
阿里巴巴的合伙人团队名单里,又增加了一个熟悉的名字。
阿里云 CTO、通义实验室负责人周靖人正式成为阿里巴巴合伙人。

合伙人团队是阿里的最高集体决策机构,在今年 6 月大幅收缩后(从之前的 26 人降至上市以来最低的 17 人),这个团队现在终于迎来了第一次增补。
这并不是一次简单人事变动,此决定发生在关键的技术换挡窗口:大模型从“能用”走向“要落地”,云厂商从“拼算力”转向“拼体系化 AI”。
据晚点消息,周靖人之所以成为阿里合伙人今年的首位新增成员,是因为他负责的 通义实验室 过去一年努力 保证了 千问(Qwen)的模型领先地位,阿里管理层高度对此成绩给出高度评价。
下面来具体说说,阿里为什么在此刻要把技术人推向最高决策层?
十年,从首席科学家到合伙人
2025 年,阿里巴巴将 AI 战略 从“技术叙事”升级为“生死线”。
今年 2 月,阿里集团官宣,未来三年将投入至少 3800 亿元,用于云计算与 AI 基础设施建设,该金额 超过公司过去十年在相关领域的投入总和,为 C 端业务落地奠定基础。
马云亲自督战,开始频繁点名周靖人,要求他持续汇报 Qwen3 的进展,理由很直接:AI 将成为阿里未来十年的主要增量,而模型是整个体系的第一变量。
而从阿里首席科学家到合伙人这条路,周靖人一走就是十年。
我们先看看阿里合伙人的门槛有多高:
阿里选拔合伙人的要求,除了在阿里工作 5 年以上、高度认同公司文化、对公司发展有积极贡献、愿意为公司文化和使命传承竭尽全力,还需要 75% 的合伙人赞同才能当选,也就是 17 位合伙人需要至少 13 人投赞成票。
目前阿里合伙人名单,除了众所周知的掌舵人马云、 CEO 吴泳铭、主席蔡崇信,还有蚂蚁副总裁邵晓锋,淘天总裁的闻佳,阿里 CPO(首席人才官)蒋芳,负责淘天的蒋凡,负责达摩院的张建锋,负责阿里云的蒋江伟等。

周靖人 1999 年毕业于中科大少年班,2004 年获得美国哥伦比亚大学计算机博士学位,后加入微软担任研发合伙人。
2015 年,他加入阿里出任阿里云首席科学家,之后转岗多次:刚开始在阿里云负责 iDST(数据科学与技术研究院,达摩院前身),随后负责电商的搜索推荐广告,2020 年底转去蚂蚁,一年多之后回到阿里云担任 CTO、兼达摩院副院长。
在技术方面,他为阿里云打造的飞天系统和神龙计算架构,让阿里云计算跃居全球前列,尤其是在 2018 年的双十一,他带领的团队每秒处理 17 亿条日志,扛过了“全球最猛交易洪峰”。他还作为核心负责人主导构建 iDST(阿里数据科学研究院),并主导打造全球领先的 MaxCompute 大数据引擎,让阿里的海量数据实现商业价值转化。
在业务层面,他将淘宝搜索重构,打造新一代语义理解引擎;又参与推动阿里妈妈的整合,打造搜广推一体化;并参与个性化算法设计,成为阿里算法领域核心负责人之一,这些都将淘宝业务推上顶峰。
他带领达摩院期间,成立达摩院智能计算实验室,不仅推动图计算、自然语言处理、多模态等前沿技术研发,还为阿里培养数百名 AI 顶尖人才,产出 50 + 顶会论文,16 项专利。
负责阿里云后,又推动 "飞天 + 神龙 + 磐久 AI 服务器" 三位一体架构,使 AI 算力利用率达 90%,训练成本降低 30%。
在大模型浪潮中,周靖人率先提出 “模型即服务” 理念,并发起国内最大 AI 开源社区魔搭 ModelScope,一口气开源了达摩院成立 5 年来研发的所有近 400 个模型,使魔搭成为国内外模型首发首选平台。
可谓是,既做过前沿技术研发,也完成实际业务落地。
2023 年,他开始主导通义实验室,推动 Qwen 系列大模型技术突破。

周靖人推动 Qwen 系列完成从 0.5B 到 480B 的全尺寸技术布局,并同步建立覆盖文本、图像、语音、视频的全模态开源矩阵。更重要的是,这套能力被放在阿里自有云上完成训练与推理优化,形成从底层到产品的闭环体系。
现在,Qwen 已在开源生态中跃升为全球最具影响力的模型族之一,实现下载量 7 亿 +,衍生模型 18 万 +。
苹果被曝选择 Qwen 成为中国的大模型合作伙伴,李飞飞团队用 Qwen 来训练超低成本推理模型,通用 Agent 产品 Manus 也调用 Qwen 来做决策规划,DeepSeek-R1 的部分小尺寸模型也用到了 Qwen 来训练......
除了千问,周靖人也没有放松对阿里云的押注。
作为全球四大“超级 AI 云”之一,阿里云今年正处在激烈胶着的竞争环境中。
在国内机场广告位的激烈争夺中,阿里云打出了锋利的口号:“AI 云市场份额领先,超过第 2–4 名总和”。
对此,周靖人向媒体强调,阿里是全球极少数能在大模型与云计算两端同时做到全栈自研的公司,而这一能力,正是它在这场长期战中的真正护城河。
这一系列成果,使周靖人在阿里内部的角色进一步提升。他的晋升,被视为集团强化 AI 核心战略的信号, 其技术领导力与组织管理能力被寄予厚望,需在激烈竞争中带领团队实现更确定的成果。
在谈及未来的发展目标时,周靖人的思路依然围绕模型与云的协同。他认为大模型的每一次突破,背后是整个云计算和数据、工程平台的全面配合和升级。
在模型方向上,阿里会继续推进推理模型的演化,使其具备更贴近人类思考方式的能力,并在未来具备自我反思与自我纠错的潜质;多模态被视为迈向通用智能的关键路径,模型必须能够真正理解并贯通不同模态的信息。
同时,团队也在探索新的学习机制,让模型能在线、持续、自主学习,而不再依赖完全离线式的版本化训练流程。
在基础设施层面,阿里正强化云与模型的深度融合。尤其是工程能力、整个云系统结合 AI 的性能和效率会变成核心竞争力。
在他看来,全球 AI 已进入加速期,比拼的是迭代速度和创新能力,而不是“憋大招”。阿里快节奏发布,是通义大模型体系化演进的表现。
通义实验室和 Qwen
周靖人负责阿里巴巴的通义实验室,起源于阿里达摩院内部的大模型与多模态 AI 团队。
随着阿里内部架构调整,“语言/视觉/多模态大模型 + AI 应用基础设施” 方向从达摩院剥离,在 2023 年重组后归属阿里云系统并由阿里云 CTO 统筹管理。
通义实验室的定位,既不是传统科研机构那种“纯学术、基础研究”,也不仅是单纯的产品团队——它兼顾“研究 + 工业化 + 商业落地”。
也就是说,通义实验室既关注大模型、前沿 AI 技术,也强调这些模型能够服务于阿里生态内外、落地到业务和产品。
通义实验室下的二级部门,设有:自然语言智能实验室、语音实验室、应用视觉实验室、智能计算等。
团队背后还有一批年轻的骨干:1990 年生、2017 年北大博士毕业的周畅曾主导千问基础模型研发;而 2019 年以应届生身份加入阿里的林俊旸,如今已以 P10 职级接任这一团队负责人,也成为了阿里最年轻的 P10 专家。不过 2024 年,周畅从阿里离职,初期对外宣称 “创业”,后被曝加入了字节跳动。

图:林俊旸
要说通义实验室的成果,目前最重要的就是 通义大模型 系列,主要涉及 四大方向:自然语言、视觉、视频,和语音,包括:通义千问系列、通义万相 - 图像生成系列、通义万相 - 视频生成系列、语音合成与识别系列。

APP 月活破 3000 万,Qwen 竟还被 Meta 拿去训练新模型
作为通义大模型“全家桶”之一,Qwen 系列目前是其中关注度最高的一个。
Qwen 从原有的多模态大模型 M6 的基础上进化而来,是一系列大规模开源的大语言模型(LLM),具备语言理解、对话、推理、多模态(文本 + 图像 + 音频 + 视频)等能力,于 2023 年 4 月对企业用户开启内测。
它不是一个模型,而是一个 “大模型家族矩阵”,目前已经更新到了第三代,即 Qwen3。
最早公开的基础版本 Qwen1,主要面向通用文本理解和生成任务;Qwen2 改进了表现和多语言能力,包含 Dense 及部分 Specialize 版本。
Qwen2.5 是一个重要迭代分支,延伸出了多个能力更细化的模型,包括 Qwen2.5-Max、Qwen2.5-VL-32B-Instruct、Qwen2.5-Omni-7B,围绕 “多语言 + 多模态 + 指令交互” 能力展开升级。
而 Qwen3 系列既有能完成高难知识问答、内容生成、Agent 任务的模型,预训练的自然语言种类数从 Qwen2.5 的 29 种扩展到了 119 种(含方言);也有又快又便宜的模型;还有编程专用模型和全模态实时模型 Omni,Omni 版本强调“端到端统一多模态”,而非多个模型拼接。
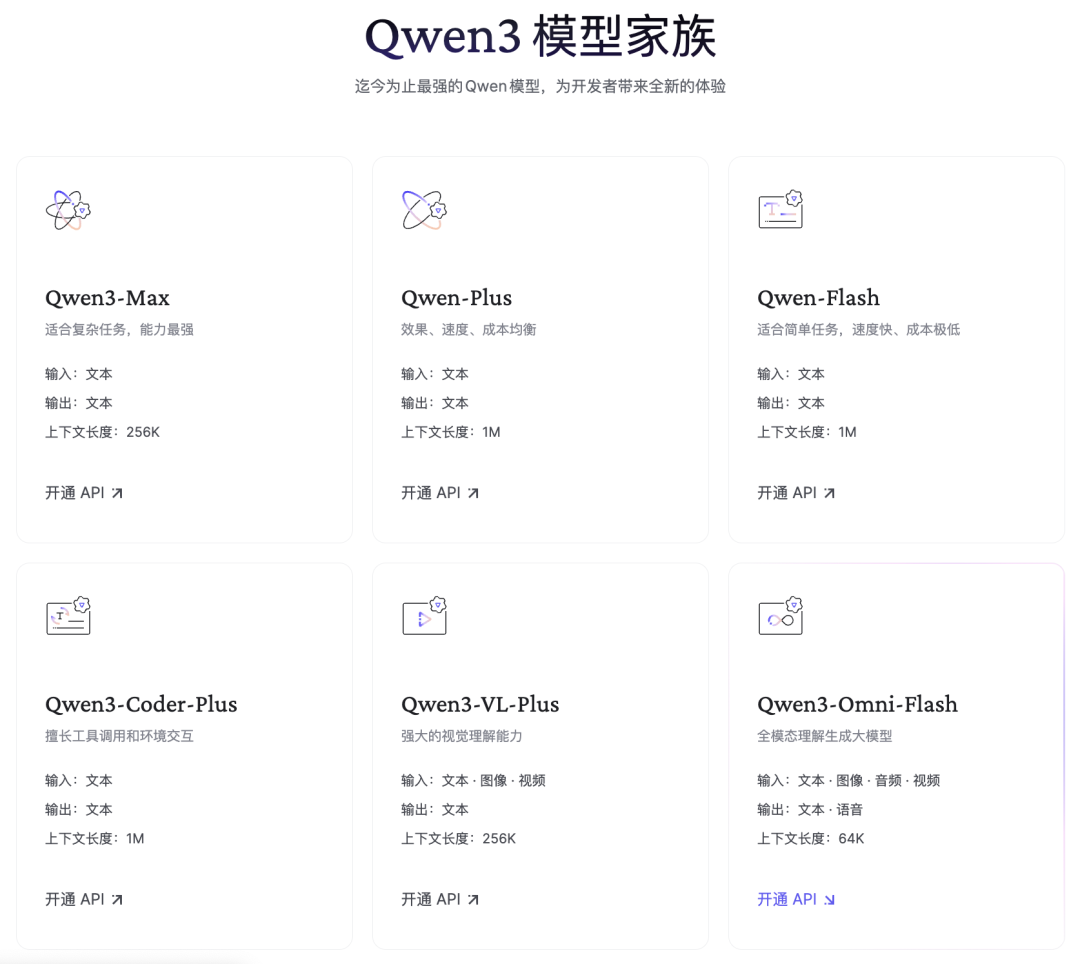
Qwen3 还拥有多种尺寸,既有混合专家(MoE)架构也有 Dense 架构版本;其中规模最大、能力最强 Qwen3-Max 参数量超万亿,预训练数据更是达到 36 万亿 tokens。
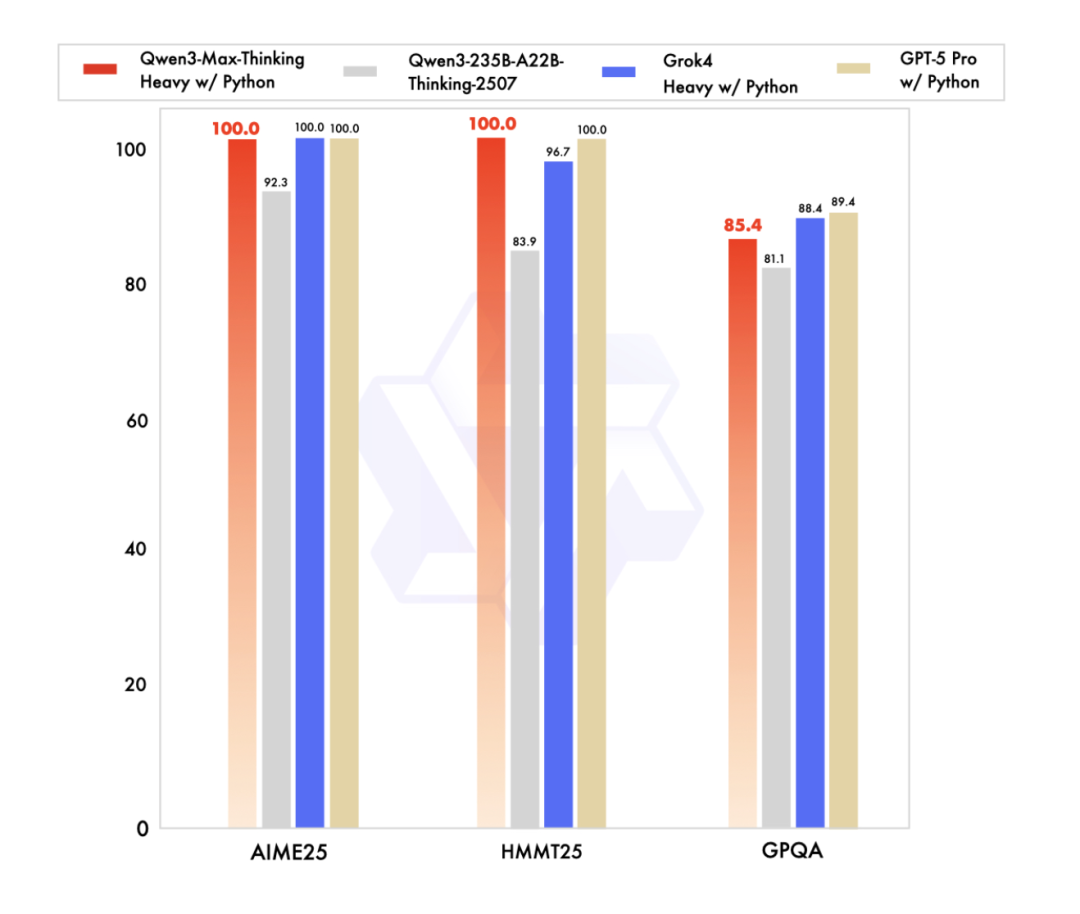
Qwen3-Max-Thinking(思考模式)在极具挑战性的数学推理基准测试 AIME 25 和 HMMT 上,均取得了满分,也是国产大模型首次在这两个数学评测榜单拿下满分。
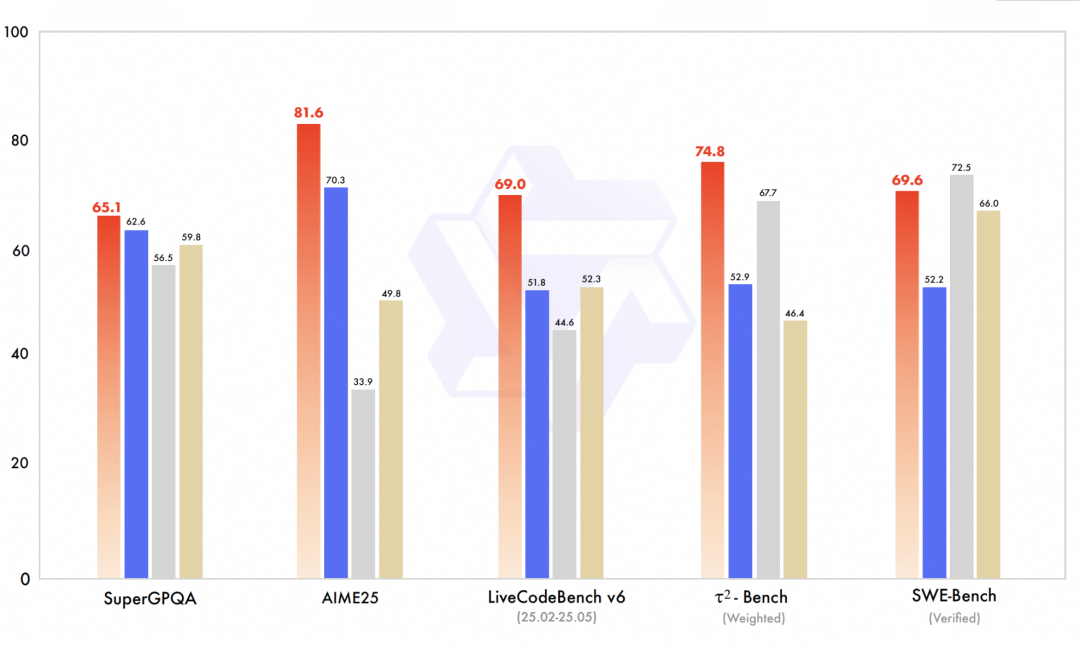
在考察 Agent 工具调用能力的 Tau2 Bench 测试中,Qwen3-Max-Instruct(指令模式)打败了 Claude Opus4 和 DeepSeek V3.1;还在考察大模型用 coding 解决真实世界问题的 SWE-Bench 评测中也取得了亮眼成绩。
Qwen3 之所以这么强,一个重要原因是它引入了 “混合推理”(Thinking + 非 Thinking 模式) 机制,再加上 thinking budget:可以给模型一个“思考额度”(比如允许多少 thinking token),让其动态切换模式。
它支持更强推理能力、长上下文、多语言和多模态能力,也覆盖了从基础通用语言、视觉、多模态到代码 / 专业任务的多种能力矩阵。
也就是说,你不再需要单独的一个“解题、推理模型”和一个“日常对话模型”,Qwen3 能解决一整套问题。
11 月 17 日,阿里宣布千问项目全力进军“AI to C”市场,通义千问 Qwen App 公测版同步上线,正式与 ChatGPT 展开全面竞争,还免费开放、人人可用——当天还因为想用的人太多而崩了。
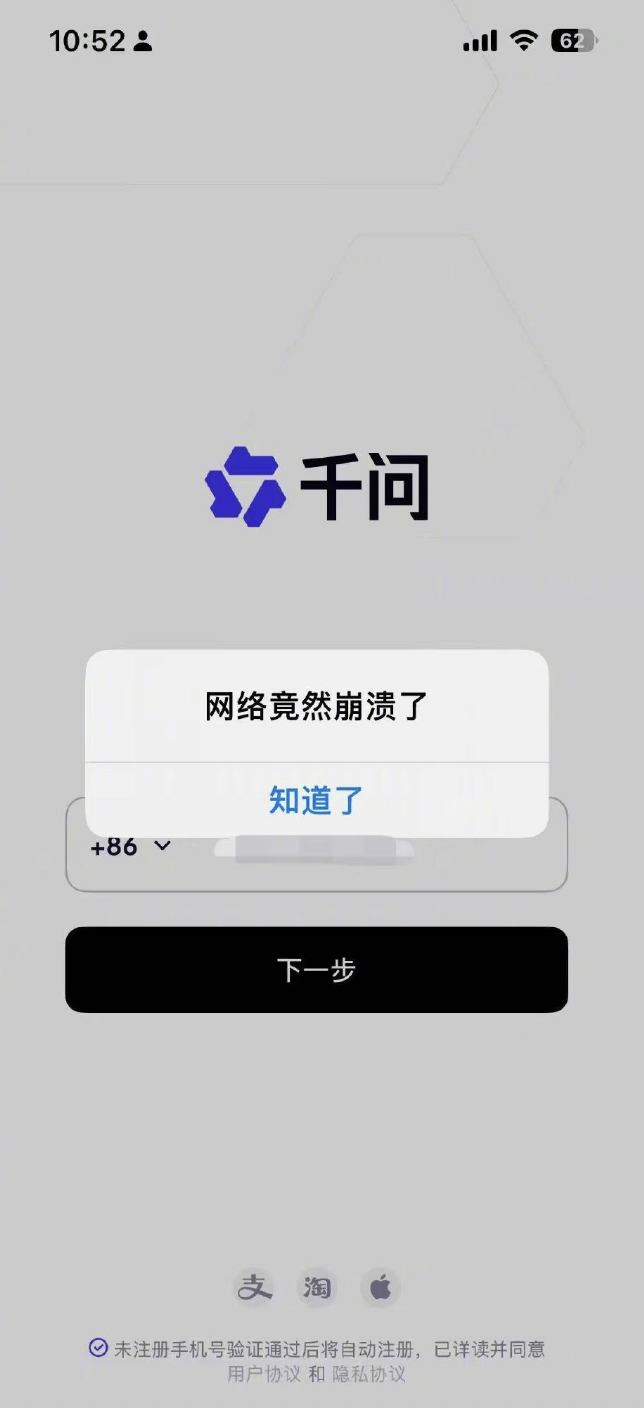
公测 23 天后,阿里发出喜报:千问月活已经突破 3000 万。

另外有意思的是,彭博社消息显示,Meta 将在明年春季发布一个名为 Avocado(牛油果)的模型,而且“牛油果”在训练过程中还 拿了 Qwen 作参考或蒸馏源来进行优化。
据彭博社和 CNBC 消息,Meta 虽然过去主要走开源路线(如 Llama 系列),但他们的“牛油果”大概率是闭源的——也就是说,Meta 可能要用一些开源的模型(除了 Qwen 还有 谷歌的 Gemma 系列、OpenAI 的 GPT-oss),搞出一个闭源的模型。
不过,对于“牛油果”在训练过程中具体如何使用 Qwen,目前还没有具体的公开信息。
参考链接:
https://help.aliyun.com/zh/model-studio/what-is-tongyi?utm\_source




