
12 月 19 日,Cursor 宣布将收购代码评审初创公司 Graphite。
Cursor 主要在编写代码阶段为程序员提供辅助;而 Graphite 则聚焦于代码完成之后的流程,帮助团队评审变更、判断代码是否已具备上线条件。Graphite 联合创始人 Tomas Reimers 与 Cursor CEO Michael Truell 的共识是:“AI 的引入意味着会有更多代码被写出来,也就必然意味着,需要被评审的代码只会更多。”
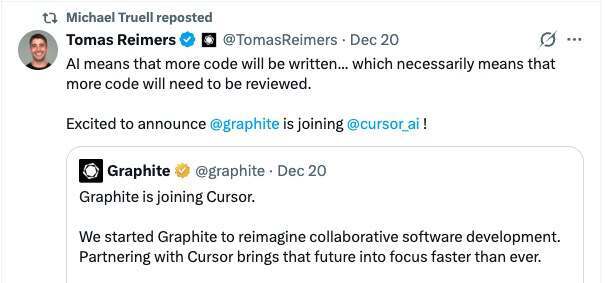
在 AI 大幅加速代码编写的同时,代码评审流程却几乎没有发生变化,反而正在占用工程团队越来越多的时间,这正是这笔交易发生的现实背景。Michael Truell 在一份声明中表示:“在过去 2.5 年里,Cursor 已经让编写生产级代码变得快了很多。但对大多数工程团队而言,代码评审的方式看起来仍然和三年前几乎一模一样。”
Graphite 成立于近五年前,并于今年 3 月完成了 5200 万美元 B 轮融资。这家公司目前为 500 多家企业、数万名工程师提供服务,客户包括 Shopify、Snowflake、Figma 以及 Perplexity AI。
Cursor 目前估值约 293 亿美元。公司由四位 MIT 毕业生于 2022 年创立,近几年增长迅猛,其 AI 编程工具于 2023 年首次发布。就在一个月前,Cursor 宣布其年化营收已达到 10 亿美元,而此次交易也是该公司的第三次收购。此前,Cursor 曾在 2024 年 11 月收购 AI 编程助手 Supermaven,并在同年 7 月从人工智能 CRM 初创公司 Koala 吸纳了一批人才。
对于这次收购,两家公司表示,Graphite 将继续以独立产品形态运营,同时与 Cursor 的代码编辑平台进行更深度的集成。此前,Graphite 本身有 VS Code extension,使用 VS Code、Cursor、Windsurf 编辑器的话,可直接在扩展商店安装 Graphite 。
未来几个月,他们将会加码打造更好的 stack PR 平台和 merge queue;做 Cursor 与 Graphite 之间深思熟虑的集成,把本地开发、background agents、pull request 串起来;利用 Cursor 在 coding models 上的经验让 Graphite 的 AI 功能更聪明;还计划将自家的 AI Reviewer 与 Cursor 的 Bugbot 进行融合,打造“市场上最强的 AI 代码审查工具”。
这笔交易相当于是把 AI 时代“创建、评审、合并代码”的最佳工具组合到了一起。这三件事里,Cursor 实际上只做了其中一件——写代码,另两件则是 Graphite 的强项。交易交割后,整个 Graphite 团队都会加入 Cursor 继续推进相关产品研发。
写代码“一把梭”了,code review 就成了瓶颈
AI 编程工具,可能是整个科技行业里变化最快的一个品类。
所有做过开发的人都知道,代码评审这件事非常不稳定。效果好不好,取决于是谁在 review、他有没有动力、有没有认真看。有时候你只会收到一句 “LGTM(Looks Good To Me)”。而现在,代码生成量暴涨,再加上 LLM 往往不太擅长“简洁”,代码评审反而成了一个被严重低估的关键环节。
根据 Graphite 公司分享的数据,相比 2023 年,现在每位工程师产出的代码量大约多了 70%。主要问题在于,代码可以指数级增长,但工程师的时间仍然是人类尺度的时间。作为一线工程师,你不得不 review 更多内容;作为系统本身,合并队列、merge conflict、自动化 bot 带来的连锁反应也开始堆积,整个合并与交付体系承压明显。
而且,更微妙的变化在于“信任模型”被打破了。过去看到一个 PR,你心里往往会想:“这是熟悉的同事写的,我大概知道他会怎么写、为什么这么写。”但现在,这种确定性正在消失——也许是他写的,也许只是盯着屏幕一直按 Tab 键;甚至在更极端的情况下,这段代码可能从头到尾没有任何人类认真读过,而你恰好成了第一个。
与此同时,上下文正在快速流失。当我们自己写代码时,往往会顺带把代码库的结构、演进脉络这些上下文一起“吸收”进去;而 code review 也会在团队协作中把这部分上下文再“分发”一轮——你在 review 别人的改动时,会重新理解一遍系统为什么这么设计、现在往哪里走。
但如果我们写代码的时候并不是带着很主动、很清醒的思维去写,而是大量内容被半自动生成、再被半机械地接受,那么我们掌握的上下文就会越来越少。久而久之,整个团队会越来越说不清楚:代码库里到底发生了什么、为什么会变成现在这样。这会随着时间推移变成一个非常危险的问题。
因此,code review 系统的负担更重了;合并系统、部署系统也更重了。软件开发的那整套“外循环”(outer loop)正在被挑战、被卡住。
在这种新负载下,很多团队开始意识到:把 agent 当成“自动驾驶”是不现实的,它更像一群“初级、异步、数字化员工”——你可以一次性放出一群去干活,但它们天然缺上下文、缺架构性思考,也更容易在关键细节上“跑偏”。
真正拉开差距的 best practice,反而很朴素:中间可以是 agent,但开头和收尾必须是人。
开头往往需要资深工程师、Staff 级别、经验非常丰富的工程师,把上下文组织清楚(设计文档、约束原则、依赖核对、任务拆解),让 agent 先“读懂再动手”;收尾同样由强工程师把质量关守住(review、CI、回归定位与迭代),确保每一次合并都能解释得清、追得回、兜得住。这也是为什么与 AI agent 协作最有效的,往往是资深工程师:他们不仅能在输入端把问题讲明白,还能在输出端把风险控住。
现在一个很实用的协作模式是:先认真写一份 markdown 设计文档,再把它交给 Claude Code 或 Cursor 执行。但也正因为生成代码变得太容易,让 Claude Code、Cursor 这类工具一次性产出 2000 行、3000 行的 PR 并不难。这种情况下,人类 reviewer 很容易眼睛“发直”,最后又回到那句熟悉的 “LGTM”,或者“我看不完,直接合吧。”
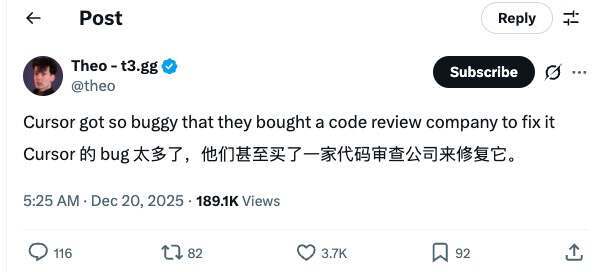
这种“外循环被卡住”的现实,也很快投射到了 Cursor 自己身上。T3 Chat 公司创始人、Cursor 投资人 Theo 在一次分享中直言:Cursor 对“更快交付、构建更多功能”这件事至关重要,但你甚至能从编辑器本身感受到这种压力——“它看起来像是在慢慢散架”。
他提到他上周一还专门带着团队去了 Cursor 办公室,坐下来连续吐槽了两个小时他们在使用过程中遇到的各种 bug。Cursor 团队随后承诺,接下来一段时间将暂缓新功能开发,进入“硬核修 bug 模式”,并且每天同步修复进展:修了哪些 bug、发现了哪些新 bug、下一步准备怎么处理。“他们确实在非常认真地解决这些问题。”他评价道。
也正是在这个语境下,他抛出了 X 上的那句调侃:“Cursor 的 bug 太多了,他们买了一家 code review 公司来修它。”
这当然是个玩笑,但玩笑背后并非没有现实逻辑:当代码生成量暴涨、交付节奏被拉到极限时,代码审核往往成为了系统中的瓶颈,对一个以高频迭代著称的 AI IDE 来说也是一样。
Graphite:继承自 Meta 的 code review 工程方法论
如果只看今天的定位,很容易以为 Graphite 是一家“顺应 AI 浪潮而生的代码评审公司”。但实际上,Graphite 其实完全不是从“代码审查公司”开始的。
这家公司最初做的是一套帮助移动应用 QA 团队的工具,由一群曾在 Apple、Meta(Facebook)等大型科技公司工作过的工程师组成。他们在离开大厂之后,对“熟悉的开发体验突然消失”产生了强烈落差感。
在他们看来,Meta 内部的开发者工具链几乎是“另一个世界”。对没在那套体系里工作过的人,可以用一个直观的对比来理解:GitHub 在 2011 到 2013 年左右定义了 Pull Request 这种协作范式,而 Meta 内部也构建了类似的东西——但不同的是,Meta 从那之后几乎没有停过对这套工具的持续迭代。
而 GitHub 在 code review 这块,“很多东西很久没怎么变了。”在 Tomas Reimers 看来,当他们说“Facebook 的工程工具在创新层面领先将近十年”时,那就是字面意义的“领先十年”。
因此,在他们离开 Facebook、重新回到 GitHub 体系之后,觉得十分不适应。最初,他们只是怀疑自己是不是变挑剔了?但大约六个月后,这种自我怀疑逐渐消失,取而代之的是一个更明确的判断:这不是习惯差异,而是工程工具本身的巨大断层。
也正是在这个阶段,他们开始问一个问题:如果那套被验证过的开发体验如此之好,有没有可能把它重新做出来?
于是团队开始一点一点为自己搭工具,这套内部工具后来被叫做 Pancake,完全是为内部使用而生的:代码里写死了仓库名、GitHub handle,很多逻辑都是围绕团队自身的工作流设计的。
随着越来越多前 Meta 的同事离开大厂,加入创业公司或新团队,一个问题开始反复出现:“外面的 code review 怎么和记忆里的完全不一样?”最后他们往往会找 Tomas Reimers 团队聊起自己曾经习惯的那套评审体验,并希望他把团队内部正在使用的工具开放出来,让他们也能直接用上。
最终,2021 年 11 月,团队做出了转型决定:把 Pancake 从一个高度定制的内部工具,打磨成一款真正对外的代码评审产品。那是一段高度集中的工程冲刺期——需要把所有“写死在内部场景里”的假设逐一剥离,把只服务自家工作流的工具,改造成任何团队都能接入、可规模化运行的系统。
为什么是 stacking
Graphite 的核心理念,并不是某种“全新的 AI 发明”,而是一套早已在超大规模工程组织中被反复验证的模式:stacked diffs。
Tomas Reimers 在 Meta 工作了两年半,他对 stacking 的解释非常直白:“作为一种方法论,stacking 让开发者能够绕开对 main 分支的依赖所带来的延迟,从而实现真正的、持续的并行开发。”
传统的 Git 工作流,往往把每一个功能等同于一个 PR:一个 PR 对应一个分支,由多个 commit 组成。典型的、非 stacking 的流程是这样的:完成一个功能、提交一个 PR、等待 PR 被评审、通过后合并回 main。
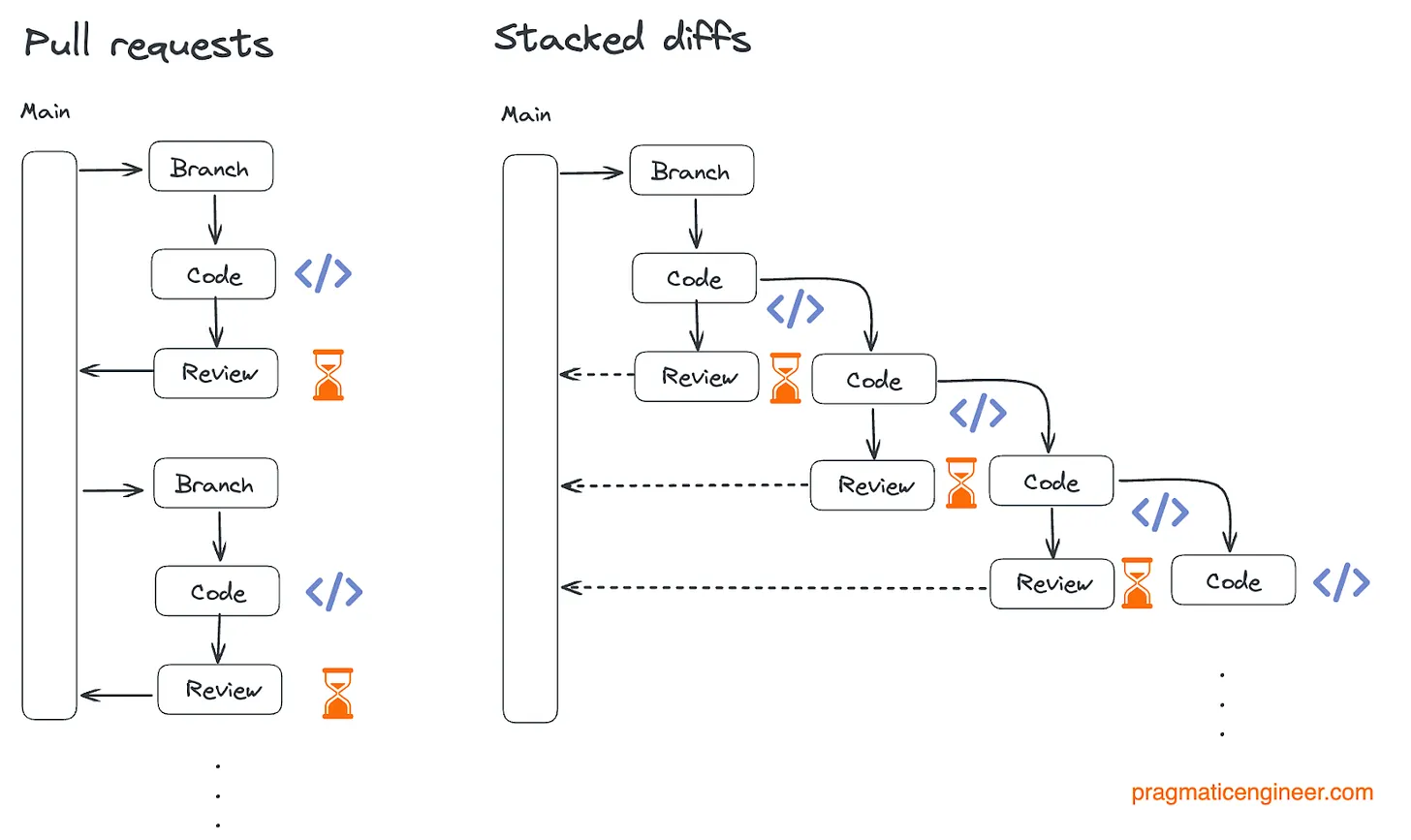
Pull Request 与 stacked diffs 工作流上的差异
一旦 PR 合并完成,你就会开始下一个功能,于是再次从 main 拉分支继续开发。哪怕流程再顺,这个节奏依旧很慢,PR 往往会在等待评审的状态下停留数小时甚至数天。他们甚至分析过 1500 万个 PR 的历史数据,发现有些 PR 会“等上好几年才合并”。
Stacking 的核心变化在于:把变更的基本单位从 PR,变成了单个 commit。在 stacking 模式下,你会把一个大的改动拆成许多个小改动。每一个改动——也就是一个 commit——都可以被单独测试、评审、合并,甚至单独回滚。
这些由小改动组成的集合,也就是所谓的 stack,可以一层一层地持续构建。工程师可以在不被阻塞的情况下持续向前推进。举个很现实的例子:你经常会在完成一个功能之后,立刻想基于它继续做下一个功能。在 stacking 模式下,你不需要等第一个功能被评审、合并完成,就可以直接在它之上继续工作。
“如果两个人同时提交 5000 行代码,冲突概率极高。如果两个人都在小步快跑,问题会少得多。”
在 Graphite 里 AI review 的规则是“最多 review 100 行代码”。Tomas 表示他们的判断是:“超过 100 行,基本已经是一次重构了,不适合做 AI review。 ”
他认为这也是 stacking 的意义:PR 大了,就该拆。甚至对 AI Agent 来说,“Stacking 也在帮它压缩上下文”。
当你开始让 coding agent 去堆叠改动、把一个大任务拆成很多小 PR,它会开始在这些 stacks 之上应用一种“链式思考”。你能看到它会自己拆步骤:“好,先写函数;然后写单测;然后在其上加 endpoint……”它开始模块化、逐步测试、逐步推出。而且事实是:AI 这样做出的结果往往比你让它“一把梭”生成一个大 PR 更好。
如果出现 merge conflict ,Graphite 会把你直接带进 Git 的冲突解决流程里,把冲突文件修好之后,它会继续帮你把 stack 后面的 rebase 都跑完,同时也会将这些历史都记录下来。
另外,在评审反馈上,据 Graphite CTO Greg Foster 的说法,他们很大一部分的工作就是:
“拿一些非常强的模型(我们不会自己训练模型),可能来自 Anthropic、Gemini、OpenAI 这些公司,有时候也会混用几家模型。我们把 diff 喂进去;再把用户自定义的规则和风格指南也喂进去;再把之前上传/下载过的评论也一起纳入;把这些东西拼起来,然后尽量在 PR 上给出有价值的反馈。”
特别优化的方向,是留下可执行、可落地的行内评论(actionable inline comments)。Greg 强调,如果对某个问题没有足够把握,Graphite 会选择尽量保持安静。因为在这类新兴 AI 工具里,“信任”是硬通货:信息对了当然很好,但错一次就会迅速消耗耐心。因此他们宁愿少打扰,也要确保一旦开口,就“值得你停下来读”。
写在最后
从历史上看,stacking 模式本身并不新。早期 Linux 内核通过邮件往返 patch,本质上就是最原始的 stack;更早还有 IBM 在 1970 年代提出的 Fagan Review:工程师把代码打印出来,技术负责人逐行审,结果 bug 数量显著下降。后来是 Google 的 Mondrian,再到 GitHub Pull Request。
真正变化的不是工程原理,而是协作“原语”的重心:行业逐渐从以 commit 为单位,滑向了以 branch / PR 为单位。Graphite 所做的,也不是颠覆 Git,而是把 Git 原本就隐含的“堆叠视角”重新拉回到工程协作层面:让改动足够小、可独立 review,并且能更顺滑地推进合并与交付
它最典型、也最成熟的落地之一正是 Facebook / Meta 的工程文化。Meta 和 Google 这类少数不依赖 GitHub 的公司,长期形成了相似的工具模式:stacking、inbox、精细化 merge queue、动态 CI……
这些方法存在了十年以上,过去只有处理百万级提交的组织才“被迫”把它们用到极致;但在 AI codegen 把改动量抬上来之后,越来越多团队也开始遇到同样的外循环瓶颈——这正是 Cursor 选择收购 Graphite 的意义。
即便最终只是一支擅长 code review 的团队加入 Cursor,帮 Cursor 把产品打磨得更好,建立一个流程,避免他们继续频繁发 bug——那这笔收购都值了。如果他们能真正改变整个流程:从“我有个想法”→“我去实现”→“我发起评审”→“我合并上线”,把这整条链路都拉顺,那可能会是巨大的变化。
参考链接:
https://fortune.com/2025/12/19/cursor-ai-coding-startup-graphite-competition-heats-up/
https://www.youtube.com/watch?v=xWf6zkw2Ni0
https://www.youtube.com/watch?v=VeRQuEmLTUM
https://www.youtube.com/watch?v=7iNfTgF2hfg




