
时至 2026 年初,AI 行业光靠“讲故事”(包括但不限于 AGI、颠覆一切、指数级跃迁......)已经开始不够用了。
吴恩达、斯坦福、谷歌云团队接连抛出多份报告,都透露出一个共同信号:AI 行业的焦点,已经从“能不能做到”,变成了“在什么条件下、以什么成本、为谁创造价值”。
斯坦福 HAI(斯坦福以人为本人工智能研究院)明确指出,2026 年,是 AI 从 evangelism(布道)走向 evaluation(评估)的一年。

一方面,大量企业已经完成了第一轮生成式 AI 的部署,开始有条件回看投入与产出。
有人开始重新算账。
谷歌云发布了一份报告,名为 The ROI of AI 2025(2025AI 投资回报率),调查了 3466 名全球营收千万美元以上的企业老板或高管。

这份报告展现的答案也挺明确:真正实现正向、可持续投资回报的,并不是零散的生成式 AI 能力,是“Agent+流程+ 组织”的系统级落地。
数据也很直接:在最早一批入场 Agentic AI 的公司里,有近多九成已经在至少一个 GenAI 场景中看到了正向回报,并且越吃越香。
另一方面,AI 正以前所未有的速度渗透进医疗、法律等高风险、高责任领域,单靠“能力展示”已经无法支撑决策。
吴恩达在《The Batch》新年特刊里,直指“AGI”概念被过度滥用,并提出“图灵-AGI 测试”重新界定上限。
斯坦福以人为本人工智能研究院(HAI),则联合计算机、医学、法律、经济学等多学科教授发布年度预测,明确提出“2026 年是 AI 从布道走向评估的一年”
这些报告背景各异,有产业一线、有跨学科研究机构、有长期做工程落地的团队。但都传递出一个信号:AI 不再只问“能不能做到”,而是要回答“在什么场景下、以什么成本、替谁承担风险”。
放在 AI 正在经历关键转向的当下,这几份报告难得不靠口号撑场子、信息密度很高,值得放在一起细品。
Scaling Law 不够用了,AI 评价标准被重写
过去几年,AI 行业其实并不缺“共识”。
其中最重要的一条,就是 Scaling Law:模型越大、数据越多、算力越强,能力就越好。参数规模、榜单名次,一度成了衡量进步最直观、也最省事的标准。
但当 AI 真正进入法律、医疗等高风险场景时,这套逻辑开始显得单薄——
分数上涨,并不等于风险可控;能力增强,也不代表系统可落地。
于是,一些长期站在产研一线的人开始意识到:核心问题不仅是“模型还能不能更强”,而是现有评价体系,是否已经跟不上应用场景的复杂度。
AI 大牛吴恩达,在其年度通讯《The Batch》新年特刊中提了个引人注目的问题:
“在 2026 年,我们能最终真的实现 AGI 吗?”

说到 AGI,其实目前行业和学界对此还没有统一的定义,更缺乏统一、可信的评测体系。而且在吴恩达看来,更棘手的是,“AGI”已经被滥用:
“AGI 已经变成了一个炒作术语,而不是一个具有精确含义的术语......当企业炒作他们可能在几个季度内实现 AGI 时,他们通常试图通过设定一个非常低的标准来证明这些说法。”
这些导致学生误判未来(不敢学某些专业)、CEO 错判投资节奏,以及社会整体对 AI 能力产生了系统性高估。
在吴恩达看来,这种过度炒作并非第一次出现。在 AI 发展史上,几次著名的“寒冬”往往并不是源于技术本身停滞,而是源于预期被抬得过高、最终崩塌,继而引发投资迅速撤离。
在此背景下,为了更好地实现真正的 AGI 目标,他要做一个新的图灵测试,名曰“图灵-AGI 测试”。
经典的图灵测试,由“计算机科学之父”艾伦·图灵在 1950 年提出,核心标准是:通过纯文字对话,如果人类评审无法分辨对方是机器还是人,机器就算通过测试。
不过,这对今天的 AI 已明显不足,但其中“由人判断结果是否达到人类水平”的逻辑,被保留并扩展到了更多样、真实的工作场景中:除了对话,还有接电话、处理任务、交付成果等,并且还得持续反馈与调整。
为了让人类裁判有更深入、细致的体验,一个实验周期往往长达多天、甚至是数周。
那么,这个测试与当前主流的 Benchmark(AIME、GPQA、SWE-bench 等)又有何不同?
在吴恩达看来,当前的大部分基准测试都有这些局限:题目固定、路径可预期,模型很容易被“对题训练”。它们难以反映 AI 真的足够“智能”,比如是否具备长期规划、持续学习和跨任务迁移的能力。
相比之下,图灵-AGI 测试关心的是另一件事——它考的不是“会不会解题”,而是 AI 能否在任务不预设、路径不可控、反馈持续变化的条件下,把一件事从头到尾真正完成。
吴恩达认为,现有的 AI 系统,想要通过他们团队设立的图灵-AGI 测试,将面临极高难度和诸多挑战;他甚至还放出一句“反直觉”的话:
“如果现在所有 AI 都通不过这个测试,那反而是一件好事。”
图灵-AGI 测试的意义在于:如果有 AI 能通过,那就是强有力的信号;如果没有,也正好为过热的市场按下“冷静键”。
如果说,吴恩达提出的新测试是在关注的,是一个偏 AI“上限”的问题,那企业与研究机构更迫切需要回答的,则是一个偏“现实”的问题:AI 在当下的真实业务中,已经创造了多少价值,值不值得大规模用、怎么用?
斯坦福大学的计算机科学、医学、法律和经济学的教授们,最近联合发布了一份报告,标题非常直白:Stanford AI Experts Predict What Will Happen in 2026(《斯坦福 AI 专家预测 2026 年将发生什么》)。
这些 HAI 的研究者们一起点出:AI 布道时代正在让位于评估;即将到来的一年将由严谨性、透明度和长期忽视的实用价值而非投机承诺所定义。

简单来说,就是过去几年,AI 行业几乎只在算“能力账”,却系统性地回避了“经济账”,现在是时候好好算下钱的问题了,比如这些“灵魂拷问”:
企业为了用 AI,多花了多少钱?
节省的时间和人力,有没有被新流程吃掉?
维护、合规、算力、幻觉兜底,成本算过吗?
斯坦福的学者们们在多个领域(尤其是法律、医疗、写作类工作)都观察到一个现象:AI 的“单点能力”提升,并不必然带来整体效率提升。
有时候甚至是反效果:输出更多,但人要花更多时间核查;写得更快,但错误更隐蔽;看似节省人力,但引入新的协调成本。
他们提出一个观点,即如果 AI 的加入,让系统整体变得更复杂、更难以信任,那它的能力提升并没有什么意义。因此他们特别强调:不能只测模型,必须测 “人+AI+流程” 这个整体。
以法律领域的 AI 为例,ROI(投资回报率)、严谨性和多文档推理这些指标将越来越重要。
至于 AGI,HAI 的联合主任 James Landay 和计算机科学院教授们,直接给其泼了盆冷水:
“My biggest prediction? There will be no AGI this year.(我最大的预测是?今年不会 AGI。)”
不过,这并不意味着技术停滞。相反,他们认为,AI 主权在今年有很不错的前景——但这里的“主权”并不是比拼谁的模型更大,而是模型跑在哪里、数据由谁掌控。

与此同时,对全球不断升温的算力投入,斯坦福 HAI 也发出了警告:过去一年,超大规模数据中心建设明显加速,但算力投资不可能无限加码,当资本持续涌入却迟迟看不到回报拐点时,这种热度本身就带有泡沫意味。
传播学副教授、HAI 高级研究员 Angèle Christin 说得更直白:“Deflating the AI Bubble .(戳破 AI 泡沫)”她表示,特别期待看到更多关于 AI 能做什么、不能做什么的细致实证研究。这不一定意味着泡沫破裂,但泡沫可能不会变得更大。
说完学界,再看看在产业一线,AI 目前的价值到底如何?
谷歌云近日发了份含金量颇高的报告:The ROI of AI 2025(2025AI 投资回报率),调查了 3466 名全球营收千万美元以上的企业老板或高管。
这里面传递出的信号很清晰,即 AI 讨论的重心,正在从“模型有多强”,转向“系统能不能持续赚钱”——说得再激进点:且不谈 AGI,先看 ROI。
谷歌也给出了一个明确的答案:真正实现正向、可持续投资回报的,并不是零散的生成式 AI 能力,是“Agent + 流程 + 组织”的系统级落地。
数据也印证了这一点。88%早期入坑 Agentic AI 的企业,已经在至少一个 GenAI 场景中看到了正向回报,并且越吃越香。但拉开差距的,和选了哪家模型关系并不大,而是这几件事:
有没有高层拍板、持续背书
有没有愿意为 AI 重做流程,而不是只加工具
有没有把一半以上的 AI 预算,真正投到 Agent 上
所以,老板和高管怎么理解 AI,直接决定它的价值能否快速兑现——有清晰 C-level 战略和持续背书的公司,78%已经看到正向回报;而目标分散的组织,AI 往往只是“用过、试过”,却很难真正改变财务结果。
技术路径出现拐点:从大模型到 Agent 体系
如果说前几年 AI 的核心问题是“模型能不能更强”,那么现在,当模型够强之后,问题变成了怎么把它真正用进系统里。
在谷歌的这份 ROI 报告里,提到了 118 次 Agent(或者 Agentic)。
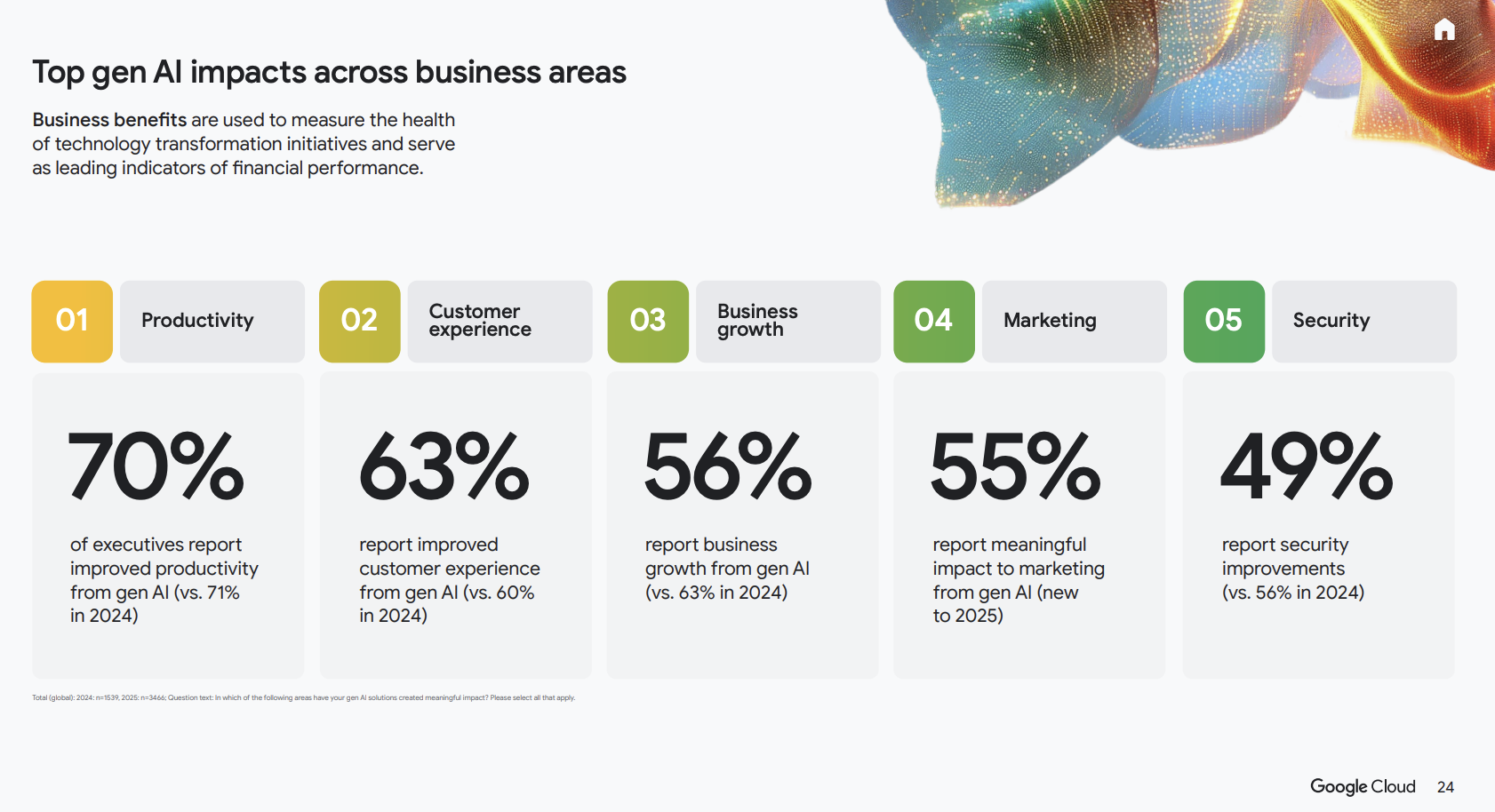
报告显示,AI Agent 已经在生产环境中大规模部署:在使用 GenAI 的企业中,已经有一半以上(52%)把 Agent 投入生产环境。
而且真正能让 AI 获得正向 ROI 的,集中在这几类流程清晰、可以规模化复制的场景:
生产力:减少重复劳动、压缩处理时间
客户体验:更快响应、更稳定交付
业务增长:缩短销售周期、提升转化效率
营销:规模化内容与投放优化
安全:减少误判、提前发现风险
这些场景有一个共同点:它们不是靠模型“更聪明”取胜,而是靠 Agent 嵌进流程、替人干活产生回报。
不过其实 Agent 和 Agent 之间的能力差别也是巨大的,就像智能驾驶分等级一样,谷歌给 Agent 按效果或者说进化路径分了三个等级:
Level 1:是大家最熟悉的生成式 AI 阶段:聊天、检索、生成内容,本质是“一次输入、一次输出”的工具能力展示。
Level 2:这才是真正意义上的 Agent。它不只回答问题,而是能理解目标、拆解任务、调用工具,并在一个流程内把事情做完。
Level 3:则是多 Agent 协同的工作流:不同 Agent 分工协作,由系统统一编排,像一个可调度、可扩展的“AI 团队”。
一级是工具,二级是产品,三级是系统。
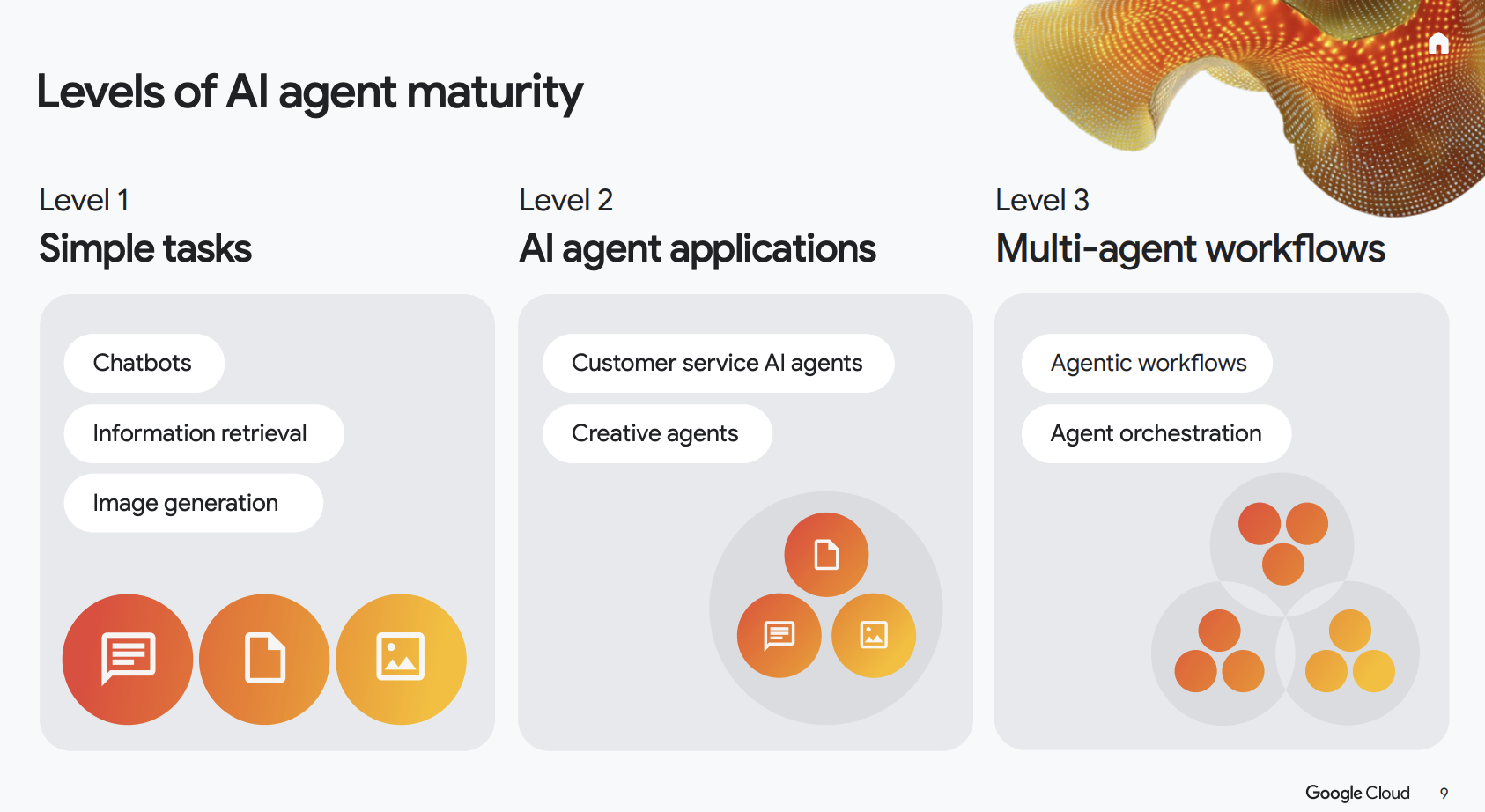
值得注意的是,目前绝大多数已经产生正向 ROI 的 Agent,都集中在 Level 2。
客服 Agent、销售支持 Agent、内容与运营 Agent,基本都属于“单体 Agent + 明确流程”的形态。它们能嵌进业务、算得清成本,也更容易被组织信任。
在 2026 年,Agent 的下一步,并不是盲目“堆更多智能体”,而是“更可管理”,让多个 Agent 在清晰分工和明确规则下,稳定地协作起来。
要达成这样的效果,让吴恩达来看,得把能力拆细、边界划清,比如解决掉这些问题:谁来拆任务?谁真正去干活?中途翻车了谁兜底?最后的结果到底算谁的?最终让 Agent 像流程里的员工一样稳定干活——即 Skill- First。
Skill 是最近 AI 圈一个大热的新词,直译过来是“技能”;在 AI 技术语境下,你可以将其理解为 Agent 的“技能模块”。
一次搜索、一次写作、一次代码生成、一次审批判断、一次风控校验、一次执行动作,都是一个边界清楚、可被调用、可被复用,还能被监控的 Skill。
与其说未来是“多 Agent 协作”,不如说是 Agent 在调度一堆 Skill,比如:
什么时候查资料,用某个搜索 Skill;
什么时候写文案,用某个生成 Skill;
什么时候需要人介入,用审批或风控 Skill 接管。
要知道,目前真正跑出 ROI 的系统,往往不是最复杂、最炫的多 Agent 网络;而是 Skill 拆得够细、流程跑得够顺、责任链条说得清楚的 Agent 系统。
总而言之,Agent 的天花板,最终不取决于它“认识多少同伴”,而取决于它能不能把一组技能,按业务节奏稳定地用起来、跑下去、算清账。
在 Agent 这件事上,吴恩达可以算是“Skill 派”。
虽然他不一定频繁使用 “Skills” 一词,但他的思路本质上就是 Skill-first:他反对把 AI 能力打包成模糊的“通用智能”,强调可验证、可组合、可评估的能力单元。
这应该也是他反对 AGI 被滥用的原因之一:一旦不拆解能力,就无法判断边界,也无法管理风险。
所以在吴恩达的体系里,Agent 就像能调用一组能力、完成工作的人,而 Skill 就是可以被训练、验证、组合的具体组件。
AI 是一门长期生意,当故事讲完、潮水退去,能留下来的,恐怕只会是那些被长期运行、被持续信任的系统。
参考链接:
https://hai.stanford.edu/news/stanford-ai-experts-predict-what-will-happen-in-2026
https://cloud.google.com/resources/content/roi-of-ai-2025?hl=zh-CN&utm_source




