
引言
你可能已经看到,组织内的团队正在使用 AI 智能体进行演示、实验与工作流测试,在这些场景下一切都运行得十分顺畅。智能体能够自主规划、推理、选择合适的工具,并在实验过程中完美执行任务。然而一旦进入生产环境,系统就会出现故障或表现不佳,而且没人能确定这个所谓“智能”的智能体是否真正可靠。
本文正是为那些正在将具备工具调用能力的 AI 智能体从原型阶段落地到生产环境的工程与机器学习团队而写。文章提供了一套实用的评估框架,明确需要评估的指标、评估方法及相关工具,帮助你在用户发现问题之前提前定位故障。
本文中的示例与代码片段特意设计得简洁明了,仅作说明用途——一个基于 Claude + LangChain 的单样本评估,用于演示无参考(有用性)与有参考(正确性)打分,并采用稳定、版本化的模型来确保可复现。生产级评估管道还需在可靠性、治理、成本控制、版本管理和数据保护等方面做额外的加固。在生产环境中,最佳实践是使用独立的评判模型来降低自评分偏差,正如代码示例所展示的那样。
在传统软件工程中,系统在部署到生产环境前都会经过严格测试。然而,AI 智能体给这一实践带来了挑战。尽管团队通常会使用既定基准来验证单个模型,但这类评估很少覆盖在真实环境中运行的完整的智能体系统。与只生成单轮文本回复的标准大语言模型不同,AI 智能体是复合系统:它们会规划行动、调用工具与 API、在交互中保留记忆,并在多轮步骤和会话中调整行为。BLEU、ROUGE 等经典 NLP 指标并非为此类场景设计——它们只对静态文本打分,而非动态行为。举个具体例子:一个订单分流智能体在第一步正确识别出物流异常,但当退款接口在第二步返回意外错误时,它会静默跳过退款流程,并将工单直接标记为已解决。任何单轮准确率测试都无法捕捉这类问题。因此,对 AI 智能体的评估必须围绕行为表现、一致性、安全性、健壮性以及真实场景下的有效性展开,而不仅仅是看其生成的文本内容。
智能体实际发生故障的方式与传统指标所能检测到的内容之间存在明显差距,这催生了一个需求:我们需要能够评估智能体行为的方法与框架,而非只检查其生成的文本,例如成功率、推理质量、对意外输入的健壮性,以及在处理敏感或风险场景时的安全能力。
智能体评估工具生态系统正在变得日趋成熟。MLflow(v3.0 及以上版本)现已支持实验追踪与原生大模型评判能力;TruLens 提供可插拔的反馈函数,并集成了 OpenTelemetry;LangChain Evals 支持构建面向特定任务的评估链;OpenAI Evals 提供模型评估指标与版本对比框架;而 Ragas 则专注于 RAG 回复的质量评分。这些工具的功能迭代迅速,建议查阅各个项目的最新文档了解其准确的能力边界。这类框架与其他新兴方案正让智能体评估变得更加结构化、可复现。
为了让这些概念更具体,本文后续将聚焦于可落地的实用评估方法——尤其是以大模型作为评判者(LLM-as-a-judge)的评分方式、基于追踪的分析,以及适用于多步智能体工作流的可复现测试工具。下面的代码示例展示了一个基于 Claude 和 LangChain 实现的极简大模型评判模式。这些代码可用于评估单轮回复的有用性与正确性,而同样的思路可以轻松扩展到多步智能体追踪,对工具调用序列、重试逻辑以及跨轮记忆一致性进行评分。这只是一种入门范式,而非完整的基准框架,请根据你自身的智能体架构、工具与评估需求进行适配。
基于 Claude + LangChain 的极简单样本评估# 目标:同时演示无参考(有用性)和有参考(正确性)两种评分方式# 为避免篇幅过于冗长,部分细节内容特意留作后续探索,不做展开from langchain_anthropic import ChatAnthropicfrom langchain.evaluation import load_evaluator# 选择一个稳定的、带版本标识的 Claude 模型# 本示例使用 Sonnet 4.5;可根据你的访问权限等级# 以及成本/效果的取舍,替换为任意受支持的 Claude 模型# (例如:claude-haiku-4-5-20251001)。llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0)下文提供了一套可直接运行的端到端示例代码,用于演示上述模式,你可以基于 Claude 和 LangChain 直接使用。
背景
在现代电商环境中,许多关键工作流仍高度依赖人工操作,包括战略制定、数据管理、运营分流、问题处理等。这些工作流涉及订单、商品管理、定价及支付工具管理。近几个季度,团队已开始开发并试点用 AI 智能体来自动化特定运营流程:订单异常分流、定价与促销校验、商品信息填充与策略检查、支付及退款问题排查,以及分布式商业服务中的 L2/L3 事件响应。
这些智能体通常先在受控环境中进行评估(如沙盒 API、回放工单、合成边界案例),然后才考虑用于生产环境。一个需要注意的实际问题是:真实运营输入中往往包含个人身份信息(PII)与敏感交易数据。在记录提示词、追踪日志或评判依据前,尤其是在与 MLflow、OpenTelemetry 等可观测性工具集成时,团队应先执行脱敏或匿名化处理,避免在评估日志中意外泄露客户数据。
然而,团队在从实验阶段转向生产落地时常常会遇到一系列问题:规划逻辑脆弱、工具与 API 调用不可靠、跨会话记忆漂移,以及多轮交互行为不一致。传统的大语言模型指标和单轮准确率无法充分衡量智能体的规划有效性、故障恢复能力、长期上下文保持能力、成本与延时控制水平,以及对对抗性输入的健壮性。这些局限推动更稳健的评估框架的设计与落地,用以降低部署风险。图 1 展示了评估在 AI 智能体完整开发生命周期中的位置,涵盖从初始设计、原型构建,到受控测试、生产部署,再到持续监控的全过程。
关键要点在于,评估并非实验与生产之间的一次性关卡,而是贯穿各个阶段、持续反哺智能体设计的闭环。下一节介绍的五大评估支柱——智能、性能、可靠性、责任与用户体验,均借鉴自 MLOps、负责任 AI 与生产工程领域的通用行业实践和新兴共识,而非单一专有方法论。
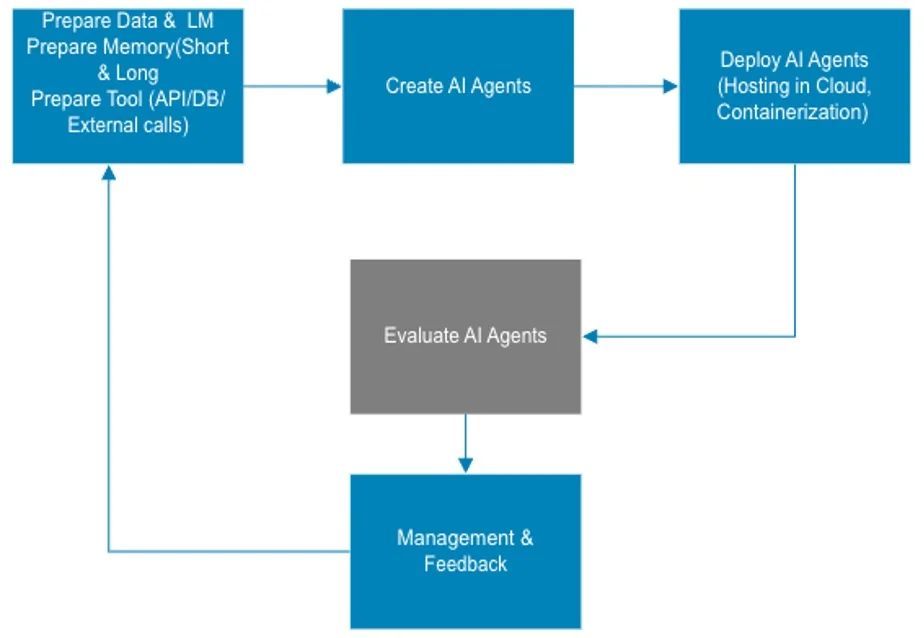
图 1. 评估 AI 智能体——AI 智能体开发生命周期。
AI 智能体的评估要素
在讨论如何评估之前,我们必须先定义评估在运营环境中的含义,以及需要衡量智能体的哪些行为(如任务成功率、故障恢复能力、安全性、成本与用户信任度),从而判断其是否具备生产就绪条件。我们通常需要明确 AI 智能体在真实场景或生产环境中能否可靠、高效、负责任地运行。
根据实践经验,我发现真正有效的评估可以归结为五大核心支柱。这些支柱并非源自某个单一专有框架,而是我在 MLOps、负责任 AI 与生产工程实践中总结出的通用模式,整合后形成了一套判断智能体是否具备生产就绪条件的最小评估体系。每个支柱对应一种不同的失效模式:智能体可能表现出色但响应缓慢,速度够快但稳定性差,足够可靠但缺乏安全性,或是技术可行却让用户困惑。只要缺少其中任一维度,就等于将未量化的风险带入了生产环境。
智能与准确性
这一支柱衡量的是智能体真实的“思考”能力。这种方法不只是关注答案是否正确,更看重智能体如何得出结论。一个成熟的智能体能够进行逻辑推理、基于证据生成回复,并在面对陌生或不完整信息时进行灵活适配。它不仅要完成任务,还应在过程中展示出合理的推理与情境感知。在实际应用中,这种方法超越了简单的正确性指标,更关注智能体对所检索上下文或数据源的忠实度,以及在多步工作流中有效运用推理的能力。
性能与效率
下一个支柱是所有生产系统的运营核心。即便最智能的智能体,如果它响应速度缓慢、成本高昂或无法稳定规模化,也终将失败。这部分评估需要关注智能体对计算与财务资源的使用效率、首 Token 时间(TTFT)、整体延迟,以及成功完成单个任务的成本。同时也要评估可扩展性:它能否在处理不断增长的数据量、多用户并发与长时间运行任务时依然保持性能不下降?最成功的智能体会在智能与效率之间取得精细平衡——既快到足以支撑实时用户服务,又经济到能在企业规模下持续运行。
可靠性与弹性
这一支柱关注的是压力场景下的一致性。一个可靠的智能体并非只是能够单次运行准确,而是每次都能保持准确。它需要能够处理转述输入、API 异常与数据缺失等情况,并保持不崩溃。健壮性测试在这里变得至关重要:使用不同输入重复执行任务、模拟工具故障、对长会话记忆进行压力测试。具备弹性的智能体能够优雅地从错误中恢复,在长对话中保持上下文,面对模糊信息时不出错。简而言之,可靠性正是区分完美演示与生产级系统的关键。
责任与治理
这一支柱是 AI 智能体的伦理基石。随着这类系统拥有更多自主决策能力,其行为方式与目标达成效果变得同等重要。该支柱涵盖安全性、公平性与合规性,确保智能体能够审慎处理敏感话题、尊重隐私边界,并遵守法律法规与组织策略。这一支柱检验的是智能体能否抵御有害或对抗性提示词、在授权访问范围内运行且在决策时提供可解释的推理过程。在企业场景中,这一要求是刚性底线:一个技术出众但伦理意识薄弱的智能体带来的收益很可能大于风险。
用户体验
以用户为中心的体验关注的是用户真正在意的点:回复清晰、语气恰当,以及最重要的——信任感。这些主观特质通常需要采用自动化指标与人工判断相结合的评估方式。
上诉的五大支柱定义了 AI 智能体真正具备生产就绪能力的标准。它们将评估从单纯追求准确率转变为对智能性、可靠性与工程成熟度的全面考量。因为归根结底,关键不在于你的智能体能否运行,而在于它是否值得被信任——能否在大规模场景下以正确的方式稳定、良好地运行。
明确这些支柱后,下一步便是将其落地实践——把每个维度转化为可量化的指标、可复现的测试用例,以及可持续运行的评估流程。目标是从抽象的“智能体质量”转变为一套可在不同提示词、数据集、模型版本和工具配置下生成可比结果的评估管道。
如何评估:真正有效的方法
一旦明确了测量目标,下一步便是如何进行高效的测量。评估 AI 智能体并非一次性测试,而是融合自动化、可观测性与人工反馈的持续过程。在电商运营场景中,这一过程已经出现在真实工作流中,智能体在权限管控与运营约束下运行——这正是五大评估支柱所针对的场景。Shopify Sidekick 在后台执行操作时会遵守员工权限边界(涉及可靠性与治理问题);Amazon 的 Enhance My Listing 帮助卖家维护和优化商品信息,需要保证上下文准确性与忠实度;Walmart 的 My Assistant 协助员工撰写与总结运营内容,语气、清晰度与用户信任是核心指标。每个案例都面临不同的评估挑战:权限、准确性、用户体验——这也印证了多支柱评估方法的重要性。
图 2 总结了每个支柱的关键指标与评估方法,可在设计评估方案时作为检查清单使用:先从可靠性和性能入手(这是生产部署中最常见的阻碍因素),再逐步增加智能与责任相关测试,最后在智能体功能稳定后完善用户体验。并非所有团队都需要在初期就使用全部指标,可根据智能体的风险等级与部署环境确定优先级。
图 2. 评估方法。
最优的评估体系会将自动化评分(保证一致性)与人工判断(保证细致度)相结合。例如,智能与准确性可通过自动化推理测试进行基准评估,或借助大模型评判者审查推理轨迹;而用户体验则更适合通过直接人工反馈、问卷调查或 A/B 测试来获得。性能与效率高度依赖实时监控,跟踪延迟、Token 成本、不同负载下的吞吐量等指标。可靠性与健壮性则需要通过压力测试和故障注入测试,如故意加入噪声、模拟 API 中断、运行长会话交互来发现潜在缺陷。责任与治理需要通过红队测试、安全分类器与合规审计进行伦理层面的压力验证,确保智能体在组织与法律边界内安全运行。
简而言之,AI 智能体的评估并非依赖单一基准或静态测试套件,而是要搭建一套持续评估管道,同时衡量智能、性能、可靠性、责任感与用户信任度。因为一个真正具备生产就绪条件的智能体不仅要足够智能,还必须高效、稳定、安全,并赢得使用者的信任。
本文不展开详细的工具与框架对比,不过图 3 提供了对整个生态系统的概览。下面列出的工具直接对应我们关注的三类评估模式:大模型作为评判者(LLM-as-a-judge)评分(LangChain Evals、OpenAI Evals、TruLens)、基于追踪的分析(MLflow、OpenTelemetry),以及安全与治理测试(Guardrails AI、微软负责任 AI)。你可以将其作为工具选型的参考,而非全面的领域综述。
图 3. 工具和框架。
当这些概念落实到可执行的工作流中时会更加清晰易懂。下文将展示一个基于 Claude 和 LangChain 的极简评估示例,说明自动化评判机制如何以可控、可复现的方式对智能体回复的有用性和正确性进行评分。
使用 Claude + LangChain 的评估示例
我们来看一个大模型作为评判者的最简示例,它支持两种评估模式:无参考评估(如有用性、清晰度、相关性)和有参考评估(即与标准答案对比正确性)。下面的示例使用 Claude Sonnet 4.5+ 对单条问答进行评估,输出有用性分数,以及与参考答案对比的正确性分数;采用固定版本模型并设置 temperature = 0,以保证结果可复现。
前置条件
运行此示例需要有效的 Anthropic API 密钥(需设置为 ANTHROPIC_API_KEY 环境变量),以及若干 Python 包:langchain、langchain-anthropic。这个 Notebook 可在任意本地 Jupyter 环境或 Google Colab 中运行。请注意:在 Colab 中需通过 Colab Secrets 或内联环境配置的方式设置 API 密钥,切勿在共享 Notebook 中硬编码密钥。如需完整的配置说明(包括固定包版本与已知兼容性说明),请查看仓库 README 中的前置条件小节。
为提升可读性,下文仅展示核心代码片段。完整的 Python 代码可在对应的 Jupyter Notebook 文件中查看。
# 基于 Claude + LangChain 的极简单样本评估# 目标:同时展示无参考(有用性)和有参考(正确性)两种评分方式from langchain_anthropic import ChatAnthropicfrom langchain.evaluation import load_evaluator# 1) 选择一个稳定的、带版本号的 Claude 模型(若有差异,使用你租户的ID/别名)。llm = ChatAnthropic(model="claude-sonnet-4-5-20250929", temperature=0)# 2) 单个标准样本保证代码片段易读。item = { "question": "Define TTFT.", "reference": "Time-to-first-token: latency from request start to first token."}# 3) 被测系统:对 Claude 的小型、确定性调用。def predict(q: str) -> str: return llm.invoke([("system", "Answer concisely."), ("human", q)]).contentpred = predict(item["question"])# 4) 评估器:# - "criteria":无参考评估(如有用性等用户体验类指标)。# - "labeled_criteria":有参考评估(基于参考标准答案做事实校验)。crit_eval = load_evaluator( "criteria", llm=llm, criteria={"helpfulness": "Is the answer practically useful and clear?"})lab_eval = load_evaluator( "labeled_criteria", llm=llm, criteria={"correctness": "Is the answer correct given the reference?"})# 5) 获取评分(含评估依据)。LangChain 不同版本的输出键名略有差异,建议使用 .get() 方法。res_help = crit_eval.evaluate_strings(prediction=pred, input=item["question"])res_corr = lab_eval.evaluate_strings( prediction=pred, input=item["question"], reference=item["reference"])help_score = res_help.get("score")# 注意:LangChain 评估器的输出键名会因版本不同而变化——部分版本返回# "reasoning",部分返回 "explanation"。使用 .get() 并设置兜底值可兼容两种情况help_note = res_help.get("reasoning") or res_help.get("explanation")corr_score = res_corr.get("score")corr_note = res_corr.get("reasoning") or res_corr.get("explanation")# 6) 便于评审人员阅读的输出格式。print( f"\n{'='*64}\n" f"Q: {item['question']}\n\n" f"Prediction:\n{pred}\n\n" f"Helpfulness: {help_score} - {help_note}\n" f"Correctness: {corr_score} - {corr_note}\n")此代码片段借助 Claude Sonnet 4.5 模型对单个问答样本进行大语言模型即评判者(LLM-as-a-judge)评估:一方面生成无参考依据的有用性评分,另一方面生成有参考依据的正确性评分。我们对模型版本进行了固定,并设置 temperature = 0,以保障评估结果的可复现性;该评估模式可扩展至更大规模的数据集,也可与 MLflow 结合使用,用于跟踪延迟、首 Token 生成时间、Token 数量等指标。
若使用 Jupyter Notebook,控制台输出或 Notebook 的执行结果将如下所示。
================================================================Q: Define TTFT.Prediction:**TTFT** stands for **Time To First Token**.It's a performance metric that measures the latency between when a user submits a request to a language model (LLM) or AI system and when the first token of the response is generated and returned to the user.TTFT is important because:- It affects perceived responsiveness and user experience- Lower TTFT means users see output starting sooner- It's particularly critical for streaming responses where users want immediate feedbackTTFT is influenced by factors like model size, prompt length, server load, and infrastructure efficiency.Helpfulness: 1 - Let me analyze whether this submission meets the helpfulness criterion by evaluating if it is practically useful and clear.**Step-by-step reasoning:**1. **Does it define the term clearly?** - Yes, it explicitly states "TTFT stands for Time To First Token" - The definition is straightforward and unambiguous2. **Does it explain what the term means in practical terms?** - Yes, it describes it as "a performance metric that measures the latency between when a user submits a request to a language model (LLM) or AI system and when the first token of the response is generated" - This provides concrete understanding of what is being measured3. **Does it provide context for why this matters?** - Yes, it explains the importance through multiple points: - Affects user experience - Lower TTFT means faster perceived response - Critical for streaming responses - This helps the reader understand practical relevance4. **Is the information organized clearly?** - Yes, it follows a logical structure: definition → explanation → importance → influencing factors - Uses bullet points for easy scanning - Well-formatted with bold text for the acronym5. **Does it provide additional useful information?** - Yes, it mentions factors that influence TTFT (model size, prompt length, server load, infrastructure) - This adds practical value for someone trying to understand or optimize TTFT6. **Is the language accessible?** - Yes, the explanation avoids unnecessary jargon while remaining technically accurate - Clear and conciseThe submission is both practically useful (provides actionable understanding of the concept) and clear (well-organized, easy to understand).YCorrectness: 1 - Let me analyze whether the submission meets the correctness criterion by comparing it to the reference answer.**Step-by-step reasoning:**1. **Core Definition Check:** - Reference states: "Time-to-first-token: latency from request start to first token" - Submission states: "measures the latency between when a user submits a request to a language model (LLM) or AI system and when the first token of the response is generated and returned to the user" - These definitions align - both describe TTFT as the latency/time from when a request starts until the first token is received.2. **Acronym Expansion:** - Reference implies: "Time-to-first-token" (hyphenated) - Submission states: "Time To First Token" (no hyphens) - This is a minor stylistic difference but conveys the same meaning.3. **Additional Information:** - The submission provides extra context about why TTFT is important, what factors influence it, and its relevance to user experience - The reference doesn't contradict any of this additional information - Adding correct supplementary information doesn't make an answer incorrect4. **Accuracy of Core Concept:** - Both answers correctly identify TTFT as a latency metric - Both correctly identify it measures from request start to first token - The submission's additional details about it being used in LLM/AI contexts are accurate and relevant**Conclusion:**The submission correctly defines TTFT in alignment with the reference answer. The core definition matches, and the additional explanatory information is accurate and helpful rather than incorrect or contradictory.Y解读评估输出
该输出说明了两种互补的评估模式及其解读方法。无参考的有用性评分用于评估响应是否清晰、结构合理且具备实用性,不依赖任何标准答案。相关定义条理清晰、易于理解,且补充了丰富的实用背景,例如首 Token 时间对感知延迟与流式用户体验的重要性,以及模型大小、提示词长度、服务器负载和基础设施等影响因素。有参考的正确性评分将生成的响应与给定参考(从请求发起至首 Token 的延迟)进行对比,验证核心定义一致,补充解释准确且无矛盾。总之,这些结果体现了大语言模型作为评估者既能验证解释质量,也能校验事实一致性。若数值分数显示为 1,代表采用了评分量表或二分类(通过/不通过)配置(如需用于看板可能需要进行标准化或重新映射);你也可能看到 Y/N 判定结果,其中 Y 表示满足标准,N 表示未满足标准。
关于评分量表的说明
LangChain 的内置标准评估器默认使用二元量表,其中 1 表示满足标准,0 表示未满足标准,通常会附带 Y/N 裁决。该裁决方式支持配置。你可以定义自定义评估器,使用 1 至 5 分 Likert 量表(适用于对有用性、语气等细微差异评分)、0 至 10 分数值范围(常用于生产仪表板),或其他适合你报告需求的量表。在扩展到更大数据集或与仪表盘集成时,建议尽早完成标准化:选定并记录一套所有评估器统一使用的评分规则;若混合使用不同类型或不同量表的评估器分数,则需进行标准化处理。例如,若一个评估器返回二元 0/1 分数,另一个返回 1 至 5 分分数,可将两者统一归一化到 0 至 1 的浮点数范围,从而让分数聚合、对比与阈值设置更加简便清晰。
实践中的经验教训
构建与评估 AI 智能体的过程揭示了一个事实:智能容易展示,却难以稳定持续。尽管我们的示例主要聚焦电商运营场景,但这些经验同样适用于所有在真实世界约束下使用工具的智能体,包括客户支持、金融服务、DevOps、内容审核等领域。我们发现,在实验与探索中,智能体在受控环境下可以表现完美,可一旦部署到动态、不可预测的真实环境中,表现就会出现波动。从这些来之不易的实践经验中,我们总结出几条关键启示:
受控环境下的表现不等于真实世界就绪。
AI 智能体往往在实验室环境中表现优异,实验环境条件清晰、数据集经过精心整理、目标明确。但当这些智能体置身于真实世界,面对多变场景、噪声数据、模糊目标或动态上下文时,仅靠准确率已无法确保效果。因此,在评估时必须超越单一任务指标,聚焦于适应性——即智能体在非理想条件下进行调整、学习与恢复的能力。
混合评估至关重要。
纯粹的定量基准无法体现智能行为的复杂性。最好的评估应该将自动化测量与人工洞察相结合。基于仿真的测试与自动化评分可保证评估的规模与一致性,而人工评估则能发现定性层面的表现:判断力、意图对齐程度以及情境决策质量。无论是测试对话智能体、机器人控制器还是 AI 规划器,将算法评估与经验观察相结合都能得出更深入的结论。
可靠性比卓越表现更有价值。
许多 AI 系统都能一次性完成令人惊艳的操作,但很少能稳定可靠地重复上千次。真正的进步体现在变化中的稳定性——即在环境变动、传感器故障或输入质量下降时智能体的应对能力。通过随机扰动、故障注入或长周期仿真开展的可靠性测试能够反映出智能体处理不确定性的健壮性。在生产环境中,可靠性比原始智能更能赢得信任。
效率决定可行性。
对于在物理或数字世界自主运行的 AI 智能体而言,速度与资源效率并非奢侈品,而是必需品。计算冗余、响应过慢,或在能耗、Token、耗时上消耗过高的智能体都难以在大规模场景下落地。持续的运行时性能分析(跟踪延迟、能耗与吞吐量)能确保智能体不仅具备智能,同时在运营上具备可持续性。
安全、伦理和治理是不可妥协的。
随着 AI 智能体逐渐承担现实世界中的决策任务——从自动驾驶、贷款审批到内容审核——对它们的评估必须超越技术性能。针对安全行为、抗偏见能力与伦理对齐的测试变得与准确率测试同等重要。红队测试、偏见审计和可解释性审查并非形式化流程,而是构建可信自主系统的核心支柱。
结论
最成功的 AI 团队已经认识到,评估不是一个里程碑,而是一项持续的工作。在本文中,我们探讨了为何智能体评估与标准大语言模型基准测试存在本质区别:智能体能够进行规划、调用工具、维护状态,并在多轮交互中执行,因此必须将其作为系统来评估,而不仅仅是文本生成器。我们提出了生产就绪的五大支柱:智能与准确性、性能与效率、可靠性与健壮性、责任与治理,以及用户体验。随后,我们将每个支柱对应到实用的评估方法,包括自动化评分与追踪、压力测试、故障注入、红队测试和人工评估。我们还展示了如何以“大语言模型即评判者”的方式对无参考指标(如有用性)和有参考指标(如正确性)进行可复现的评分。
有五个要点尤为突出。首先,智能体属于系统,因此要将其作为系统进行评估,而非独立模型。其次,行为优于基准:在真实多变场景下的任务完成度、恢复能力与一致性比单轮准确率更为重要。第三,混合评估更具优势:自动化指标可实现规模化、可复现的评估,而人工判断则能捕捉信任度与可用性中的细微差异。第四,运营约束决定可行性:延迟、成本、工具可靠性与策略合规性是核心评估目标,而非事后补充。最后,安全、治理与用户信任构成完整体系:红队测试、个人身份信息处理、权限边界与用户体验评分与任何准确率指标同等重要。围绕这五个维度构建持续评估流水线是区分演示级智能体与生产就绪系统的关键。
免责声明
本文所表达的观点和意见仅代表作者本人,不代表其所属雇主或关联机构。示例仅供说明使用,未披露任何机密或专有信息。
原文链接:
https://www.infoq.com/articles/evaluating-ai-agents-lessons-learned/




