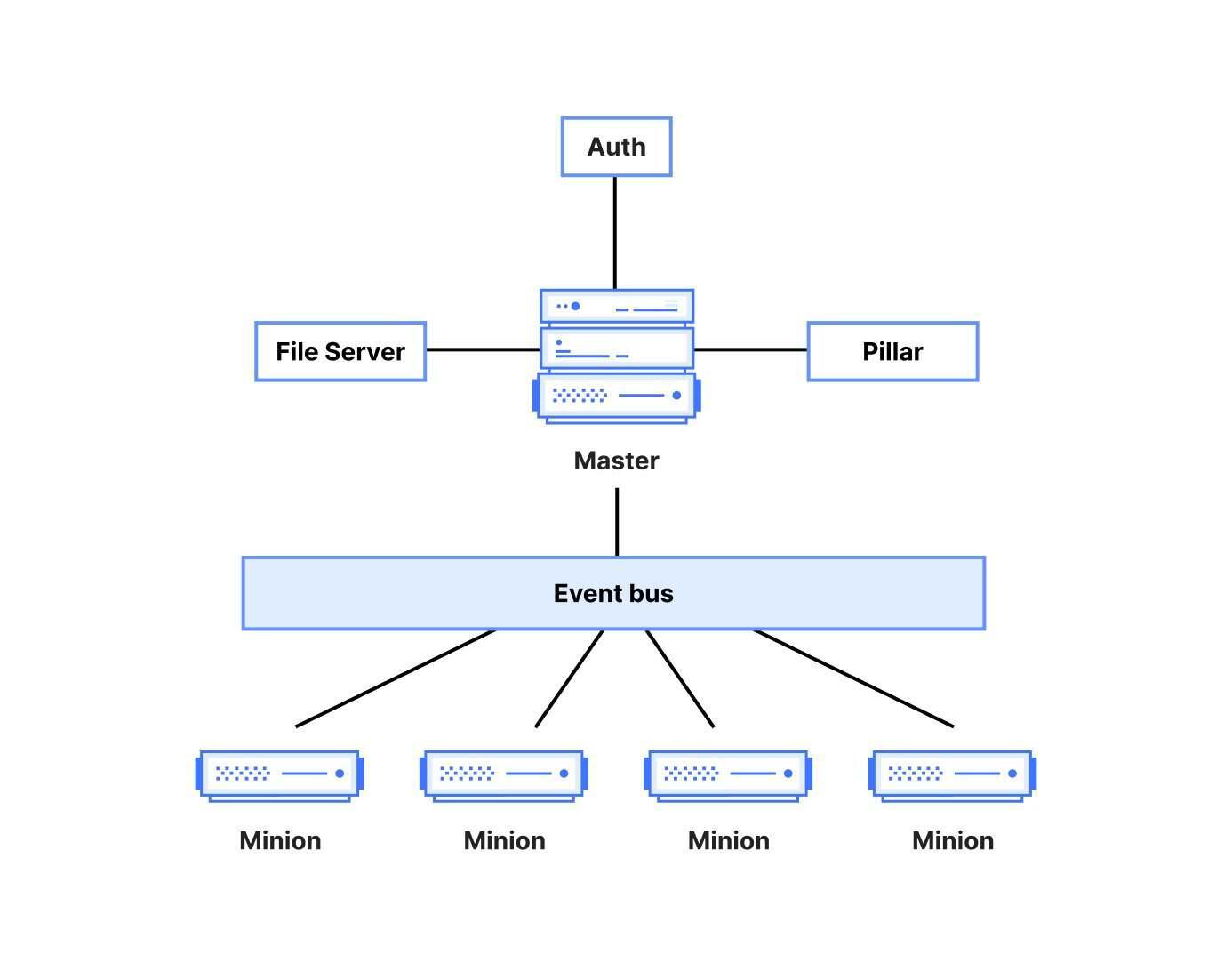
Salt 的架构图
当发生错误时,SRE 工程师必须手动通过 SSH 登录到候选受控端。他们会追踪主控端上的 job ID,并筛选保留时间内有限的日志,然后尝试将错误与变更或环境条件联系起来。在拥有数千台机器和频繁提交代码的情况下,这个过程变得单调且难以维护。它提供的持久工程价值非常有限。
为了解决这些挑战,Cloudflare 的商业智能和 SRE 团队合作构建了一个新的内部框架。目标是为工程师提供一种“自助服务”机制,以识别跨服务器、数据中心和特定机器组的 Salt 故障的根本原因。
解决方案涉及从集中式日志收集转向更健壮的、事件驱动的数据摄入管道。这个在相关内部项目中被称为“Jetflow”的系统,允许将 Salt 事件与以下内容关联:
Git 提交:识别配置仓库中触发故障的精确变更。
外部服务故障:确定 Salt 失败是否实际上是由依赖项(如 DNS 故障或第三方 API 中断)引起的。
临时(Ad-Hoc)发布:区分计划的全局更新和开发人员进行的手动更改。
Cloudflare 通过改变管理基础设施故障的方式,为自动分类奠定了基础。系统现在可以自动标记特定的“一粒沙”,即导致发布阻塞的那一行代码或那一台服务器。
从被动管理到主动管理的转变带来了以下成果:
发布延迟减少 5%::通过更快地暴露错误,缩短了从“代码完成”到“在边缘运行”的时间。
减少琐事:SRE 不再需要花费数小时进行“重复性分类”,使他们能够专注于更高层次的架构改进。
改进的可审计性:现在每个配置变更都可以从 Git PR 到边缘服务器上的最终执行结果进行全生命周期追踪。
Cloudflare 工程团队观察到,尽管 Salt 是一个强大的工具,但在“互联网规模”下管理它需要更智能的可观测性。通过将配置管理视为一个需要关联和自动分析的关键数据问题,他们为其他大型基础设施提供商树立了榜样。
基于 Cloudflare 在 SaltStack 上遇到的挑战,需要注意的是,像Ansible、Puppet和Chef这样的替代配置管理工具,每个工具都有不同的架构权衡。Ansible 使用 SSH 无代理的方式工作。这比 Salt 的主控/受控设置更简单。然而,由于顺序执行,它在大规模环境时可能会面临性能问题。Puppet 使用基于拉取的模型,代理会与主控服务器进行核对。这提供了更加可预测的资源使用,但与 Salt 的推送模型相比,可能会减慢紧急变更的速度。Chef 也使用代理,但侧重于使用其 Ruby DSL 的代码驱动方法。这为复杂任务提供了更大的灵活性,但学习曲线更陡峭。
在 Cloudflare 的规模下,任何工具都会遇到其自身的“一粒沙”问题。然而,关键教训很明确,那就是管理数千台服务器的任何系统都需要强大的可观测性。它还必须能够将故障与代码变更自动关联,并具备智能分类机制。这将手动侦探工作转化为可操作的洞察力。
原文链接:
Cloudflare Automates Salt Configuration Management Debugging, Reducing Release Delays




