
DoorDash 推出了一个多模态机器学习系统 DashCLIP,通过在共享表征空间中对齐产品图像、文本描述和用户查询来生成语义嵌入。该架构旨在改善公司消费品(CPG)市场中产品的发现、排名及广告相关性。为了训练该系统,DoorDash 使用了约 3200 万组标注过的查询-产品数据对,将搜索查询与相关的商品目录项进行匹配。
DoorDash 的消费品市场涵盖了多种品类,包括生鲜食品、零售商品、电子产品和药品。对于依赖结构化元数据和历史互动信号的传统搜索与推荐系统,这种多样性是个很大的挑战。这些方法往往无法获取产品图片、描述与用户意图之间的语义关联。DashCLIP 通过学习多模态表示解决了这一问题,这种表示方法能够将产品视觉信息和文本信息与查询上下文相结合。
DashCLIP 基于像 CLIP(对比式语言-图像预训练)这样的对比学习方法构建。对于产品图像、文本描述和用户查询,它都使用了独立的编码器,每个编码器都会生成向量嵌入。在训练过程中,语义相关的项在嵌入空间中距离会比较近,而无关的项则距离比较远。该架构结合了用于图像和文本的单模编码器、整合两种信号的多模编码器,以及将搜索查询映射到同一空间的查询编码器。即使在文本描述不完整或视觉属性至关重要的情况下,该系统也能将查询与商品进行匹配。
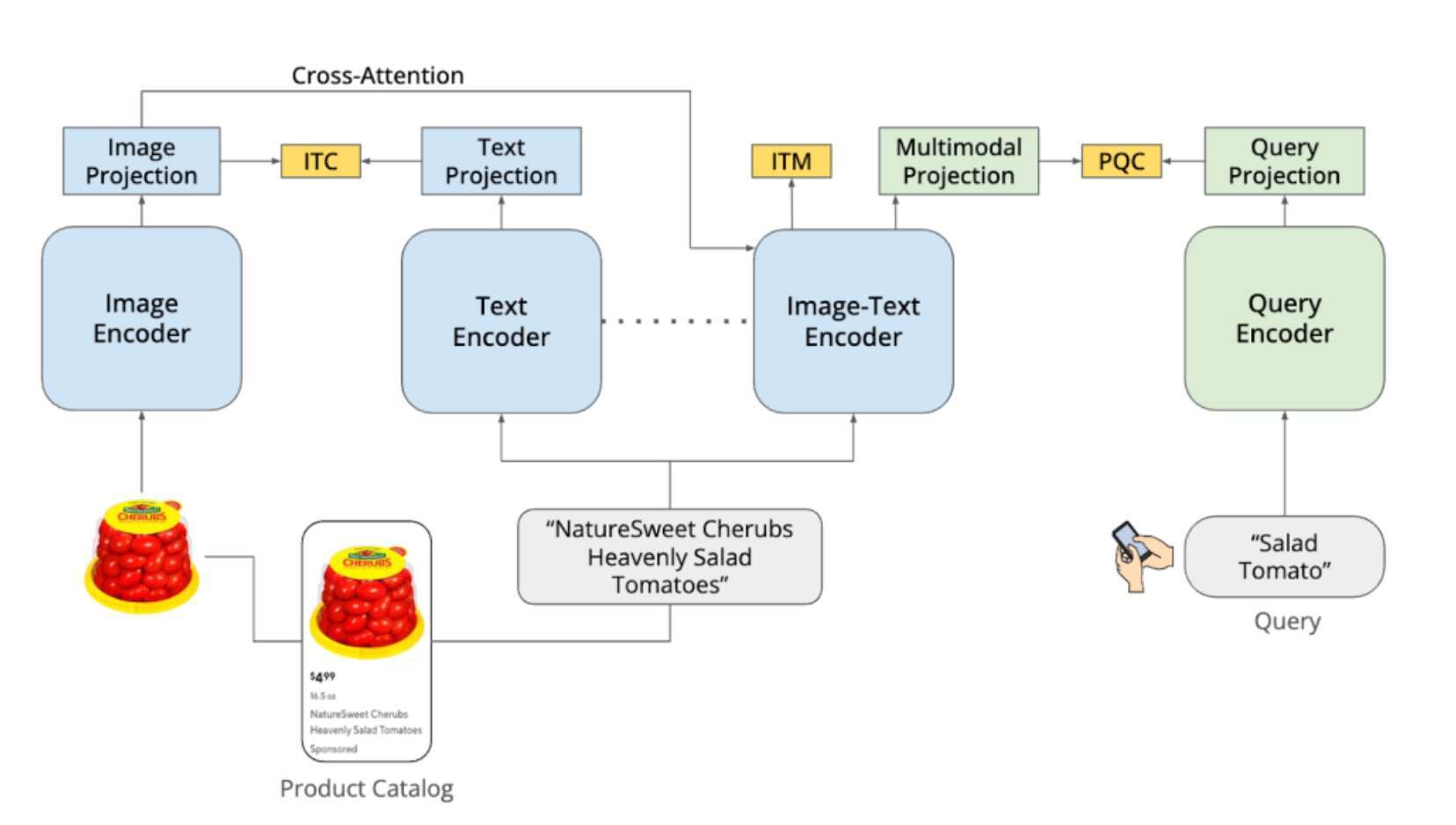
DashCLIP 架构概览,展示了编码器和嵌入对齐管道(图片来源:DoorDash博文)
DoorDash 采用一个两段管道对 DashCLIP 进行了训练。第一段对产品目录中的约 40 万个产品图片-标题对持续进行预训练,将预训练的视觉语言模型适配到电子商务领域,并学习多模态产品表征。第二段利用名为“查询目录对比(QCC)”损失的对比目标,将用户查询与产品嵌入向量进行对齐,使相关的查询-产品对更接近,同时使无关的对分离。为此,团队收集了 70 万组人工标注的查询-产品对,并利用基于 GPT 的标注系统将数据集扩展至约 3200 万个样本。这种混合方法减少了过度依赖历史互动数据所产生的偏差。
训练完成后,嵌入向量会被整合到 DoorDash 的排序系统中。查询嵌入向量通过 K 最近邻搜索检索候选商品,随后由下游排序模型根据用户行为、上下文信号和商品人气对这些商品进行评分,从而实现语义相关的检索和排序。
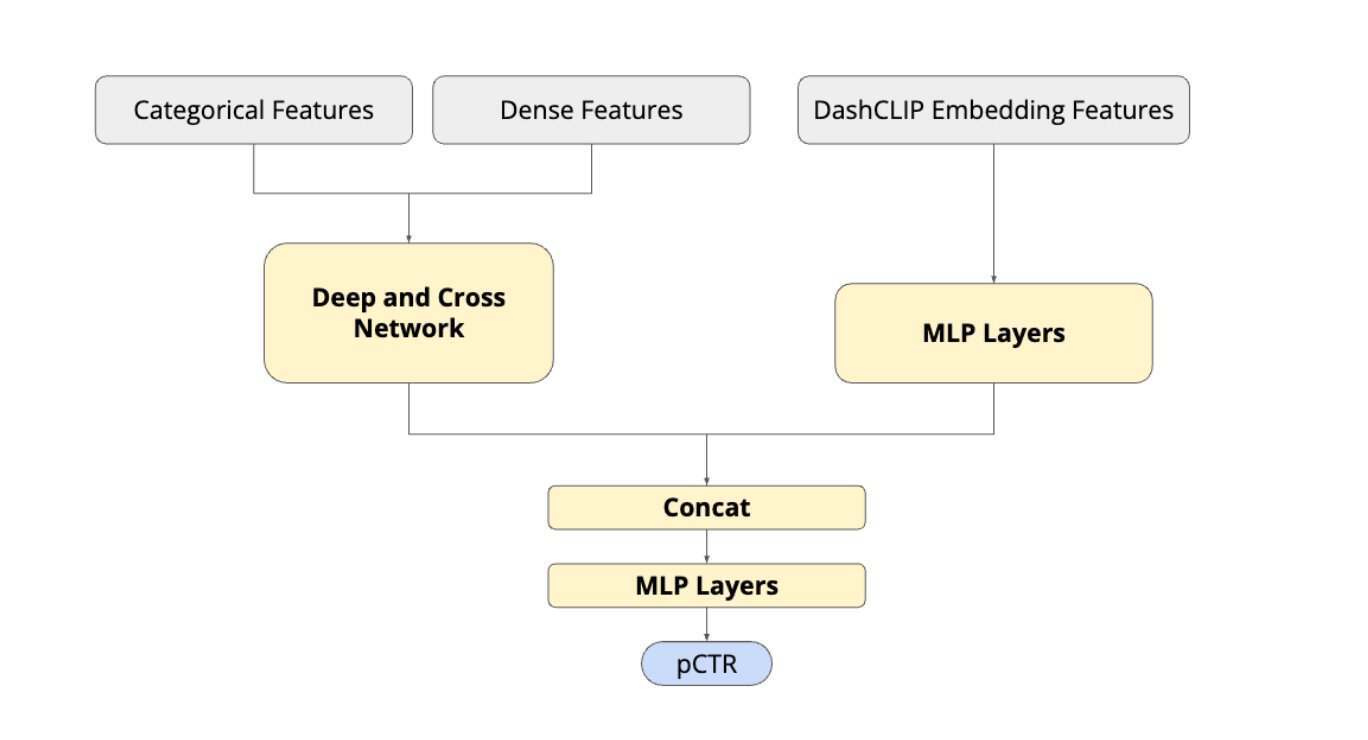
排序管道(图片来源:DoorDash博文)
离线实验表明,DashCLIP 嵌入在排序和检索任务中的表现均优于 CLIP、BLIP 和 FLAVA 等基线视觉语言模型。在在线 A/B 测试中,该系统提升了用户参与度指标,随后便被部署用于处理推广商品推荐的生产流量。
除了广告和排名之外,DoorDash 报告称,这些嵌入模型还能推广到其他任务,包括货架类别预测和商品查询相关性分类,并指出,可以用一个共享的多模态嵌入层作为市场平台内多个机器学习系统的基础表示。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2026/03/doordash-semantic-search/




