
Netflix 推出了一个新的工程专业化领域——媒体机器学习数据工程(Media ML Data Engineering),以及一个旨在大规模处理视频、音频、文本和图像资产的媒体数据湖。早期成果包括在标准化媒体上训练的更丰富的机器学习模型、更快的评估周期,以及对创意工作流程的更深入洞察。
在最近的一篇博客文章中,该公司描述了这种演变如何将其数据工程功能从“事实和指标”表格转向直接支持机器学习的媒体内容上的。
通过正式化角色和平台,Netflix 旨在提供标准化的、适用于机器学习的数据处理集,并在本地化、媒体恢复、评级和多模态搜索等领域实现更快的实验。
Netflix 的数据工程团队曾经专注于用于指标、仪表板和模型的结构化表格。然而,随着工作室业务的扩大,他们面临着大规模的多模态、非结构化媒体——视频、音频、图像和文本——的洪流。
这些资产与创意工作流程和血统相关联,引入了传统流程无法管理的复杂性,从而催生了急需新方法的需求。
为了应对这一挑战,Netflix 创建了媒体机器学习数据工程,这是一个位于数据工程、机器学习基础设施和媒体制作交汇处的专业化领域。这些工程师构建和维护媒体数据湖的流程,标准化资产,丰富元数据,并为研究和生产提供适用于机器学习的语料库。
合作是核心:他们与领域专家、研究人员和平台团队合作,确保解决方案满足技术和创意需求。
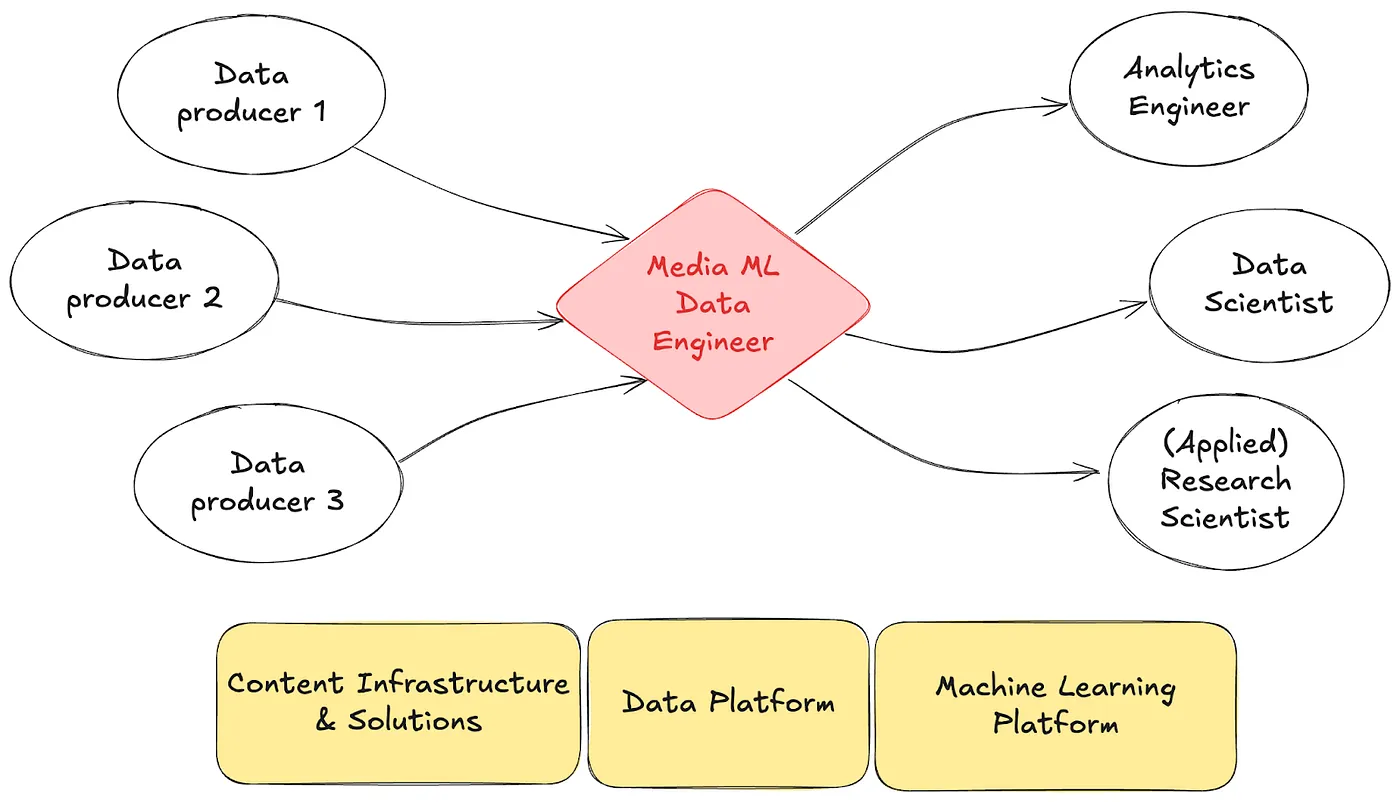
(媒体机器学习数据工程师)
媒体数据湖是专门为存储和服务媒体资产及其元数据而设计的。该数据湖由LanceDB提供支持,并集成到 Netflix 的大数据生态系统中。
核心是媒体表,这是一个结构化的数据集,可以捕获所有媒体资产的元数据和引用,还可以存储机器学习输出,如嵌入。Netflix 指出,通过将元数据与嵌入等输出相结合,媒体表可以实现复杂的矢量查询和多模态搜索实验。
支持组件包括一个标准化的数据模型、一个 Pythonic 数据 API、用于探索的 UI 工具,以及实时查询和大规模批处理系统。总之,这些共同使得媒体资产可以被搜索、探索,并为大规模的机器学习训练做准备
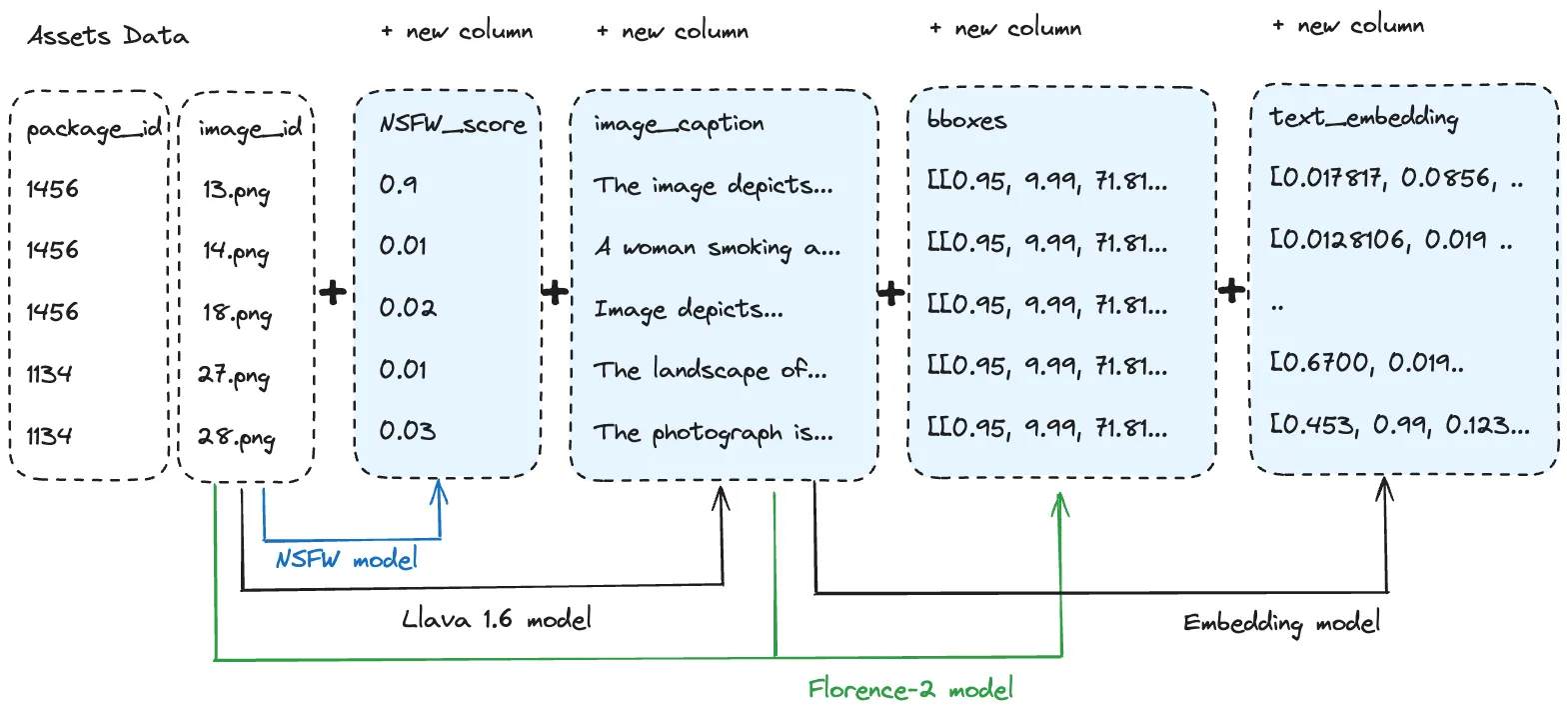
(媒体表)
这些表格已经为多个应用程序提供了支持,包括使用 TTS 模型的翻译和音频质量指标、HDR 视频修复、吸烟或血腥内容的合规性检查,以及跨帧、镜头和对话的多模态搜索。
Netflix 将这些例子作为证据,表明媒体表不仅仅是一个存储层,而且是新的创意和运营维工作流程的驱动力。
在实现这些用例之前,Netflix 首先建立了一个范围有限的“数据池”,专注于其内部资产管理系统和注释存储中的视频和音频。该公司报告称,这种有限的推广使他们能够在进一步扩展之前降低引入新技术的风险,并确保一个坚实、可扩展的基础。
展望未来,Netflix 强调了已经出现的好处:在标准化媒体上训练的更丰富、更准确的机器学习模型、更快的评估周期、更快的新 AI 功能产品化,以及对创意工作流程的更深入洞察。
该公司计划进一步扩展媒体数据湖,并与更广泛的数据工程社区分享未来的学习成果。
原文链接:




