
亚马逊云科技近期推出了S3 Files,用户可以挂载 Amazon S3 bucket,并通过标准文件系统接口访问其中的数据。应用可使用标准文件操作读写文件,系统会自动将其转换为 S3 请求,使计算服务能够直接处理存储在 S3 中的数据。
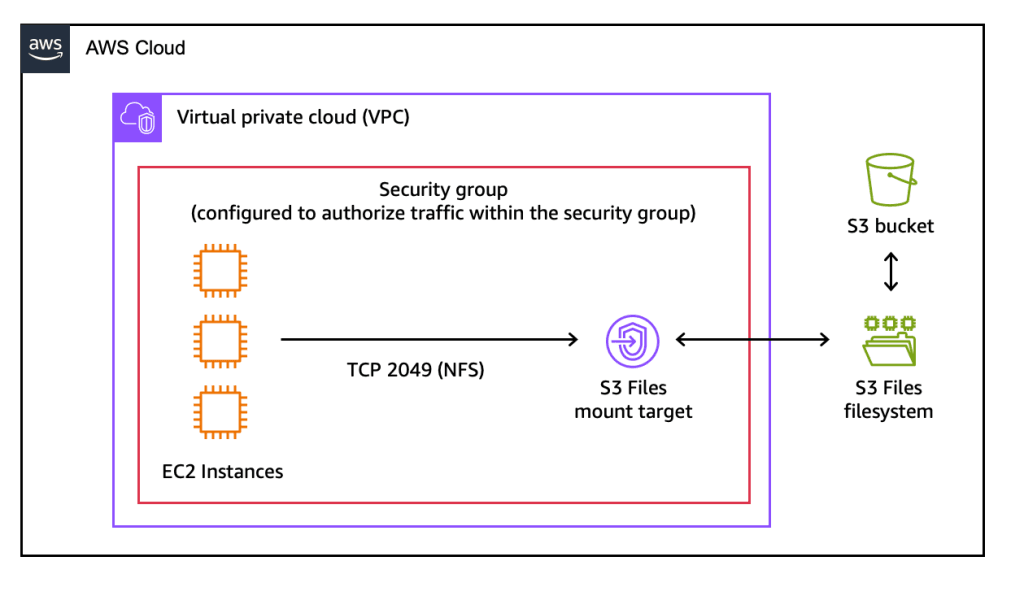
亚马逊云科技首席开发者布道师Sébastien Stormacq解释了bucket在挂载后如何暴露数据:
当你通过文件系统处理特定的文件和目录时,相关的文件元数据和内容会放置到文件系统的高性能存储中。默认情况下,受益于低延迟访问的文件会存储并由高性能存储提供服务。对于未存放在高性能存储中的文件(例如,需要大规模顺序读取的文件),S3 Files 会直接从 Amazon S3 提供这些文件,以最大化吞吐量。
亚马逊云科技表示自己是唯一能够为对象存储提供全功能、高性能文件系统访问能力的供应商,并建议将 S3 Files 用于分析、机器学习、媒体处理等需要共享文件系统访问大规模数据集的工作负载。Stormacq 补充说:
在底层,S3 Files 使用 Amazon EFS,并可为活跃数据提供约 1ms 的延迟。该文件系统支持多个计算资源并发访问,并具备 NFS 的 close-to-open 一致性,非常适合会修改数据的交互式共享工作负载,从通过基于文件工具协作的 Agentic AI Agent,到处理数据集的 ML 训练流水线均适用。
S3 Files 支持智能预取,以预判数据访问需求。客户可以控制文件系统中存储的内容,包括选择加载完整文件数据或仅加载元数据,从而针对特定的访问模式进行优化。Amazon 副总裁兼杰出工程师Andrew Warfield解释了 S3 Files 背后的动机和设计取舍,并给出了一些实现细节。Warfield 写道:
当创建或修改文件时,变更会被聚合,并且大约每 60 秒以单次 PUT 请求的形式提交回 S3。同步是双向进行的,因此当其他应用修改 bucket 中的对象时,S3 Files 会自动发现这些修改,并自动反映到文件系统视图中。如果出现两侧同时修改文件的冲突,S3 是事实源,文件系统版本会被移动到 lost+found 目录,并通过 CloudWatch 指标标记该事件。30 天未访问的文件数据会从文件系统视图中逐出,但不会从 S3 删除,因此存储成本会与活跃工作集成正比。
一些开发者对亚马逊云科技给一个长期被称为“不是文件系统”的服务加上文件系统接口这件事做出了调侃式的反应。与此同时,更广泛社区的反馈呈现两极化,有人认可其更简单的开发体验,也有人担心潜在的成本。
在“S3 Is Not a Filesystem (But Now There's One In Front of It)”一文中,Corey Quinn称赞了该实现(“他们并不是简单给 S3 套一层 POSIX 就敷衍交差”),强调了它与Mountpoint for Amazon S3的差异,认为其定价模型合理,并分析了它与 EFS 定价的对比。
费用会按 S3 文件系统中的存储数据量计费,同时也会对小文件读取、所有写操作,以及用于在文件系统与 S3 bucket 之间同步数据的 S3 请求计费。在一个热门Hacker News讨论帖子中,用户 MontyCarloHall 评论道:
这本质上是 S3FS:用 EFS(亚马逊云科技托管的 NFS 服务)作为活跃数据和小随机访问的缓存层。不幸的是,这也意味着它会带来 EFS 那种令人咋舌的定价。
S3 Files 运行在 EFS 基础设施之上,并按设计采用相同的定价;但由于它仅对文件系统上的小规模高频访问数据计费,因此即便单价一致,总成本仍可能更低。Provenant CTODzhuneyt Ahmed在测试这一新选项后,指出了当前的限制:必须启用 S3 版本控制,发布时不支持基础设施即代码(Infrastructure as Code),且 IAM 配置不够直观,信任策略使用的是 EFS 服务主体(service principal)和 S3 Files 的特定条件。
在另一项公告中,Amazon S3 推出了新的默认安全设置,对新的和现有 bucket 禁用了使用客户自提供密钥的服务端加密(SSE-C)。
S3 Files 现已在亚马逊云科技全部区域正式可用。
原文链接:
AWS Introduces S3 Files, Bringing File System Access to S3 Buckets




