
新加坡的会场里,全球人工智能顶会 AAAI,正式揭晓年度奖项,也迎来了它的第 40 个年头。
今年共颁发了 5 个杰出论文奖,以及 2 个经典论文奖。在获奖名单中,竟然还有“机器学习三巨头”之一的 Yoshua Bengio。
不过这一次,他并不是因为最新成果获奖,而是凭借在 2011 年写的一篇论文获得了经典论文奖。而且不久前,他刚达成 AI 领域首个“百万被引作者”的成就。
为什么 10 多年前的这篇论文,会在今年被重新拉出来,还获得了经典论文奖?
不妨来看看它讲了些什么。
论文名为 Learning Structured Embeddings of Knowledge Bases(《面向知识库的结构化表示学习》)。提出了一种方法,把知识库的结构化数据嵌入到连续空间中,从而让结构化知识更容易用于机器学习任务。
换句话说,这篇文章解决的是如何把离散世界(知识、事实、关系)嵌入到连续空间;以及如何让神经网络不靠纯统计,而是“接住现实结构”。而今天热门的世界模型、RAG、Agent 的外部记忆等等这些东西,从本质上讲,全都在复用这条路线。
再说回今年获奖的 5 篇杰出论文,这些论文有讲机器人和 VLA 的,有在讲如何在连续时间系统中让 AI 模型“白盒化”的,还有讲 LLM 和 CLIP、讲高频信号和局部判别结构的。

串起来看,这些论文的研究方向,其实可以概括出一个共同指向:AI 的竞争,已从拼实验环境的中的炫酷 Demo,转向真正的应用层。Scaling Law 那套虽然不完全失效,但多少有点过时了,谁能在真实世界中被理解、被修订、被信任越来越关键。
AAAI 2026: AI 走向现实,评奖标准重塑
下面来看看这几篇杰出论文,都有哪些有意思的信息。
具身智能领域:
论文名:ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver(ReconVLA:作为高效机器人感知器的重建式视觉-语言-动作模型)

要说清本文的创新点,需要再这里先简单回顾一下什么是 VLA——VLA(Vision-Language-Action)具身智能领域的一个关键模型,可以把视觉感知、语言理解和动作生成统一到同一个模型中,直接根据“看到什么 + 听到什么”,来输出可执行机器人动作。
不过当前 VLA 的缺陷也是很明显的:比如模型在执行动作时,视觉注意力高度分散;即便模型能“理解指令”,但在复杂场景、多干扰物、长任务中,往往看不准真正要操作的物体。
结果就是:抓错对象、操作不精确(现实世界对精确度要求很高)、长链任务中途失败等等。
总之,以往 VLA 只监督“动作输出”,几乎不约束“视觉感知过程本身”。
而 ReconVLA 的关键思想是:不“告诉模型看哪里”,而是“逼模型把关键区域重建出来”。
其核心机制,简单来说,就是模拟人类视觉的“凝视(gaze)”机制,不要求模型输出框,也不输入裁剪图,而是让模型在内部生成一种“重建信号”,去还原“当前要操作的局部区域”。
论文还系统性地对比了三类视觉定位(grounding)范式:
一类是以外部检测器和裁剪图像为代表的 Explicit Grounding,
一类是先输出目标框、再生成动作的 CoT Grounding,
以及作者提出的 Implicit Grounding(隐式 Grounding),也就是 ReconVLA 的方式。
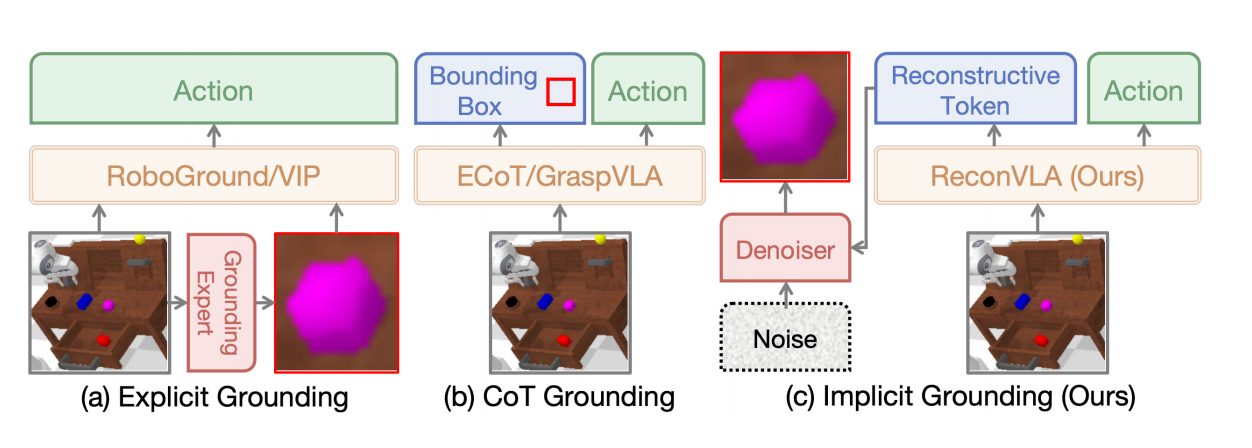
图注:不同范式 Grounding 之间的概念性对比。
前两类方法本质上都是在显式告诉模型“答案在哪里”,并未真正改变 VLA 内部的视觉表示和注意力机制。
而 ReconVLA 通过重建过程,将关键区域作为一种隐式的视觉监督信号,引导模型生成所谓的“重建 token(reconstructive tokens)”,从而在不引入额外输入或输出的前提下,重塑视觉感知能力。
换句话说,它不再让模型“蒙着眼睛试动作”,而是强制模型在每一步决策前,先把目标对象看准,再去动手。
关于从“结果可解释”,走向“结构可操作”:
论文名:Causal Structure Learning for Dynamical Systems with Theoretical Score Analysis
(基于理论评分分析的动态系统因果结构学习方法)

这篇论文提出了一种方法:CADYT。能够在连续时间、甚至不规则采样的数据中,同时刻画系统的动力学演化,并恢复其中的因果结构。
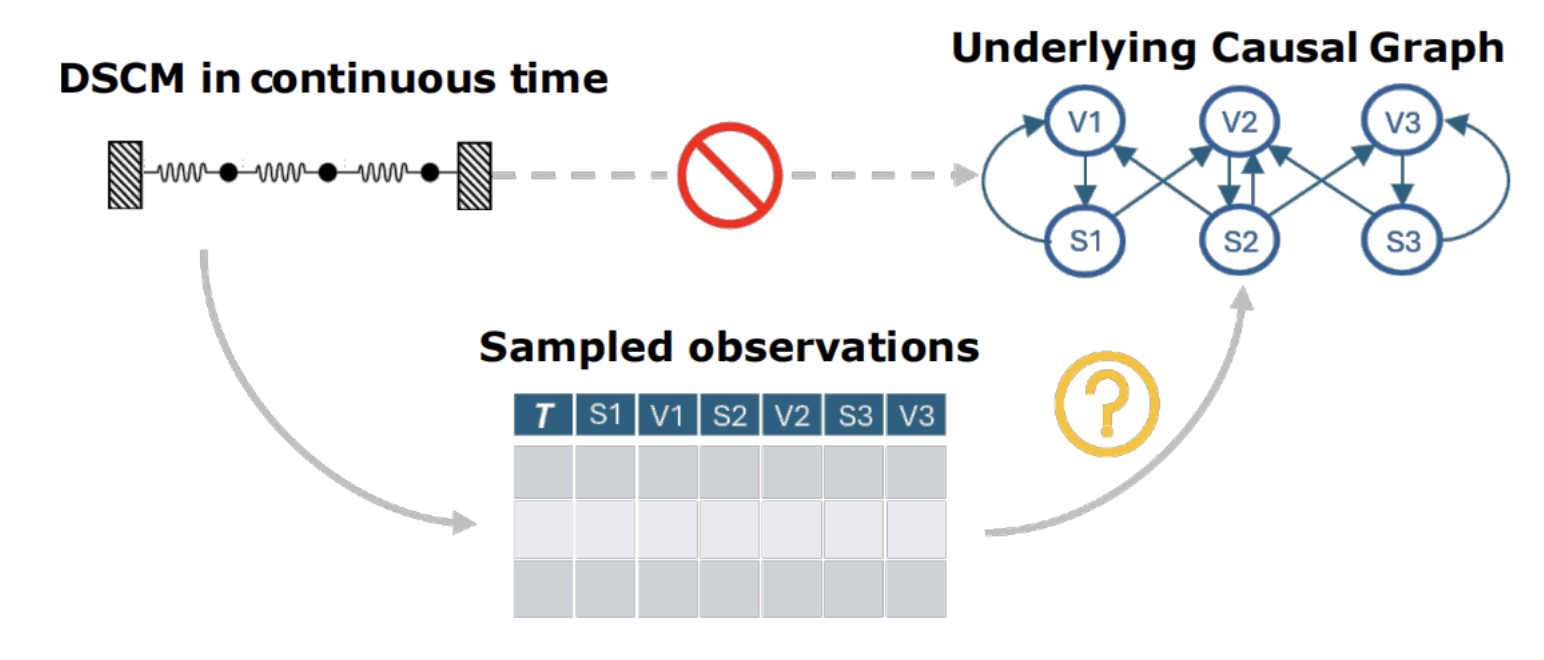
更重要的是,作者证明了用于判断因果关系的评分函数,在理论上等价于一种合理的模型选择准则,而不是经验性的启发式指标。换句话说,就是这个评分不是凭经验设计的,而是从理论上保证:它会偏向那些“解释得刚刚好、不多也不少”的因果结构。
在现实世界的系统中,无论是工业控制、物理系统,还是医疗过程,系统本质上都是连续时间演化的,而且由稳定的因果机制驱动。但以往的方法往往只能解决其中一半问题。
一类是时间序列因果发现方法,它们通常基于离散时间建模(如 DBN、Granger),并假设规则采样,因此在面对真实的连续动力学和不规则采样时,难以准确刻画系统本身的演化机制。
另一类是连续时间动力学建模方法(如 Neural ODE、GP-ODE),虽然能自然处理不规则采样,却主要关注预测精度,本质上并不区分因果依赖与偶然相关。
这就留下了一个长期存在的空白:几乎没有方法,既工作在连续时间框架下,又能够同时恢复系统的动力学机制和因果结构。
而 CADYT 正是针对这一空白提出的。它将连续时间的高斯过程动力学建模,与基于最小描述长度(MDL)和算法马尔可夫条件(AMC)的因果评分结合起来,在不规则采样条件下,通过比较不同因果结构对数据的“压缩能力”,来识别真正的因果关系,并给出了明确的理论保证。
说得更直白一点,这项工作把连续时间动力学建模,从“拟合得像不像真实轨迹”,推进到了“学到的机制在因果上是不是对的”。
论文名:Model Change for Description Logic Concepts
(描述逻辑概念的模型变更)

此论文还未公开上传,暂无链接。
关于表示学习,重新审视结构本身
论文名:LLM2CLIP: Powerful Language Model Unlocks Richer Cross-Modality Representation
(LLM2CLIP:强大语言模型解锁更丰富跨模态表征)

CLIP(Contrastive Language–Image Pre-training)是一个经典的多模态模型,通过对比学习,将图像和文本映射到同一语义空间,从而实现“以文找图、以图找文”等跨模态理解能力。
CLIP 在跨模态检索和基础语义对齐上表现出色,但它也有一个公认的短板:文本编码器容量较小、上下文长度有限,对长、复杂、信息密集的文本理解能力不足。这在长文本检索、多语言理解等场景中尤为明显。
LLM 在语言理解、上下文建模和世界知识方面,倒是明显更强。但问题在于,LLM 不能直接接入 CLIP。
——一方面,原生 LLM 的句向量并不具备对比学习所需的“高区分度”,很难有效拉开不同 caption 之间的距离;另一方面,如果端到端联合训练 LLM 和 CLIP,计算成本也高得不可接受。
这篇论文提出了一种系统化的新方法,名曰:LLM2CLIP,顾名思义,把 LLM“接入”或“输送”到 CLIP 里,用 LLM 来替代或者增强 CLIP 的文本能力。
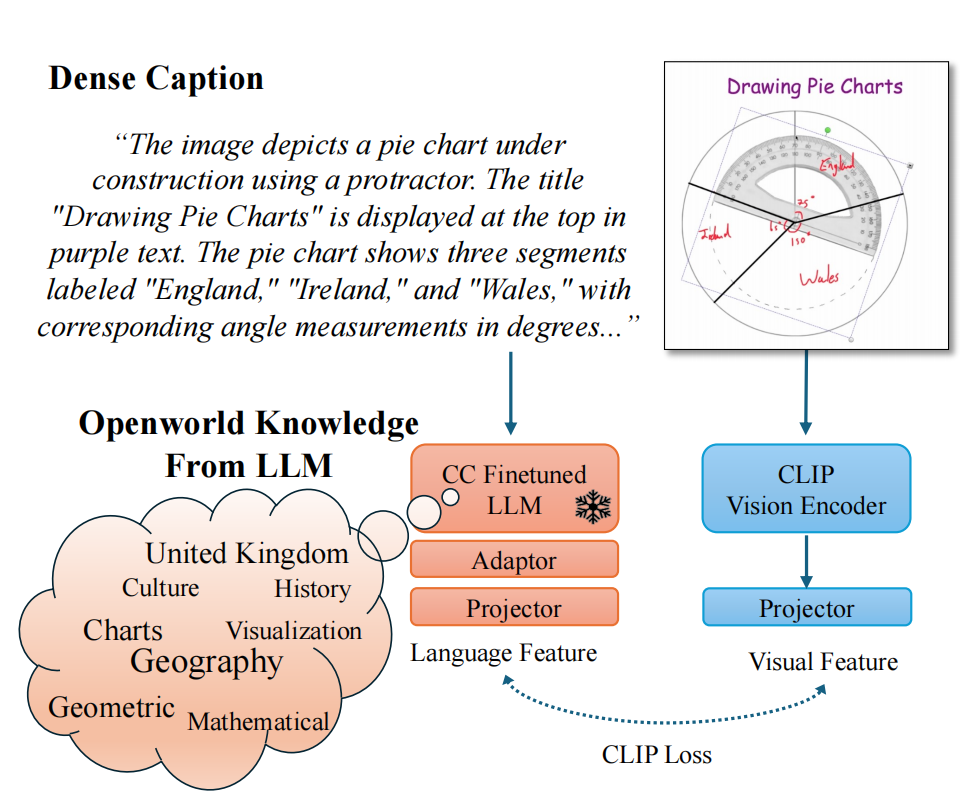
但这并不是简单地把 LLM 直接接进去。作者给出的解决路径,是分两步走,各解决一个关键障碍。
第一步,是先让 LLM 成为一个“合格的文本 embedding 模型”。为此,论文提出了 Caption-Contrastive Fine-tuning:
使用同一张图像对应的不同 caption 作为正样本,通过对比学习,让语义相近的描述在向量空间中更接近、不相关的描述更远;同时配合平均池化、双向注意力和 LoRA 等结构调整,提升句向量的稳定性和可区分性。
这一步的目标并不是做多模态,而是把 LLM 训练成一个真正“好用”的文本表示器。
第二步,则是直接用经过处理的 LLM,替换掉 CLIP 原有的文本编码器。在这一阶段,LLM 参数被冻结,仅训练一个非常轻量的 adaptor 来对齐视觉特征,使整体训练流程几乎等同于普通的 CLIP 微调,算力成本基本不变。
大量消融实验表明:同时保留两个文本编码器、或试图在两者之间做复杂对齐,效果反而更差;“直接替换”是最简单、也是最有效的方案。
实验结果显示,LLM2CLIP 在长文本检索任务上提升最为显著,短文本检索也有稳定增益,同时多语言检索能力明显增强。更重要的是,这些提升是在仅使用百万级数据、几乎不增加训练成本的前提下实现的。
总体来看,LLM2CLIP 的价值在于,它没有重造一个更大的多模态模型,而是用一种低成本、可复用的方式,把“语言理解”这块短板,直接补进了 CLIP 的核心结构里。
论文名:
High-Pass Matters: Theoretical Insights and Sheaflet-Based Design for Hypergraph Neural Networks
(高频信息的重要性:面向超图神经网络的理论分析与 Sheaflet 方法设计)

此论文还未公开上传,暂无链接。
总而言之,这些研究都在把关注点从结果层面的性能,推向模型内部的感知、结构和机制本身。
论文地址:
https://arxiv.org/abs/2508.10333
https://arxiv.org/abs/2411.04997
https://arxiv.org/abs/2512.14361
参考链接:
https://aaai.org/about-aaai/aaai-awards/aaai-conference-paper-awards-and-recognition/
https://aaai.org/about-aaai/aaai-awards/aaai-classic-paper-award/?utm_source




