
日均数千起宕机、百万条告警,碎片化地散落在数百万台异构服务器之中——这是当前规模化集群平台面临的普遍挑战,每一次的故障定位和根因溯源都如同大海捞针。
“在百万级异构服务器的存量里,时间主要耗在‘找人、找入口、对齐上下文’,而不是分析根因。” OCManager 核心研发、OpenCloudOS 社区核心 Contributor 游绍萍道破传统运维平台的困境。庞大基数下,“人肉排障”模式已触及极限。据 OpenCloudOS 统计,异常分析工单的耗时高达普通工单的 6 倍。
大模型带来了破局希望,但在“辅助排障”与“接管排障”之间,仍然隔着巨大鸿沟。直接接入运维系统,常遭遇执行黑盒、上下文污染等致命问题,以及幻觉与确定性的缺失,非但无法减负,反而可能制造更大混乱。
把 Agent 接进宕机现场,不只是提建议,而是让 AI 跑完整条排障链路,这在生产环境能否行得通?OpenCloudOS 社区花了三年时间,在数百万台服务器的真实故障中寻找答案。
今天,他们把这套三年摸索出来的系统层 AI 诊断方案 OCManager,连同背后经受住实战考验的积累,正式开源。
一、 运维的困局与 AI 的边界
过去十年,Prometheus、ELK、Ansible 等运维领域的工具极大提升了单点效率,却始终“各管一段”:监控归监控,日志归日志,配置管理归配置管理。
当一台服务器出现问题,工程师需要在这些工具之间来回切换,把分散的信息拼凑成一张完整的故障图。这个"拼凑"的过程,才是真正耗时的地方。

而运维团队更深层的挑战还在于经验的不可传递性。专家看到 CPU 抖动,能直觉关联到内存和 IO 队列,形成多维关联判断。但这个判断过程往往是隐性的,无法被系统化、无法被检索、无法被复用。人员流动,经验就随之流失。
这也是为什么,即便市面上的运维管理工具已经足够丰富,宕机排障依然消耗了运维工程师的大量精力与时间的症结——因为工具可以被传递和复制,但人的经验却不能。
所以,大模型能解决这个问题吗?
直觉上,大模型天然适合做“串联”链路的判断,它有语义理解能力,能处理多维信息。但 TencentOS 团队在工程实践中发现,直接把大模型接进生产环境,会带来三个硬伤:
一是黑盒问题,Agent 执行路径不可预测,同样问题可能走向截然不同的分析;
二是上下文污染,规划与反思逻辑混杂在长 Prompt 中,模型极易迷失目标;
三是深度绑定,现有框架难贴合业务定制,“改到最后不如重写”。
归根结底,运维排障缺的不是更强的模型,而是一套工程化约束机制,一套能让大模型在正确的时间、正确的地点,思考正确问题的工作流程。
要突破这道边界,必须先消除工具孤岛,再给 AI 套上合适的缰绳让它接管执行。而这,正是开源方案 OCManager 试图解决的命题。
二、为 AI 搭建一个扎实的运维工作台
游绍萍认为,传统运维平台很可能被数据采集的边际成本和过长的定位链路拖垮。“把散落的工具链打通,把人的经验沉淀”,这是 OpenCloudOS 开源 OCManager(OpenCloudOS 智能管家) 的初衷。
OCManager 定位于解决大规模 Linux 集群“看不全、管不住、查不出、修不快”的闭环问题。但请注意,它不是一个需要你自己去“手搓”和拼装的单点工具集合,而是一个开箱即用的一体化工作台:
从主机纳管、批量操作,到指标看板、异常诊断,再到与 AI 直接对话,所有操作都在同一个 Web 控制台内完成。
它不锁死生态,一期支持 OpenCloudOS 及其商业版 TencentOS,后续将扩展至主流开源 OS;它也不是实验室里的 Demo,在开源之前,它已经在数百万机器的生产环境里,实打实地跑了三年多。
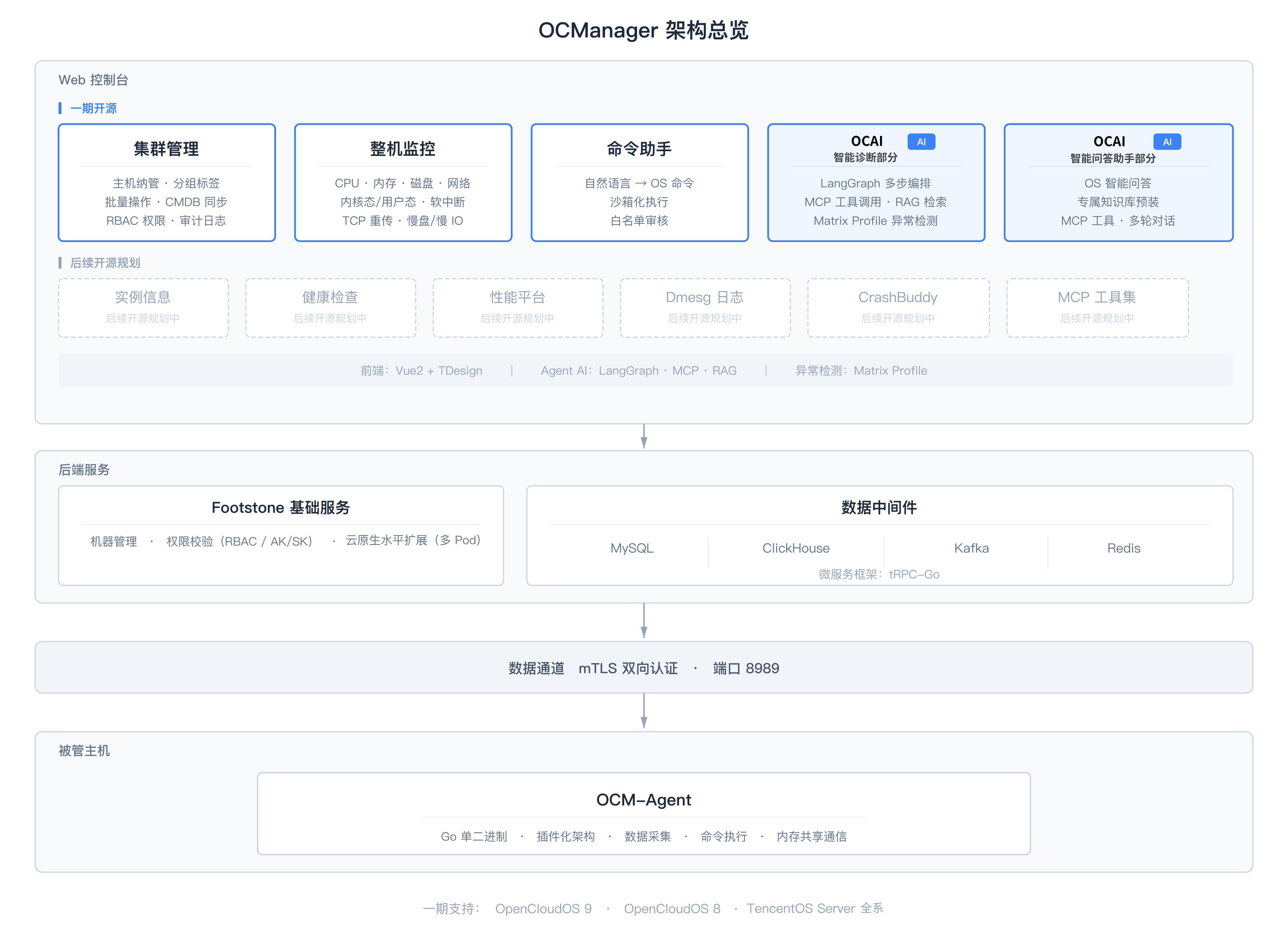
OCManager 一期主要开源五大核心模块:
首先是底座:集群管理,解决的是“管得住”的问题。它支持百万级机器的规模化纳管,通过加密双向认证建立高并发长连接,并提供标签化分组与细粒度的权限管控。
它是后续实现整机监控与 AI 诊断功能的底座。
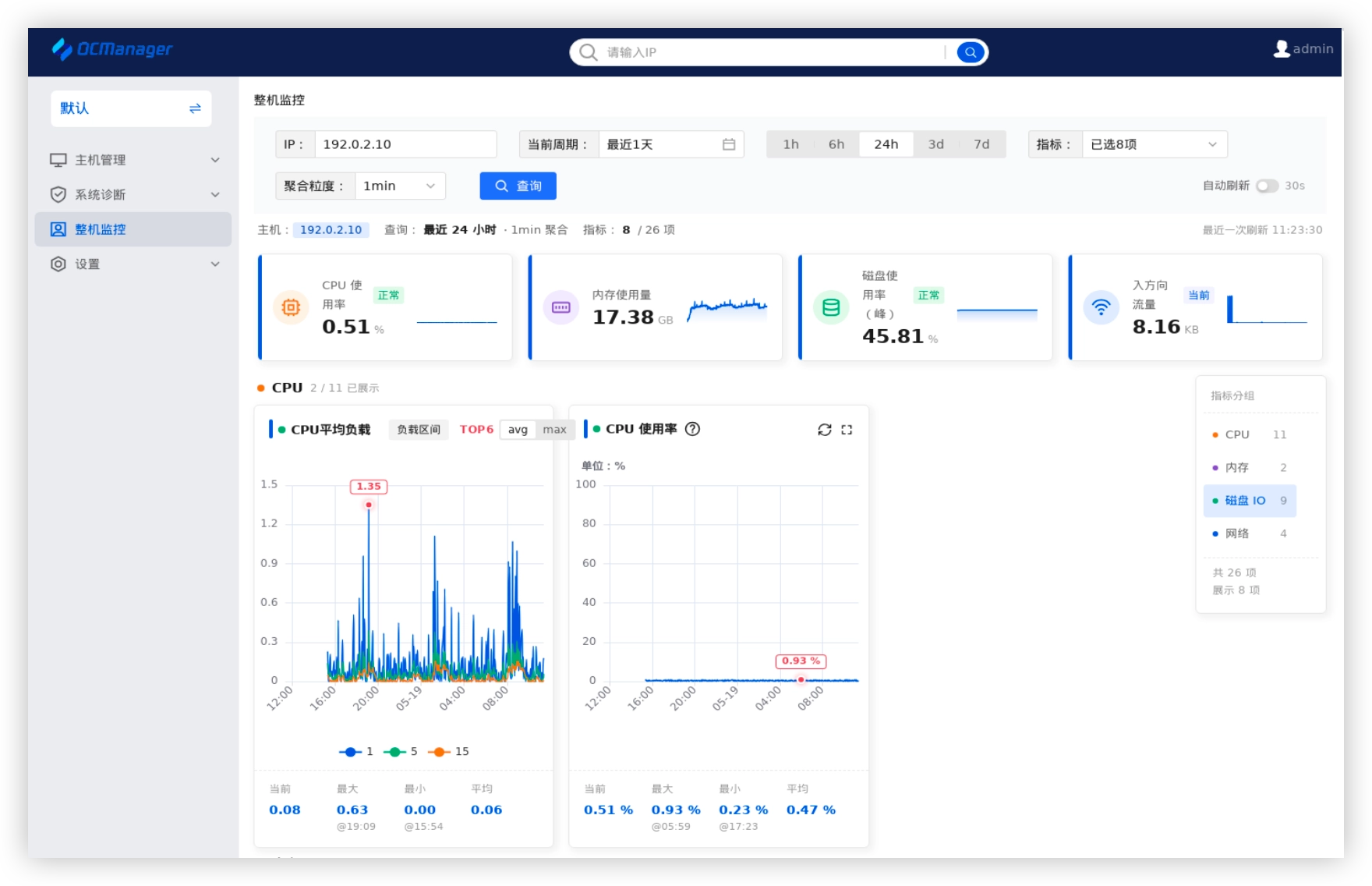
其次是眼睛:整机监控。 传统监控往往只能看到“整机负载虚高”,却定位不了具体的硬件瓶颈。OCManager 的整机监控专为系统级排障设计。
它下探到 CPU、内存、磁盘 I/O、网络四大维度,抓取 26 项核心参数。模糊的“红灯”告警,由此精准定位到物理设备和网卡级别。
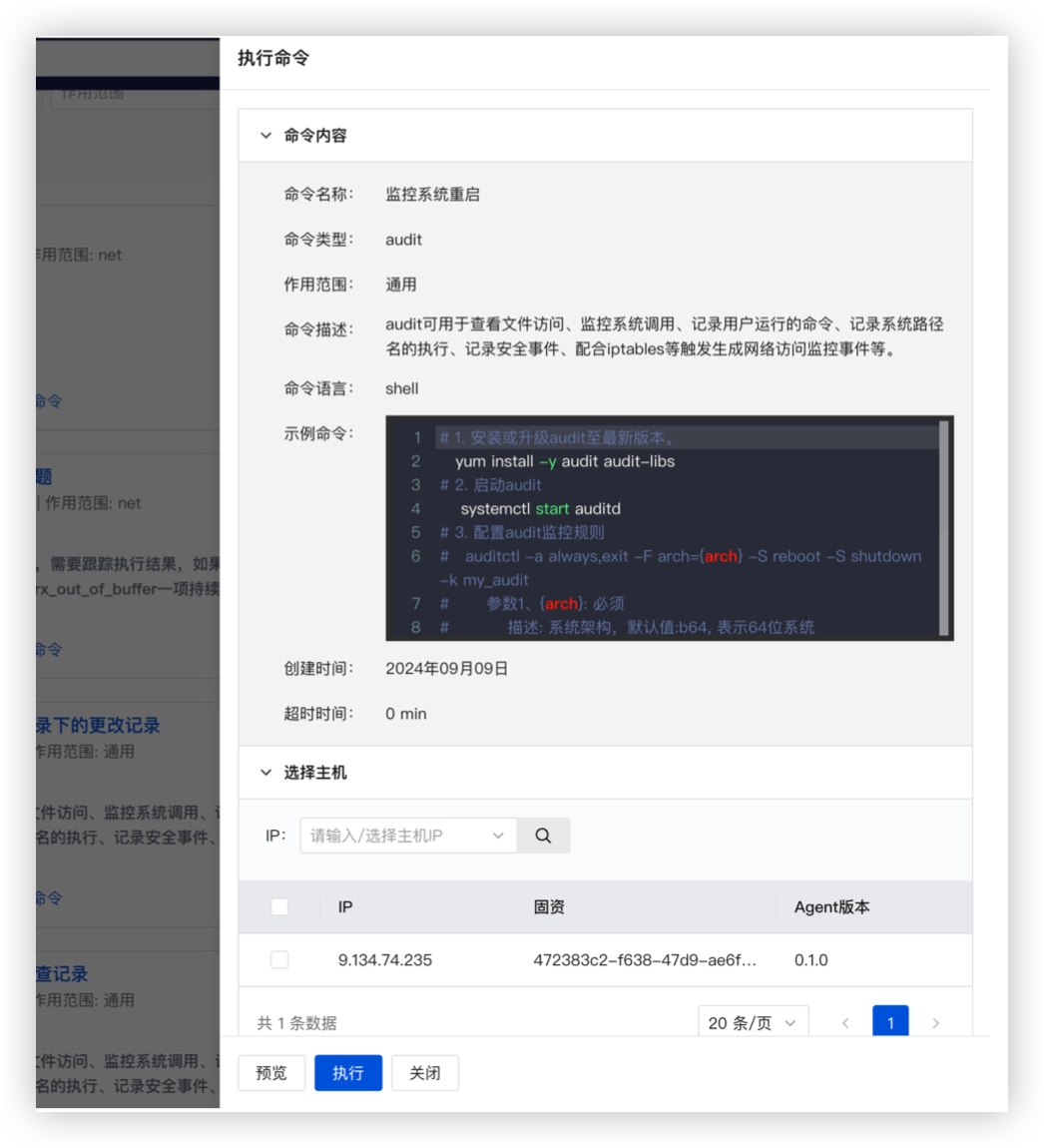
然后是手:命令助手。 这个模块直接击中了“经验断层”的痛点。老运维离职,最可惜的不仅是人走了,还有他们脑子里的排障命令库消失了。
命令助手把底层命令行重构为标准化、可复用的 Web 端作业模板,支持参数化下发和白名单审核,全程操作归档可追溯。它让个人的排障手艺,变成了团队可传承的资产。
最后,也是最核心的大脑:OCAI-Service。 这是 OCManager 区别于传统运维平台的根本。
它包含“智能诊断”(深层根因分析)和“智能问答”(日常技术咨询)两个子能力,共用统一入口,系统自动识别意图进行分流。这不仅仅是在控制台里加了个对话框,而是真正试图让 AI 介入排障链路。
底层的工程实现上,OCManager 拒绝了异构拼凑:被管主机上只运行一个轻量级的采集 Agent(支持插件化扩展),通过加密通道安全上报数据。
● 后端采用微服务架构,并整合了关系型数据库、海量日志引擎与消息队列来应对大规模数据吞吐;
● 前端则提供统一的 Web 控制台。一套架构,一体成型。
在架构上,OCManager 坚持控制面与数据面分离,将海量 Agent 连接洪峰从控制台剥离;同时把“在一批机器上拿到同一类证据”抽象为统一的任务编排模型。
“我们的目标是把规模化带来的不确定性,收敛为可运维、可扩展的系统边界。” 游绍萍表示,此时开源,也是为了将实战中的边界条件开放给社区,避免行业重复建设,加速与现有可观测性体系的对接。
有了这个打通数据、沉淀经验的一体化工作台,AI 才有了不幻觉、不迷路的抓手。
三、如何让 AI 真正接管诊断
对于如何定义“真正进入运维链路的 Agent”,OCManager 核心研发、OpenCloudOS 社区核心 Contributor 李强给出了三条硬标准:结论能追溯到平台侧真实证据而非模型臆测;取证走统一任务编排而非人肉跳转;操作风险在执行前就被平台约束。
李强指出,OCAI 的核心逻辑,就是把“现象→证据→建议”串成一条可回放链路。通过自动绑定机器身份与时间窗口,深度模式下调用远程命令拿出现场输出,把传统的“建议你去查”,真正变成“我已拿到结果并据此判断”。
“真正进入链路的 Agent,价值在于缩短从现象到可验证证据、再到可执行建议的路径,而不是生成更长的报告。”
为了实现这一闭环,OCAI-Agent 的诊断能力建立在三个技术层的协同之上。
其中,ReAct Agent 解决"怎么让 Service 按流程走而不失控",MCP 解决"怎么统一获取各类运维数据",RAG 解决"怎么调用私域领域知识"。
首先,React Agent 引擎让诊断流程从黑盒走向可控、可观测,它的核心是一个守约素的 Thought -> Action -> Observation 循环:模型先思考并选择工具,引擎经统一的执行工具、把观察结果回注上下文,如此反复,直到产出最终结论或触达部署上线。
这套架构借鉴了高效专家团队的分工模式:规划节点相当于指挥部,只看全局;Sub-Agent 是前线执行者,只处理分配给自己的具体任务。通过这种强制约束,Agent 不再“想到哪算哪”,从架构上根除了上下文污染问题。
按数据域分工的思路也贯穿在工具层。一台服务器出问题,可能同时牵涉内核/配置、运行时指标、主机日志三类性质完全不同的数据。OCAI 没有把它们塞给一个无差别的工具,而是按数据域拆成三组 function-call 工具,由同一个 ReAct Agent 按需调用:
● 配置/静态类(0cm_*,来自 oc-manager):内核模块、补丁、已装包、sysctl/ulimit 等机器画像;
● 时序指标类(ocai_metrics_*,对接时序指标数据):CPU、内存、磁盘 I/0、网络等运行时监控数据;
● 主机诊断类(diagnose_machine 等,走 diaglite/diagagent): dmesg,journal 等事件与现场命令采集。
其中最关键的是时序指标这一组,它直面了 AIOps 公认的难题:能否把原始时序硬塞给大模型?
答案是不能,大模型本质是语义推理引擎,面对海量高频数字,既易撑爆上下文,也缺乏归因能力。OCAI 的解法是:不让大模型做算术题,而是做阅读理解。
时序数据先经服务端按时间桶聚合,再由聚合层收敛成一组特征--min/max/p50/p95/Latest、趋势标签(上升/下降/平稳)、以及超过 p95 的至多个尖峰时刻;交给模型的是特征描述而非原始数字,模型据此做跨指标的关联解读,例如“CPU 在: 10:00-10:05 出现突增,且同期内存有波动"。
最后,RAG 注入私域经验,MCP 打通执行通道。
这三层协同,让 OCManager 跨越了“AI 给建议、人去执行”的旧模式,真正实现了从规划、推理到输出可执行报告的自主诊断闭环。
四、从辅助到闭环:把验证过的工程判断开源
OCManager 的能力落到真实场景中究竟是什么样?以一次 GPU 业务异常的诊断为例。
面对“特定时间点 GPU 业务异常”的输入,在传统的排障模式下,工程师往往要在监控看板查指标、切到日志系统搜报错、再翻文档找原因,在多个系统间来回拼凑信息。
而 Agent 接到诊断指令后,能够实现诊断链条的自动接力:先调度 Monitor Agent 提取指标特征,锁定 CPU 高负载的表象;随即流转至 Log Agent 深挖内核日志,精准捕捉到 Xid 43/31 显存硬件报错。
从表象定位到根因锁定,一次交互完成跨域数据串联,直接输出附带修复命令的诊断报告。
目前 OCManager 的成效已在腾讯内部生产中兑现,但团队并未将其视为完美终局,反而对系统的当前边界有着客观的评估:同样的问题在不同上下文下,AI 给出的答案可能存在差异;更多数据源的接入、多轮交互的支持,都还在后续迭代计划中。
对运维行业而言,“LangGraph + MCP + RAG”的技术组合在讨论层面已经很热,但大多还停留在 PoC 概念验证阶段,真正在生产规模跑通且完整开源的系统屈指可数,开发者极度缺少工程参考。
OCManager 以 GPL-2.0 协议提供了可私有化部署的落地起点,填补了这一空白;同时,它将内核、日志等 OS 数据封装为 MCP Server 开源,也算是向 Agent 生态贡献了 OS 原生的“工具积木”。
OCManager 的开源,本质是把 OpenCloudOS 数百万台服务器验证过的 AIOps 工程判断,转化为整个行业可复用的工程底座。后续的开源规划里,CrashBuddy 内核宕机分析、MCP 工具集扩展……都被写在了路线图上。
“机房里跑什么,它就能管什么”的愿景,正等待开源社区共同兑现。
● OCManager 开源代码仓库:https://gitee.com/OpenCloudOS/ocmanager
● OCM-Agent 开源代码仓库:https://gitee.com/OpenCloudOS/ocm-agent
● OCAI-Service 开源代码仓库:https://gitee.com/OpenCloudOS/ocai-service
● OCAI-Agent 开源代码仓库:https://gitee.com/OpenCloudOS/ocai-agent




