
MongoDB 近日宣布,在 MongoDB Atlas 上正式推出 Embedding 与 Reranking API 的公开预览版本。通过这一新 API,开发者可以在托管云数据库中直接调用 Voyage AI 的搜索模型,在一个统一的集成环境中构建语义搜索、AI 助手等功能,同时实现监控与计费的统一管理。
这一方案将构建 AI 检索系统所需的关键组件整合在同一平台上。MongoDB 表示,该 API 具备数据库无关性,可集成到任何技术栈或数据库中,面向正在构建检索驱动型 AI 系统的团队,覆盖从语义搜索、RAG(检索增强生成)到 AI Agent 等多种场景。MongoDB 高级技术产品营销经理 Thibaut Gourdel 与 MongoDB 资深产品经理 Wen Phan 在文中写道:
目前构建 AI 检索系统,往往需要把数据库、向量搜索和检索模型服务商“拼接”在一起,每一个环节都会引入额外的运维复杂度。为了解决这一问题,我们在 MongoDB Atlas 上推出了 Embedding 与 Reranking API。
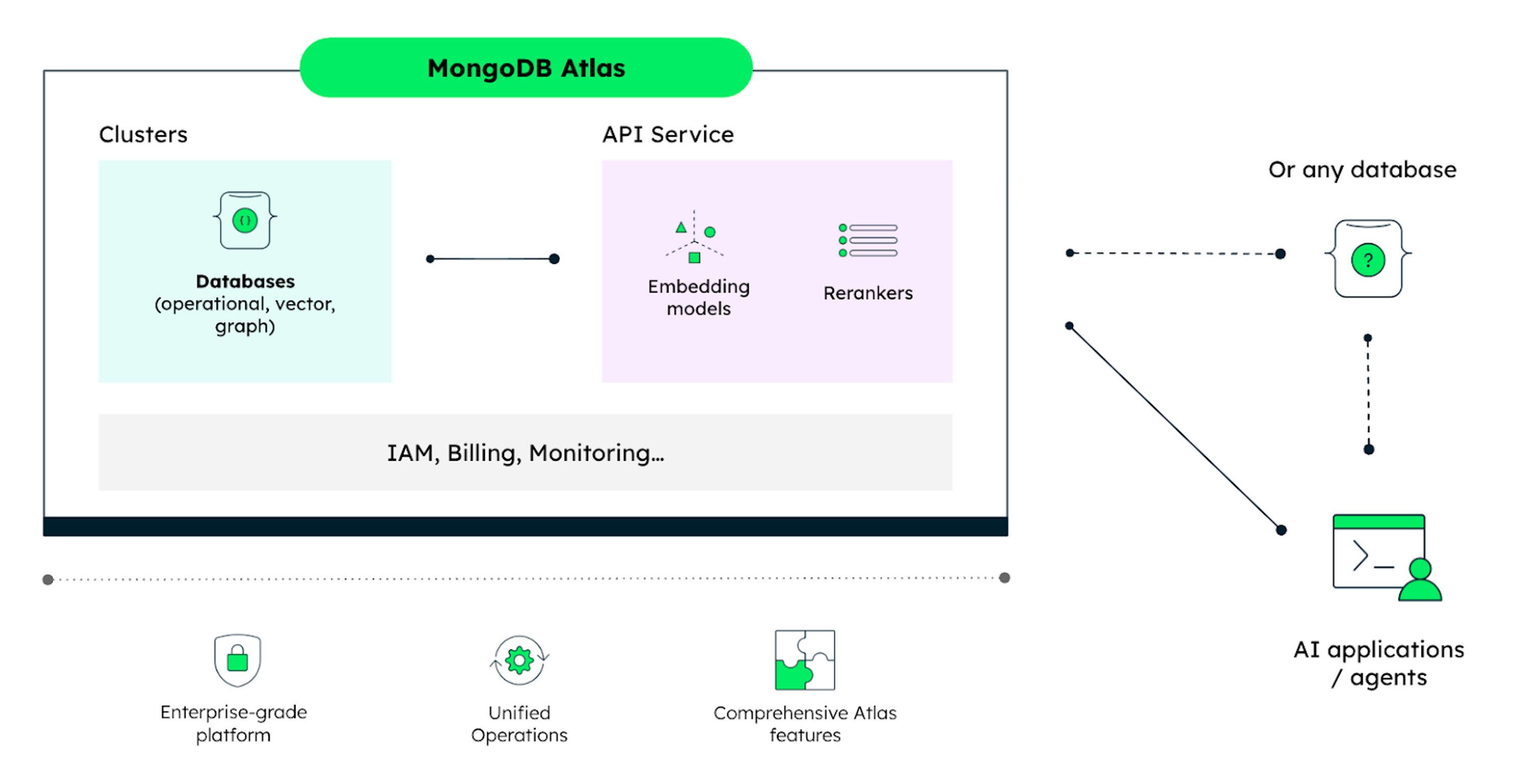
MongoDB Atlas 上的 Embedding 与 Reranking API
在 .local San Francisco 活动上发布的另一项重要内容是 Voyage 4 系列模型的上线。该系列目前包含四种不同模型:voyage-4-large、voyage-4、voyage-4-lite,以及开源权重的 voyage-4-nano。与以往嵌入模型需要对查询和文档使用同一模型不同,Voyage 4 提供的文本嵌入模型运行在统一的向量空间中。这意味着,团队可以使用 voyage-4-large 存储数据,同时在查询阶段灵活使用任意 Voyage 4 模型。
此外,向量搜索的自动化嵌入功能已在社区版中开启预览,MongoDB Vector Search 的 Lexical Prefilters(词法预过滤)也已进入公开预览阶段,为开发者在向量搜索之外提供文本与地理分析过滤能力。对此,Deepak Goyal 在 LinkedIn 上评论道:
我昨天花了 3 个小时排查我们向量存储中一个长达 12 小时的同步延迟问题。这几乎是每个 AI 团队现在都在缴纳的“同步税”。如果你的数据已经滞后 24 小时,那你的 RAG 就谈不上“智能”,它只是一个索引做得不错的档案库。统一数据流之后,趋势已经很清晰:专用向量数据库的角色,正越来越接近 AI 世界里的“外置 GPU”。性能固然出色,但在多数生产环境下,集成式方案在速度和复杂度控制上更占优势。
在模型能力方面,这些嵌入模型支持 256 到 2048 维度,并支持量化处理,使开发者能够在准确率、成本与性能之间进行权衡。除了通用模型外,Voyage 还提供面向特定领域、整文档分析、多模态数据,以及多阶段搜索系统中重排序(reranking)的专用模型选项。
Gourdel 与 Phan 强调,尽管 MongoDB Atlas 已经内置了向量搜索能力,但新 API 的核心价值在于进一步降低复杂度:
这对于构建生产级 AI 系统至关重要。扩展 LLM 应用的关键,在于在恰当的时间提供正确的上下文,而这意味着必须将业务数据与高性能搜索进行紧密集成。
自 MongoDB 在近一年前宣布收购 Voyage AI 以来,社区便一直在期待并讨论 Voyage AI 能力与 MongoDB Atlas 的深度整合。此次 Embedding 与 Reranking API 的推出,也被视为这一整合方向的正式落地。
目前,Embedding 与 Reranking API 仍处于预览阶段。MongoDB 同时提供了 “Voyage AI Quick Start” 教程,形式为 GitHub 上的 Python Notebook,供开发者快速上手体验。
原文链接:
https://www.infoq.com/news/2026/02/mongodb-embedding-reranking-api/




