
火山引擎 RTC 脱胎于字节跳动自研的 RTC 技术中台。目前,字节跳动旗下约 40+ 业务产品都由此技术中台提供底层 RTC 服务,其中不乏抖音这样亿级 DAU 的国民应用。
除了互娱场景之外,火山引擎 RTC 也在在线教育、游戏语音、企业通信等领域拓展服务场景。目前,火山引擎 RTC 的月用量已经达到了百亿分钟级别,并仍在快速增长。
本文将分享火山引擎 RTC 在互娱场景下的最佳实践,主要包括千人聊天、直播连麦和云渲染这三个具体场景。
千人聊天的技术挑战
千人聊天场景来源于 2021 年初非常火爆的语音沙龙场景。千人聊天场景下,一个频道需要支持多至上千个参与者,频道内所有有麦的用户(主播)都可以就频道话题进行发言。
从技术角度来讲,主播数量的每一点增大都会额外带来巨大的计算量。假设主播数量是 n,且每个主播都开麦,那么,每个主播都要订阅除自己以外所有主播的音频,也就是 (n-1) 路音频。此时,订阅的量级就是 n*(n-1)。当 n=1000 时,运算量就达到了 100 万。并且,频道内的每个用户还会进行各种高频动作,比如进出频道,或者主播上下麦。每个简单的操作,在频道内有极大的人数时,都会触发大量的运算,很容易造成 RTC 服务端的消息风暴。
频道内巨大的人数也会对应用客户端造成压力。应用客户端需要维护 n 份 ICE 连接,对下行带宽和处理内存有非常高的要求。
针对这个场景,我们看到市场上已有一些方案。这些方案通常会区分参与者的角色(主播/观众),限定只有主播才可以发言,并限定主播人数不能超过 50 人,而观众角色的参与者只能收听或收看。构建千人聊天场景的业务方很容易就发现这样的方案会对业务形态造成限制。同时,业务方在进行场景构建时,还需关注人数上限,添加兜底逻辑。
火山引擎 RTC 认为,这样的方案是不合理的。我们希望这个场景下人人都可以是主播,且人数的上限达到或超过 1000,甚至没有限制。这样才能帮助我们的业务方无拘无束的构建理想中的场景。
千人音频聊天解决方案
经过反复的思考和积极的尝试之后,我们认为能通过优化对音频订阅逻辑的处理,实现我们理想的方案。解决思路可以概括为服务端选流。思路如图:
混音和选流
在了解这个思路之前,需要先了解一下混音策略。客户端播放来自远端的音频信号之前,需要先把多路音频混成一路。混音会消耗算力,当进行混音的音频流数量(n) 特别多,比如达到上百的量级时,客户端的混音会需要很多时间。因此,大多数 RTC 方案中,在客户端混音时,添加选流策略,同一时刻只对于音量最大的 n 路音频流(n 通常为 3)进行混音,抛弃其他的音频流。
一个合理的怀疑是,选流策略会导致一些有用的音频流被抛弃。其实绝大部分场景下是不会的。因为现实中,多人同时说话时信息的传递准确率是很低的,如果一个频道里有大于两个人同时在说话,其他人就基本听不清说话内容了。对于抢答、齐读等特殊场景,也只要把 n 调整为 10,就基本可以解决问题了。
选流策略是多人音频场景下一个普遍的策略。但仔细思考就会发现,如果这个策略在应用客户端实现,就意味着如果频道内有 n 路音频,客户端仍然需要订阅 n-1 路音频流,再进行选流和混音。当 n 特别大时,下行带宽和计算资源的浪费就很明显。
服务端选流
发现以上的弊端后,我们就考虑是不是把选流策略放在服务端进行;完成选流后,只向客户端发送有效的音频流就好了?
假设,最终我们从 n 路音频流中选取 m 路音频流(3≤m≤10)。那么选取完成后,服务端只需要向单个客户端建立 m 个通道,进行音频流的传输。这样一来,服务端实际处理的消息数量就变成了 mn(而非 nn),计算复杂度就从 O(n^2) 降到了 O(n)。无论是服务端的消息压力,还是客户端的内存和带宽压力,都能够大大减小。
实际上,我们也正是这样去做的,这一方案在千人场景测试中表现非常好。
千人视频聊天解决方案
千人场景下的音频我们解决了,如果还要加上视频,该怎么处理?
和一般人想的不同,视频的处理其实比音频的处理要简单得多。业务方对需要订阅哪几路视频流有很明确的想法。作为 RTC 技术提供方,我们只需要将音频和视频订阅逻辑分离,帮助业务方根据自己的想法添加视频订阅逻辑,由我们来帮助管理音频订阅逻辑。
当然,我们也可以支持根据音频选流的思路进行视频选流:显示频道内说话声音最大的用户的视频。如果有多路视频,则按照音量降序,显示多路视频。这个思路在很多视频会议应用中经常使用。
直播连麦的极致体验
直播连麦是指主播之间或主播和观众之间,通过实时音视频进行互动,并把互动的音视频合成一路进行直播的场景。常见的直播连麦细分场景包括主播 PK 、主播和主播连麦以及主播和观众连麦等。各种玩法非常丰富,这里就不一一赘述了。
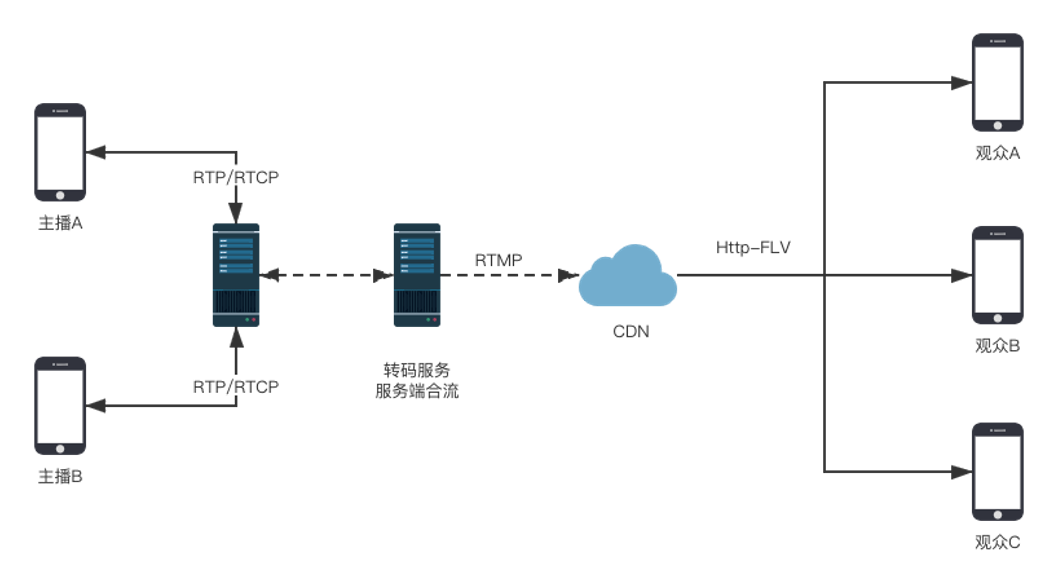
这一场景下,使用 RTC 产品传输的音视频流,都需要合流,转码成 RTMP 流并推送到 CDN 处。业内主流方案在实现这一逻辑时,这些合流转码推送的步骤都是在服务端实现的,也就是大家熟悉的旁路转推的方案。如下:
在字节跳动内部测试中,我们发现这个方案会带来不可避免的体验瑕疵:
黑屏和卡顿:主播的上下麦时,需要从直播流转成 RTC 流,或从 RTC 流转成直播流。线路的切换经常会造成黑屏和卡顿。在弱网情况下,这一现象尤其明显。
清晰度下降:主播采集的视频经过一次编码推到 RTC 服务端;RTC 服务端收到后,对这一视频流进行解码,和其他视频流合码,进行第二次编码再推送到 CDN 处。其中的多次编码解码会造成明显的清晰度下降。
智能合流
经过仔细的思考后,我们觉得把合流、转码推流这一系列过程放到主播的客户端,似乎有助于解决上面的问题。
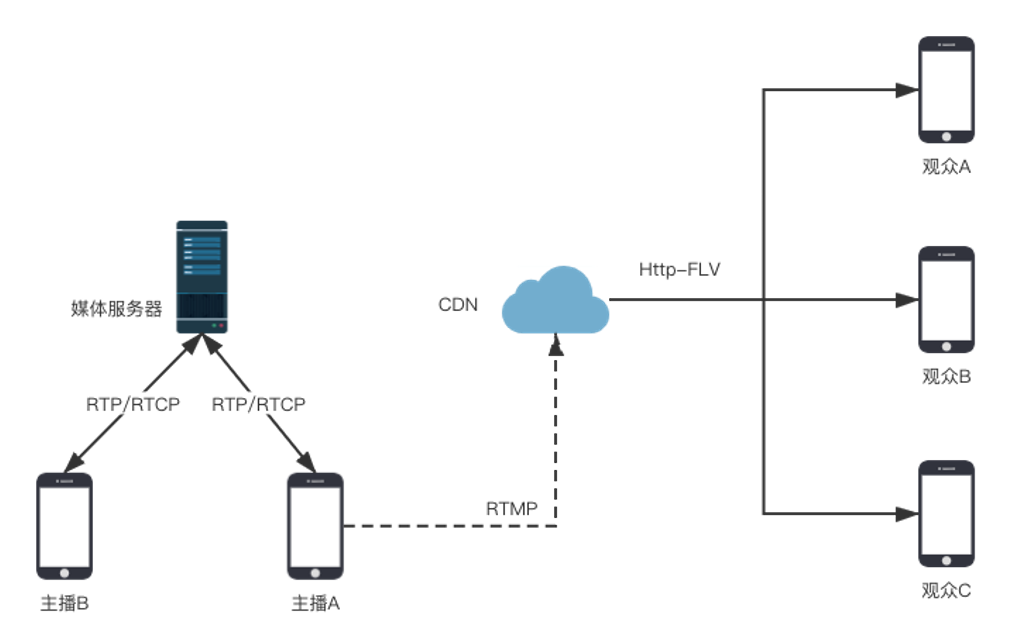
在客户端合流转码时,可以减少一次编解码,减小清晰度的损失;其次不管是主播的单路 RTMP 流还是合流后 RTC 流转成的 RTMP 流,都是在主播的客户端实现推流的,两者切换过程中,就可以做到没有黑帧。以下是示意图,和服务端合流转推相比,少了转码服务器的参与:
我们当然也意识到了这个方案的局限,那就是对主播的设备的性能和网络带宽要求非常高。把合流、转码、推流这些步骤从服务端上转移到客户端上,会对客户端造成非常大的压力。
最终,我们决定将客户端合流和服务端合流融为一体,并根据主播的设备和网络质量情况,判断适用的方案。这一判断逻辑是比较复杂的,我们将真实场景下测试得到的最佳实践封装在产品中,供业务方直接使用。
最后的数据结果表明:在客户端上进行转码推流,清晰度提升的收益大概在 20%-40%。
解锁更多玩法
在客户端上进行合流、转码还可以解锁更多玩法。
比如,有些场景需要在连麦直播过程中加上 CV 等效果,并希望渲染出来的画面能够和 RTC 连麦的画面高度一致。这时候采用服务端合流的方案造成的延时将远高于客户端合流的方案。如果业务方对实时性有要求,就只能使用客户端合流了。
云渲染方案
一些复杂的渲染计算,比如高画质的游戏或者精美的 3D 模型,会消耗非常多的计算资源。要达到最佳的显示效果,对终端的图形计算性能就有很高的要求。随着 RTC 技术的不断发展,我们可以在云端进行渲染,把渲染得到的音视频画面,用 RTC 传输到本机。终端用户只需要满足网络开销和播放音视频的性能开销,就能获得极致的视听体验。
常见的云渲染应用场景包括:云游戏,云手机、云电脑等。我们和火山引擎的多媒体中台、AI 中台一起共建的云特效方案亦属此列。云特效能够把主播拍摄的画面先通过上传到云端进行特效渲染,然后再把渲染后的视频推回到主播的客户端。主播在客户端上看到的加了特效的视频,在非常短的时间内其实经过了上传、特效渲染和下载的过程。
云渲染面临的挑战
当然云渲染的场景也面临一些挑战:
超大的计算:云渲染会消耗大量的 GPU 计算资源。
超大码率:要有更精美的画质,移动端一般要求 720P 30 帧;PC 端则是 1080P 60 帧。
超低延时:云渲染对响应延时的要求一般在 100 毫秒以内,远低于传统 RTC 应用的延时要求( 400 毫秒以内)。
超高可靠:应用在云游戏场景中时,会有超高的可靠性要求。
总结成一句话,就是既要更大的码率,又要更低的延时,还要更高的可靠性。
传统云渲染的传输方案
渲染质量等挑战不是本文关注的内容。以下我们讨论如何应对云渲染场景对低传输时延的要求。
传统的云渲染有两种传输方案:
云渲染的主机和终端采用 P2P 方案进行传输。这一方案时延较低,但可靠性较难保障。
云渲染的主机和终端采用 RTC 方案进行传输。这一方案可靠性较高,但时延一般高于 P2P。
改进的传输方案
我们认为 RTC 方案能够比 P2P 方案实现更高的可靠性,我们只需降低 RTC 方案的延迟即可。
我们发现,RTC 传输的时延很大一部分是由于 RTC 和云渲染服务器之间的传输延时造成的。于是我们和火山引擎云渲染团队一起对传输网络进行了改造升级:将 RTC 的边缘节点和云渲染服务端进行一体化的部署,消除了从 RTC 服务端到云渲染服务端之间的传输延时。
当然,对于火山引擎以外的云渲染服务商,RTC 的边缘节点架构也支持同样的合作优化。根据需要,我们可以提供两种优化方式:
把火山引擎 RTC 的边缘节点部署到云渲染服务方的机房里。
把云渲染服务方的实例部署到火山引擎 RTC 的边缘节点里。
优化结果
改造后的相应延时数据如下:
云游戏和云手机的响应延时在 80 毫秒左右;
云特效的响应延时在 135 毫秒左右。
这里响应延时的定义是:
对于云游戏和云手机,从用户的终端触控开始,到用户最终看到画面的时间。
对于云特效,从用户拍摄自己的画面开始,到在终端上看到这个画面的时间。
总结
本文主要介绍了火山引擎 RTC 在千人聊天、直播连麦、云渲染三个场景下的最佳实践。
在千人聊天场景下,音频订阅采用了服务端选流的策略,视频订阅则采用音视频订阅分离以及按音量显示视频的策略,保证视听效果的前提下,大大降低了客户端性能开销。
在直播连麦场景下,采用智能合流的方式,根据具体情况应用客户端和服务端合流转推,减少了黑屏卡顿,并提升了清晰度。
在云渲染场景下,将 RTC 边缘节点和云渲染主机进行一体化部署,并自研了云渲染主机实例底层架构,降低了云渲染场景下的响应延时。同时,这一架构还支持第三方云渲染主机接入。
Q&A
Q:千人聊天这个方案可以用于视频会议场景吗?
A:可以。事实上很多 RTC 场景就是从视频会议场景演化而来的,千人聊天甚至万人聊天的场景就是其中之一。但是有别于传统视频会议的 MCU 架构,我们这个架构还是基于 SFU 的,它只是在服务端做选流,并不做合流(MCU 的方案)。因为合流会造成一定的成本消耗和延时增加,并且多方音频的合流方案并不经济,因为不能把每个人自己的声音合进去。不过我们也有 MCU 的融合方案,可以融合到现有方案中,针对部分低端设备提供合成后的音视频流,这就是另一个话题了。
Q:直播连麦时,合流特效是直接在主播端合成到了 RTMP 流里面吗?
A:一些美颜特效在编码传输前添加,方便主播在本地预览;单人直播时,会合到 RTMP 流里面;连麦直播时,就合到 RTC 流里面。对于一些需要后期叠加的渲染,比如小游戏的场景,就不会合成到视频流里面,而是在接收端渲染。渲染时,可以利用 SEI 来控制同步。
Q:云渲染的延时还可以怎么控制?
A:除了文中提到的,把 RTC 的服务器和云渲染服务器一体化部署,减少传输延时的方案以外,我们还有很多其他策略:比如使用感兴趣区域编码策略(ROI),对感兴趣的区域应用较高的编码质量,不感兴趣的区域应用较低的编码质量。用这样的方法可以降低整体码率和编码时间。另外,对于有很多静止画面的情况,提高编码压缩率。
本文转载自:字节跳动技术团队(ID:toutiaotechblog)
原文链接:火山引擎 RTC 在互娱场景下的最佳实践




