
大规模部署大语言模型(LLM)极具挑战性。现代 LLM 的参数规模已远超单块GPU甚至单个多 GPU 节点的内存与计算能力。因此,针对 70B+、120B+参数模型的推断工作负载或具有超大上下文窗口的流水线,必须采用多节点、分布式 GPU 的部署方案。
这一挑战正推动推理技术栈的创新,Dynamo应运而生。Dynamo 是一个开源的分布式推理框架,可跨 GPU 和节点统一管理执行流程。它将推理过程拆分为多个阶段(如 prefill 和 decode),并分离内存密集型与计算密集型任务。同时,Dynamo 能动态调度 GPU 资源,在提升资源利用率的同时保持低延迟。
借助 Dynamo,基础设施团队可灵活扩展推理容量,有效应对流量高峰,而无需长期过度地配置昂贵的 GPU 资源。该框架兼容任意的推理引擎,支持TensorRT-LLM、vLLM、SGLang等,为企业提供充分的技术选型自由度。
最近,Microsoft Azure 与 NVIDIA合作展示了开源的 NVIDIA Dynamo 框架。此次合作证明,通过任务解耦(disaggregation)、智能缓存和动态资源分配,可在 Kubernetes 上高效运行高性能 AI 工作负载。在最新发布的报告中,作者详细介绍了如何在 Azure Kubernetes Service(AKS)集群上部署 Dynamo,并运行于专为机架级扩展设计的 ND GB200-v6 虚拟机实例,即每台配备 72 颗紧密集成的 NVIDIA Blackwell GPU。
他们使用该配置运行开源的 120B 参数模型GPT-OSS 120B,并采用经过验证的“InferenceMAX”配方,实现了每秒 120 万 token 的吞吐量,充分证明 Dynamo 能够在标准集群上胜任企业级推理任务。
此次部署完全基于标准云原生工具:GPU 节点池、Helm(用于部署 Dynamo)以及 Kubernetes(用于编排)。这表明企业无需定制化基础设施即可从 Dynamo 中获益。
Dynamo 的核心创新在于将 LLM 推理的 prefill 阶段与 decode 阶段解耦,分别部署到不同的 GPU 上:Prefill 阶段处理输入上下文,属于计算密集型;Decode 阶段生成输出 token,属于内存密集型。通过分离这两个阶段,系统可针对各自特性独立优化,例如配置不同数量的 GPU、采用不同的并行策略。
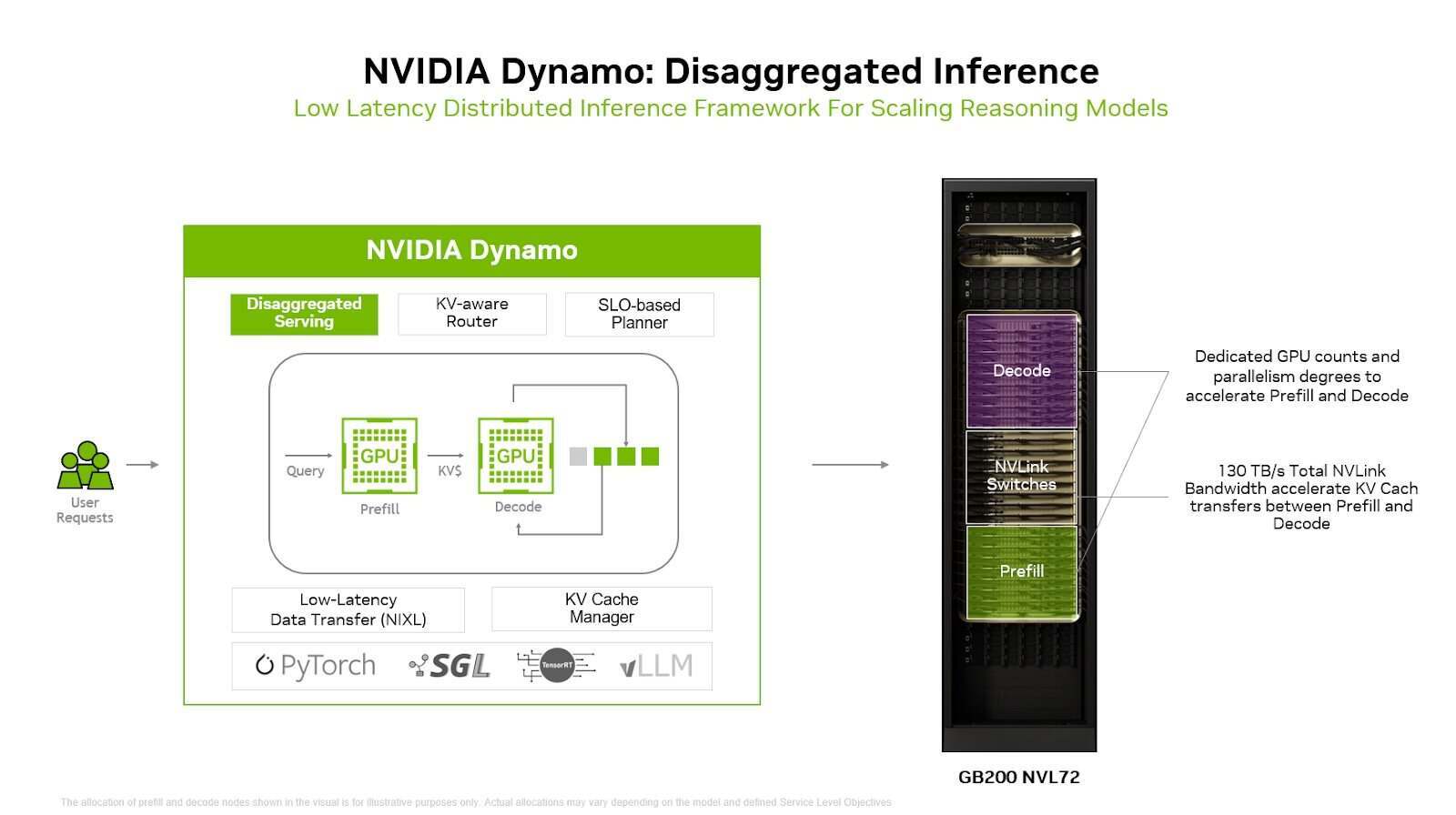
这种架构解决了推理场景中的一个常见痛点。以电商应用为例:生成个性化商品推荐时,可能需要处理数千个 token 的用户与商品上下文(重 prefill),但仅输出 50 个 token 的简短描述(轻 decode)。若将两类任务放在同一 GPU 上执行,会造成资源浪费。而采用解耦式服务后,prefill GPU 专注高算力任务,decode GPU 则聚焦内存带宽与容量,实现资源最优分配。
Dynamo 还具备动态 GPU 调度能力,可根据实时流量变化调整资源。其内置的 Planner 组件基于 SLA 目标,利用时间序列数据预测流量趋势,并动态调整 prefill 与 decode 工作节点的 GPU 分配,以满足关键延迟指标,如“首 Token 时间”(Time to First Token)和“Token 间延迟”(Inter-Token Latency)。
在流量激增时,系统可将部分 decode GPU 临时转用于 prefill,或快速扩容新资源;当负载下降时,又能自动缩容。这种弹性机制帮助企业在不超配硬件的前提下,稳定达成服务等级目标。
此外,Dynamo 包含一个 LLM 感知的路由器,可追踪整个 GPU 集群中键值(KV)缓存的位置。当新请求到达时,路由器会计算其与已有 KV 缓存块的重叠度,并将请求路由至能最大化缓存复用的 GPU,从而减少冗余计算——尤其在多个请求共享相同上下文时效果显著。
在内存管理方面,Dynamo 的 KV Block Manager 可将访问频率较低的缓存块卸载至 CPU RAM、SSD 甚至对象存储中。这种分层缓存机制支持将缓存容量扩展至 PB 级,同时保持高效复用。若不进行卸载,随着并发会话增加,GPU 内存易发生缓存驱逐,导致昂贵的重复计算;而通过卸载,系统可在维持低延迟的同时服务更多用户。
Dynamo 被视为NVIDIA Triton推理服务器的继任者,融合了早期推理框架的经验教训。项目采用 Rust 构建以确保高性能,同时通过 Python 接口提供可扩展性,目前已在GitHub上完全开源。
原文链接:




