
OpenAI大致介绍了他们如何扩展 PostgreSQL 以处理 ChatGPT 及其 API 平台(服务于全球数亿用户)上每秒数百万次的查询。这项工作突显了 PostgreSQL 单主实例(不引入额外的分布式解决方案)在面对写入密集型工作负载时所能达到的极限,同时也强调了构建全球可用的低延迟服务所需的设计权衡和运营保障措施。
在过去的一年中,PostgreSQL 的负载增长了十倍以上。为此,OpenAI 与 Azure 合作优化了其在Azure Database for PostgreSQL上的部署,在保持单一主实例不变的情况下,使系统能够为 8 亿 ChatGPT 用户提供服务,而且还留有足够的余量。优化工作涵盖了应用层和数据库层,包括扩展实例大小、优化查询模式和通过额外的只读副本进行扩展。应用层调优减少了冗余写入,并将新的写入密集型工作负载导向像Azure Cosmos DB这样的分片系统,而将 PostgreSQL 用于需要强一致性的关系型工作负载。
PostgreSQL 主实例由分布在不同地理位置的近 50 个 Azure Database for PostgreSQL 只读副本提供支持。读取操作分散在各个副本上,p99 延迟保持在低两位数毫秒级上,而写入操作则集中处理,并采取措施限制不必要的负载。延迟写入和应用层优化进一步减轻了主实例的压力,即使在全球流量激增的情况下也能保持一致的性能。
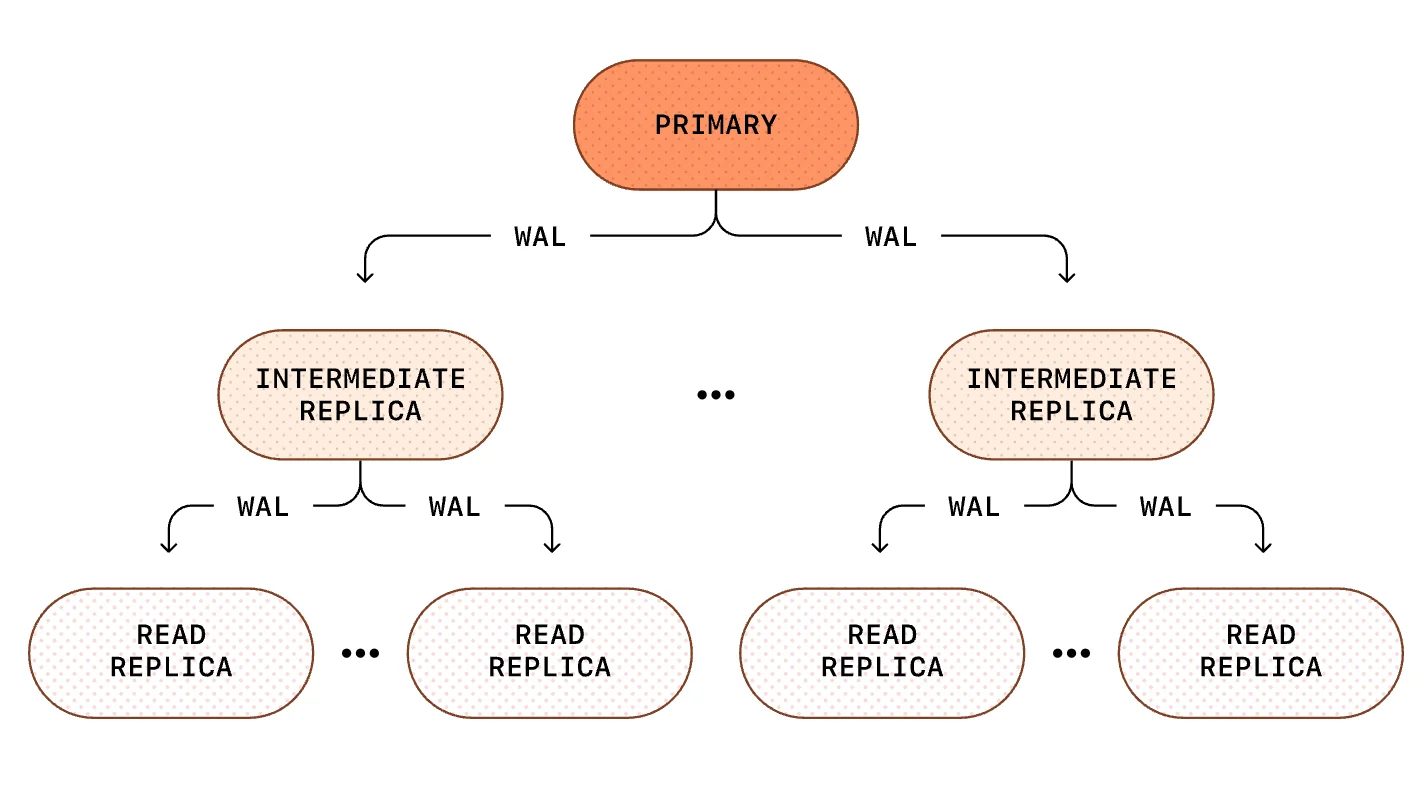
PostgreSQL 级联复制(图片来源:OpenAI博客文章)
随着流量的增长,运营挑战也随之出现。缓存未命中风暴、由ORM生成的多表连接模式以及服务范围的重试循环均被认定为常见的故障模式。为了解决这些问题,OpenAI 将部分计算移至应用层,对空闲和长时间运行的事务执行更严格的超时限制,并优化查询结构以减少对自动清理过程的干扰。
降低写入压力是一个关键策略。在高更新负载场景下,版本更迭和清理成本会导致 PostgreSQL MVCC模型的 CPU 和存储开销增加。为了缓解这种情况,OpenAI 将可分片的工作负载迁移到分布式系统上,限制回填和大批量更新的速度,并严格遵守运营策略以避免级联过载。
在LinkedIn上的一篇博文中,微软公司副总裁Shireesh Thota指出:
每个数据库都需要经过不同的优化和适当的微调才能适用于大规模工作负载。
连接池和工作负载隔离同样至关重要。PostgreSQL 的连接限制由 PgBouncer 以事务池的模式管理,这既可以降低连接建立延迟,又可以防止客户端连接激增。关键和非关键工作负载也做了隔离处理,从而在需求高峰期间避免了噪声邻居效应。
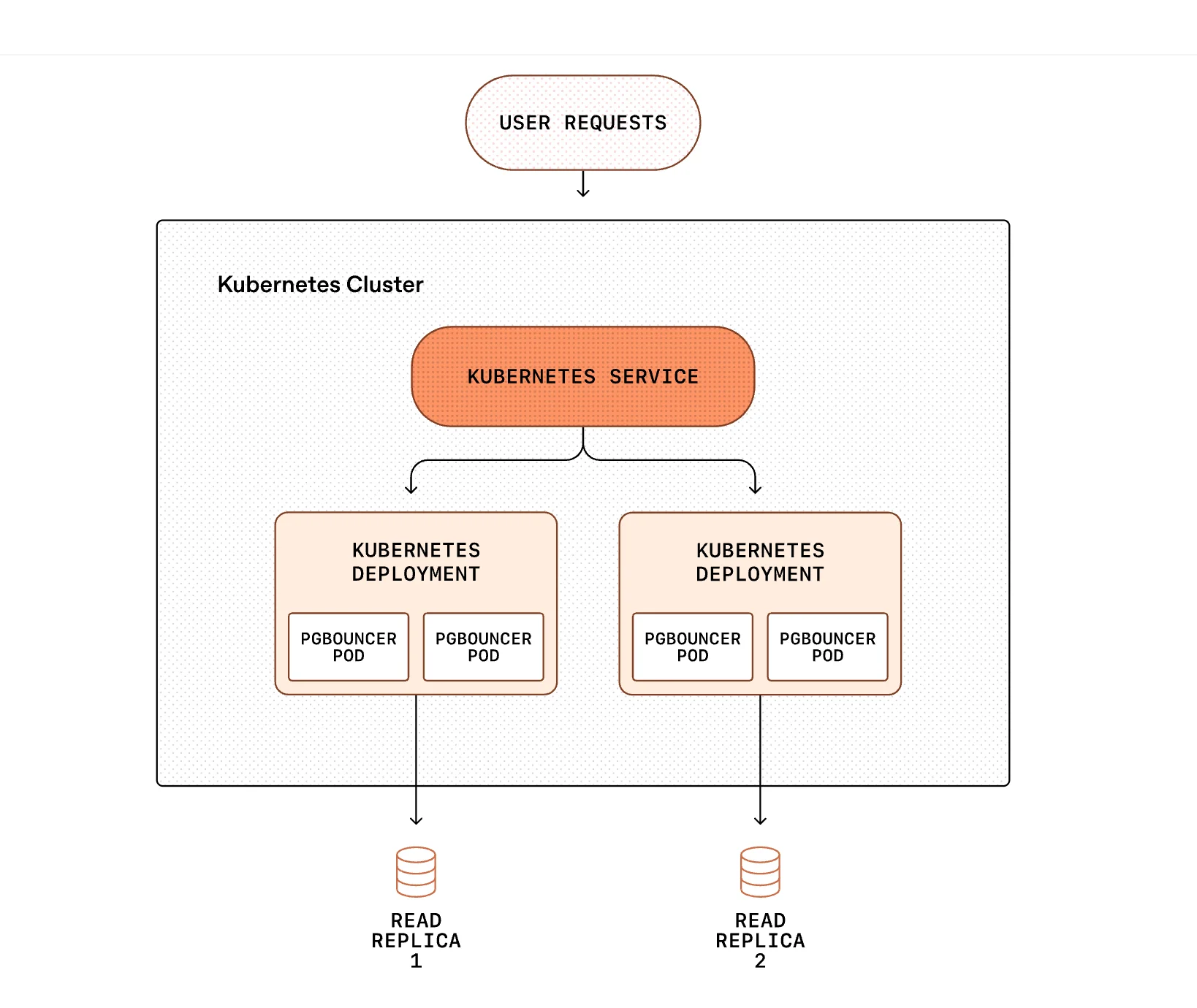
运行多个 PgBouncer pod 的 Kubernetes 部署(图片来源:OpenAI博客文章)
可扩展性限制也源于读取复制。随着副本数量的增加,主实例必须将WAL日志流式传输到每个副本,这会增加 CPU 和网络开销。OpenAI 正在尝试级联复制,由中间副本向下游转发 WAL 日志,这样既能减轻主实例的负载,又能支持未来的增长。这些策略使 PostgreSQL 能够跨地理位置不同的区域支撑极大规模的读密集型 AI 工作负载,同时通过分片系统处理写密集型操作以保持稳定性和性能。
OpenAI 表示,他们将继续评估提升 PostgreSQL 可扩展性的方法,包括分片 PostgreSQL 部署和其他可选的分布式系统,以平衡强一致性保证与日益增长的全球流量和随着平台增长而日益多样化的工作负载。
原文链接:
https://www.infoq.com/news/2026/02/openai-runs-chatgpt-postgres/




