
Anthropic 正在升级它“最聪明的模型”。
随着新一代旗舰模型 Claude Opus 4.6 的发布,Anthropic 释放出的信号十分明确:这并不是一次常规的性能小修小补,而是一轮围绕长任务、复杂工作,以及智能体(agent)如何真正干活展开的系统性升级。
在这次发布之前,Anthropic 内部和部分早期用户已经开始让 Opus 4.6 参与一项持续时间很长的工程任务:从零开始,用 Rust 编写一个完整的 C 编译器,并要求它能够编译 Linux 内核。
这项实验持续了约两周时间,期间累计运行了近两千次 Claude Code 会话,最终产出了一个规模约 10 万行代码的编译器。该编译器不仅能够在多种架构上构建 Linux 6.9,还可以编译 FFmpeg、Redis、PostgreSQL、QEMU,并通过了 GCC 自身 99% 的 torture test,甚至能够成功编译并运行 Doom。整个实验的 API 成本约为 2 万美元。
为了让外界更直观地理解这一成果的尺度,有网友在社交平台上给出了一个对照:GCC 的开发从 1987 年开始,历经 37 年,投入过数以千计的工程师。而这一次,是一名研究者加上 16 个 AI 智能体,在短短数周内完成了一个能够通过大量 GCC 测试集、并编译真实大型项目的编译器。
正是在这样一段持续推进的工程实践之后,Anthropic 对外发布了 Claude Opus 4.6。
成立于 2021 年、由一批前 OpenAI 研究人员和高管创立的 Anthropic,一直以 Claude 系列大模型为核心产品;在这一体系中,Opus 代表最大、能力最强的型号,Sonnet 和 Haiku 则分别覆盖中等与轻量级使用场景。某种程度上,Opus 系列承担的角色,就是在更复杂、更长期的任务环境中检验 Claude 的能力边界。
最强的编码模型:从跑分看 agentic 编程能力
Anthropic 对 Opus 4.6 的定位,并不只是“更会写代码”。他们强调,新模型在编程能力上的提升,已经从单纯的代码生成,扩展到更前置的任务规划,以及更后置的代码审查与调试流程。这种变化,使模型能够在大型代码库中更稳定地工作,也直接决定了它是否有能力脱离短对话模式,持续参与多阶段、长周期的工程任务。
这种定位在评测结果中体现得比较清楚。Anthropic 公布的多项基准测试显示,Claude Opus 4.6 在 agentic 编程、计算机使用、工具调用、搜索以及金融等任务上,整体跑分都有所提升。
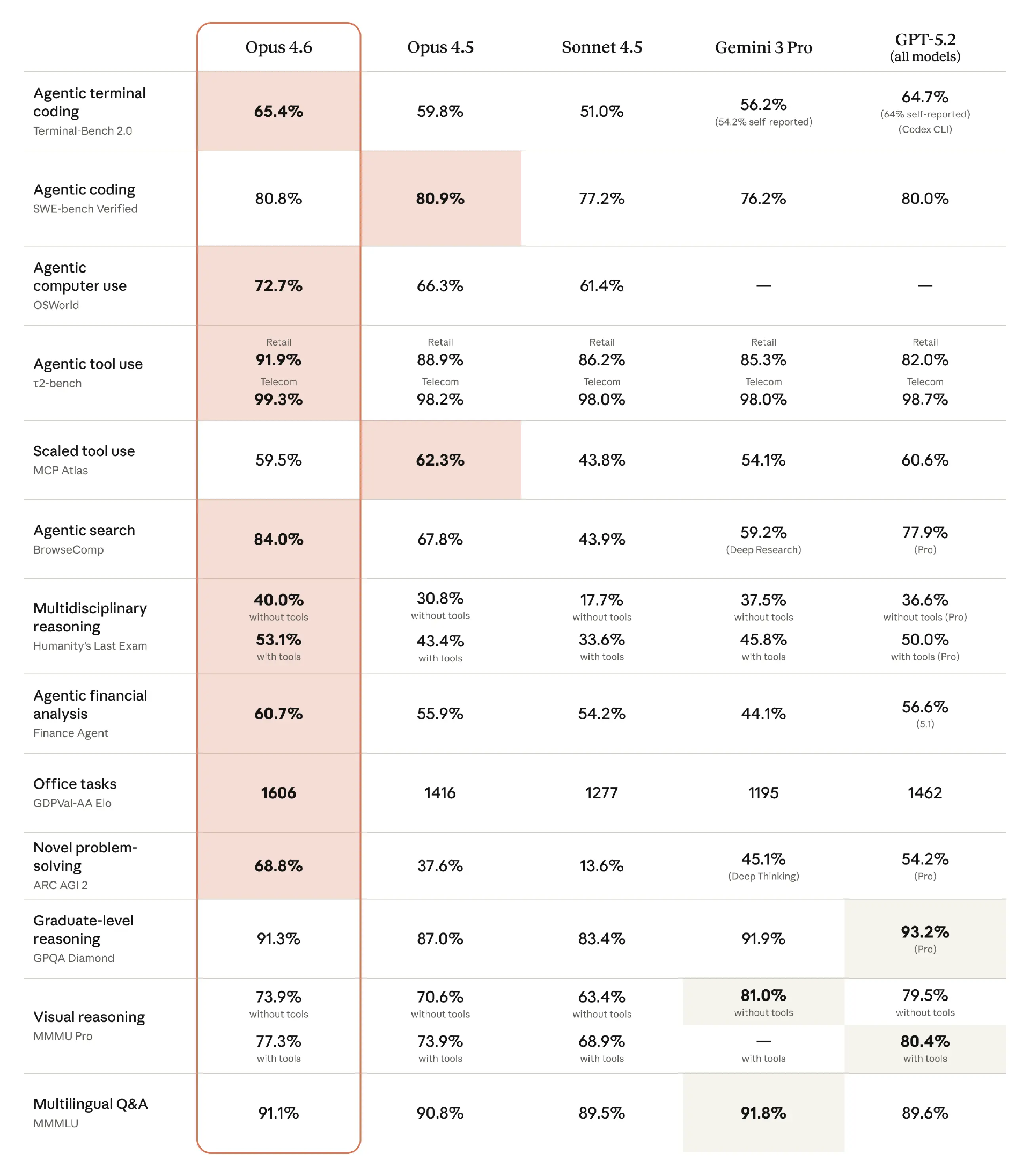
在终端 agentic 编程能力上,Opus 4.6 得分 65.4%,对比来看,略高于 GPT-5.2 的 64.7%,明显领先 Gemini 3 Pro(56.2%)和 Sonnet 4.5(51.0%)。这说明在纯终端环境下执行多步编程任务时,Opus 4.6 的稳定性和自我修正能力处在第一梯队。
在 SWE-bench Verified(Agentic coding) 上,各家分数非常接近,Opus 4.6(80.8%)与 Opus 4.5(80.9%)、GPT-5.2(80.0%)基本处于同一水平。这里可以理解为:在标准化的软件工程任务上,能力已经开始趋同。
但在电脑操作(OSWorld)上,代际差异开始显现。
OSWorld(Agentic computer use) 是一个比较关键的分水岭。Opus 4.6 达到 72.7%,相比 Opus 4.5 的 66.3% 有明显提升,而 Sonnet 4.5 只有 61.4%,其他模型则未给出对等数据。这类评测关注的是 GUI 操作、跨应用流程和状态理解能力。放在整张表里看,它与编程能力的同步提升,意味着 Opus 4.6 不只是“会想”,而是更擅长把计划落到具体操作上。
Agentic search(BrowseComp):明显拉开差距。
BrowseComp 是整张表里差距最清楚的一项。Opus 4.6 为 84.0%,而 GPT-5.2 Pro 是 77.9%,Opus 4.5 只有 67.8%,Sonnet 4.5 更低。这一项测的是在真实开放网络中定位、筛选和组合信息的能力,结果说明 Opus 4.6 在“研究型 agent 行为”上已经明显领先,而不是只在封闭工具或结构化任务中占优。
另外,在 Humanity’s Last Exam(跨学科推理)和 ARC-AGI-2(新问题解决) 上,Opus 4.6 的优势更加明显,尤其是 ARC-AGI-2 的 68.8%,相比 GPT-5.2 Pro 的 54.2% 和 Gemini 3 Pro 的 45.1%,已经不是细微差距。这类评测通常更难通过“提示工程”或策略优化取得跃升,更像是在反映模型本身的泛化推理能力。
“上下文腐烂”与模型可用性的分水岭
Opus 4.6 还扩大了上下文窗口,也就是单次会话里可记住、可处理的信息量更大。
新模型在 Beta 阶段提供 100 万 token 的上下文长度,与该公司现有的 Sonnet(4 和 4.5 版本)相当。Anthropic 表示,这样的上下文容量更适合处理更大型的代码库,也能支持对更长文档的分析与处理。
但 Anthropic 特别强调,Opus 4.6 的提升并不是“能塞更多 token”,而是“塞进去之后还能用”。
他们在说明中提到,Opus 4.6 在大规模文档中检索关键信息的能力显著增强,这一点在长上下文任务中尤为明显:它可以在数十万 token 范围里持续跟踪信息,偏差更小,也更容易捕捉到埋得很深的细节——包括一些 Opus 4.5 本身就已经容易漏掉的信息。
这正好对应了开发者长期吐槽的一个问题:“上下文腐烂(context rot)”。很多模型在对话或任务一旦拉长之后,要么开始遗忘早期信息,要么虽然“看过”,但已经无法在后续推理中正确调用,最终表现为前后不一致、定位问题跑偏、重复试错。
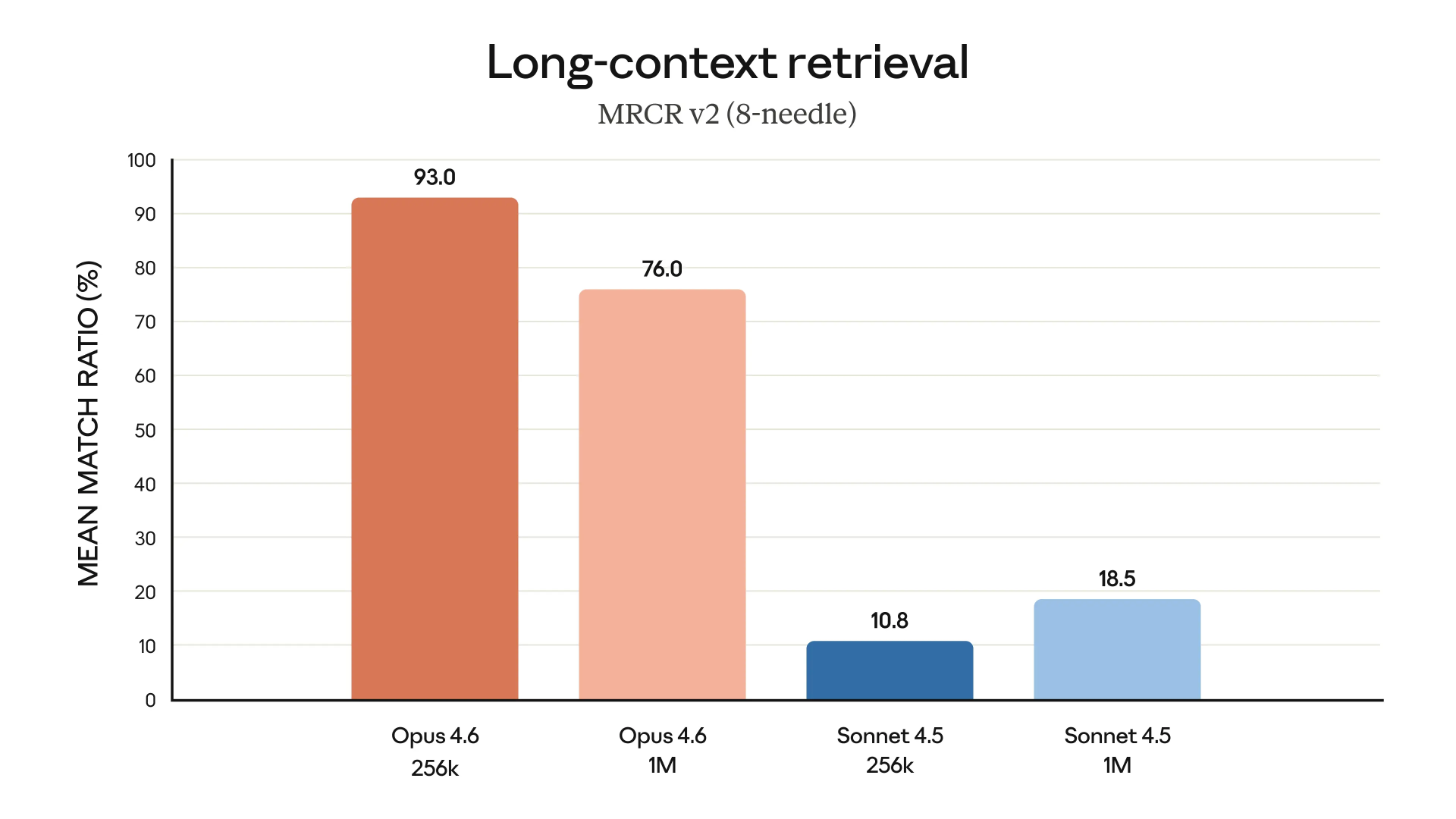
MRCR v2(8-needle、100 万 token)这类“草堆找针”测试,本质上就是在专门检验这种能力:把多个关键线索埋在超长文本里,看模型能否在不迷路的情况下把它们重新找出来。Opus 4.6 在该测试中的得分为 76%,而 Sonnet 4.5 仅为 18.5%。
这并不是简单的“高一点、低一点”,更像两种不同的可用性状态:一个模型在超长上下文中仍然能稳定检索并利用信息,另一个则在任务拉长后迅速失效。
这种长上下文的稳定性,直接影响模型能否胜任更“工程化”的工作,尤其是复杂代码分析与故障诊断。在 Anthropic 给出的能力图中,Opus 4.6 被特别标注为擅长做 root cause analysis(根因分析)。
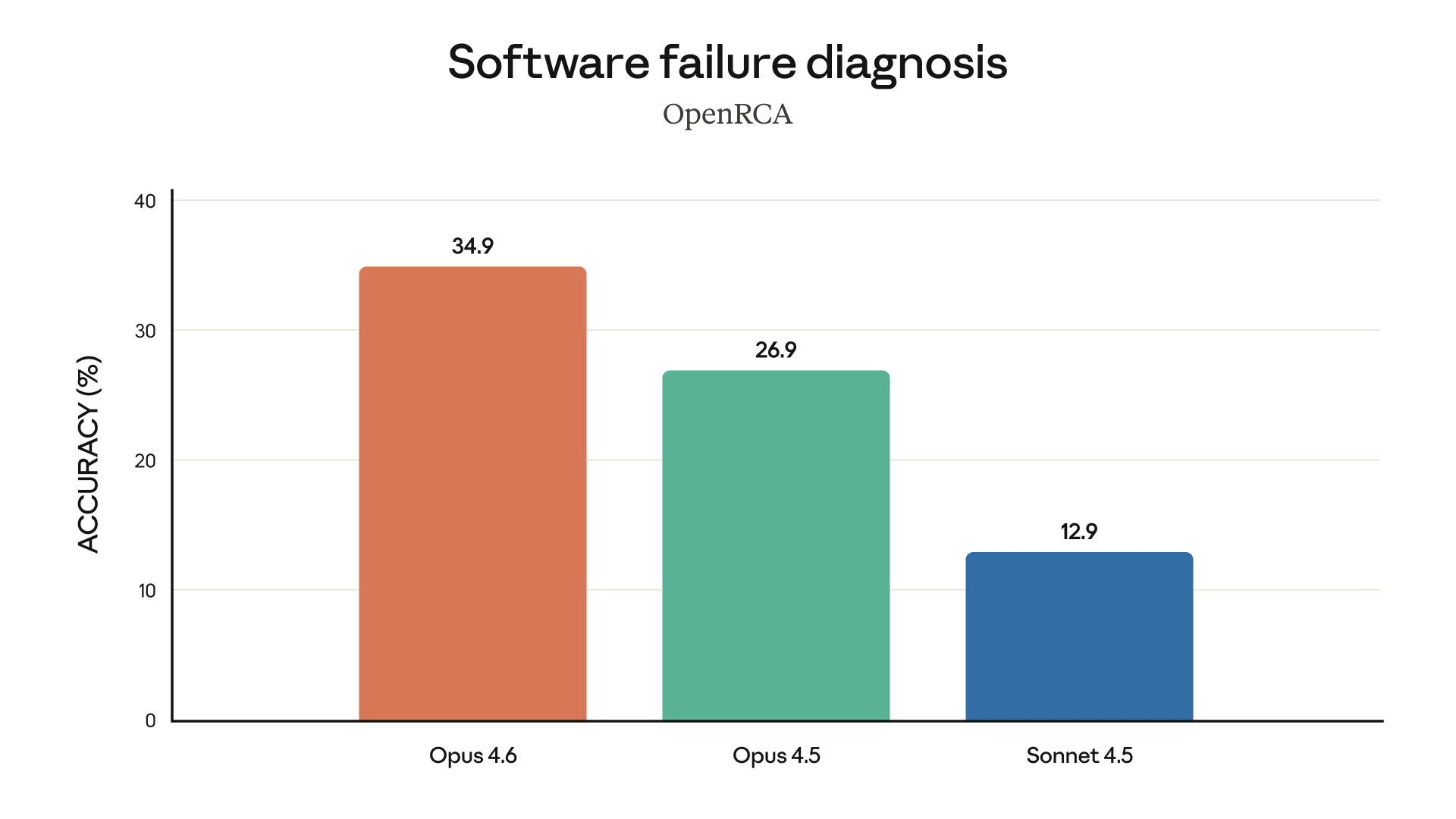
用 Agent 团队,构建一个 C 编译器
4.6 最醒目的新增功能,是 Anthropic 所称的“智能体团队”(agent teams):由多个智能体组成的小队,可以把一个大任务拆成若干独立的子任务分别推进。
Anthropic 的说法是:“不再让单个智能体按顺序把任务一路做到底,而是把工作分给多个智能体——每个智能体负责自己的一块,并直接与其他智能体协调。”
Anthropic 产品负责人 Scott White 将其类比为“雇了一支很能干的人类团队”,因为职责拆分后,智能体可以并行协作,从而更快完成工作。目前,“智能体团队”以研究预览(research preview)的形式向 API 用户与订阅用户开放。
编译器本身固然是一个高度复杂、且极具工程价值的成果,但在 Anthropic 团队看来,它更像是一次“能力压力测试”的载体。真正值得总结的,是围绕 长时间运行的自治 Agent 团队(long-running autonomous agent teams) 所形成的一整套工程方法论:如何设计无需人工干预的测试体系、如何让多个 Agent 并行推进复杂工作、以及这种架构在现实工程中究竟会在哪些地方触碰到上限。
从“协作式 Agent”到“自治式 Agent”
现有的 Agent scaffolding(例如 Claude Code)本质上仍然是人机协作系统:模型在解决复杂问题时,往往会在某个阶段停下来,等待操作者继续输入新的指令、确认状态,或澄清歧义。Anthropic 的实验目标是消除这种对“人类在线”的依赖,让 Claude 能够在无人监督的情况下,持续推进一个长期任务。
为了实现持续自主的进展,Claude 工程团队并没有引入复杂的调度系统,而是构建了一个程序,让 Claude 进入一个简单的循环(如果你见过 Ralph 循环,应该会觉得眼熟):每完成一个任务,就立刻进入下一个任务,而不是回到“等待用户”的状态。

在 Agent prompt 中,Claude 被明确要求将问题拆解成可执行的小任务、记录当前进展、判断下一步行动,并持续迭代,直到系统判定“没有明显改进空间”。(在这最后一点上,Claude 没有选择,因为循环会一直运行——不过在一次实验中,团队确实看到 Claude 不小心执行了 pkill -9 bash,结果把自己杀掉了,循环也就随之结束了。)
并行运行 Claude
并行运行多个实例,可以缓解单一 agent harness 的两个弱点:
一次 Claude Code 会话同一时间只能做一件事。随着项目范围扩大,并行调试多个问题会高效得多。
运行多个 Claude agent 可以实现“分工”。当一部分 agent 负责解决核心问题时,其他专门的 agent 可以被调用来(例如)维护文档、盯代码质量,或处理更专门的子任务。
Claude 工程团队的并行实现非常基础:先创建一个新的裸 Git 仓库;然后为每个 agent 启动一个 Docker 容器,把仓库挂载到 /upstream。每个 agent 会在容器内克隆一份本地副本到 /workspace,完成工作后,从各自的容器把改动推回 upstream。
为避免两个 agent 同时尝试解决同一个问题,harness 使用了一个简单的同步算法:
Claude 通过在 current_tasks/ 下写入一个文本文件来“锁定”某个任务(例如,一个 agent 可能锁定 current_tasks/parse_if_statement.txt,另一个锁定 current_tasks/codegen_function_definition.txt)。如果两个 agent 试图认领同一任务,Git 的同步机制会迫使第二个 agent 改选另一个任务。
Claude 在任务上工作完成后,会从 upstream 拉取、合并其他 agent 的改动、推送自己的改动,然后移除锁。合并冲突很常见,但 Claude 能够处理。
无限的 agent 生成循环会在一个全新的容器里启动新的 Claude Code 会话,然后重复上述流程。
这是一个非常早期的研究原型。Claude 工程团队尚未实现任何其他 agent 之间的通信方法,也没有强制任何高层目标管理流程,也没有使用 orchestration agent。
相反,团队把“如何行动”的决定权交给每个 Claude agent。多数情况下,Claude 会选择“下一个最显而易见”的问题继续做;当卡在某个 bug 上时,Claude 往往会维护一份持续更新的文档,记录失败过的方法和剩余任务。在项目的 Git 仓库里,可以通过历史记录看到它如何在不同任务上获取锁并推进。
用 Claude 团队写代码:一些更管用的做法
把 Claude 放进循环只是起点,真正决定它能否持续推进的,是它能不能从环境和反馈中判断“下一步该做什么”。因此,Claude 工程团队把大量精力放在模型之外:测试如何设计、反馈如何呈现、运行环境如何约束,才能让 Claude 在无人干预的情况下仍然保持方向感。
一个核心前提是:必须围绕语言模型的固有限制来设计系统。在这次实践中,团队重点应对了两类限制。
首先是上下文窗口污染。测试框架不能输出成千上万字节的无用信息,最多只保留几行关键输出,其余重要内容统一写入文件,供 Claude 在需要时自行查阅。日志也需要便于自动处理:一旦出现错误,必须在同一行明确标出 ERROR 以及失败原因,方便 grep 直接检索。同时,能提前算好的汇总统计信息会被预先计算,避免 Claude 在上下文中反复做同样的推导。
另一类限制是时间盲。Claude 无法感知时间,如果无人干预,很容易长时间沉浸在跑测试里而不推进工作。为此,测试框架很少输出增量进度,避免不断污染上下文,并提供默认的 --fast 选项,只运行 1% 或 10% 的随机子样本。这个子样本对单个 agent 是确定的,但在不同虚拟机之间是随机的,从整体上仍能覆盖所有文件,同时又能让每个 agent 精确识别回归问题。
在并行方面,团队也很快意识到:并行是否有效,取决于问题是否“好拆”。当失败测试数量多且彼此独立时,并行非常直接——每个 agent 处理一个不同的失败测试即可。在测试通过率接近 99% 后,团队让不同 agent 分别去完成不同小型开源项目的编译,例如 SQLite、Redis、libjpeg、MQuickJS 和 Lua。
但当任务升级到编译 Linux 内核时,情况发生了变化。内核编译本质上是一个高度耦合的整体任务,所有 agent 都会命中同一个 bug,修完再相互覆盖。即便同时运行 16 个 agent,也无法带来实质进展,因为大家都卡在同一件事上。
解决办法是引入 GCC 作为在线的、已知良好的对照编译器。团队编写了新的测试框架:随机选择内核中大部分文件用 GCC 编译,只把剩余文件交给 Claude 的 C 编译器。如果内核能够正常运行,说明问题不在 Claude 负责的那部分文件;如果失败,则再通过把其中一些文件切回 GCC 编译,逐步缩小范围。这样一来,不同 agent 就可以并行地修复不同文件中的不同错误,直到 Claude 的编译器最终能够编译全部文件。即便如此,后续仍需要配合增量调试(delta debugging),找出那些“单独没问题、组合在一起就失败”的文件对。
并行运行也带来了另一层收益:角色分工成为可能。在实践中,Claude 工程团队发现,LLM 生成的代码很容易重复实现已有功能,因此专门安排了一个 agent 负责扫描并合并重复代码;另一个 agent 聚焦于提升编译器自身的性能;第三个 agent 负责改进生成代码的效率。
除此之外,还有 agent 从 Rust 开发者的视角审视整个项目的设计,提出结构性调整建议,以提升整体代码质量;另一个 agent 则专注于文档维护。通过这种方式,不同 Claude 实例在同一代码库中承担起相对稳定的职责,而不是反复在同一层面“重新发明轮子”。
评估结果与能力边界
在两周内接近 2,000 次 Claude Code 会话中,Opus 4.6 共消耗约 20 亿输入 token、生成约 1.4 亿输出 token,总成本略低于 2 万美元。该团队表示,即便与最昂贵的 Claude Max 方案相比,这仍是一次成本极高的实验;但这一成本依然远低于由单人、甚至完整人类团队完成同等工作的成本。
该编译器是一次完全的 clean-room 实现:开发过程中 Claude 从未获得互联网访问权限,仅依赖 Rust 标准库。
最终得到的约 10 万行代码,能够在 x86、ARM 和 RISC-V 架构上构建可启动的 Linux 6.9,同时也可以编译 QEMU、FFmpeg、SQLite、Postgres、Redis,并在包括 GCC torture test 在内的大多数编译器测试套件中达到约 99% 的通过率。此外,它还通过了开发者的终极考验:它可以编译并运行 Doom 游戏。
但与此同时,这一项目也把当前 Agent 团队的能力边界暴露得相当清晰。
缺乏启动 Linux 所需的 16 位 x86 编译能力,因此在 real mode 阶段会调用 GCC(x86_32 与 x86_64 编译器由其自身实现)。
尚未拥有稳定可用的 assembler 与 linker;这些是 Claude 开始自动化的最后环节,目前仍存在问题,演示中使用的是 GCC 的相关工具。
该编译器能够成功编译许多项目,但并非所有项目都能成功。它目前还不能完全替代真正的编译器。
生成的代码效率不高。即使启用所有优化,其效率也低于禁用所有优化的 GCC 生成的代码。
Rust 代码质量尚可,但远不及 Rust 专家级程序员编写的代码质量。
整体实现已接近 Opus 的能力上限,新增功能或修复 bug 时,经常会破坏已有功能。其中一个最具代表性的难点是 16 位 x86 代码生成。尽管编译器可以通过 66/67 opcode 前缀生成语义正确的 16 位 x86 代码,但生成结果超过 60KB,远高于 Linux 强制的 32KB 限制。因此,在这一阶段,Claude 选择调用 GCC 作为替代(该情况仅出现在 x86 上;在 ARM 与 RISC-V 架构下,编译可完全由 Claude 自身完成)。
该编译器的源码已经公开:https://github.com/anthropics/claudes-c-compiler。Claude 工程团队建议直接下载、阅读代码,并在自己熟悉的 C 项目上尝试。
参考链接:




