
当开发者通过 API 消费 Twitter 的公共数据时,他们需要获得可靠性、速度和稳定性方面的保证。因此,在不久前,我们推出了 Account Activity Replay API(https://developer.twitter.com/en/docs/twitter-api/enterprise/account-activity-api/guides/activity-replay-api),帮助开发者们提升他们系统的稳定性。这个 API 是一个数据恢复工具,开发者可以用它来检索最早发生在 5 天前的事件,恢复由于各种原因(包括在实时传递时突然发生的服务器中断)没有被传递的事件。
除了构建 API 来提升开发者体验,我们还做了一些优化:
提高 Twitter 内部工程师的生产力。
保持系统的可维护性。具体来说,就是尽量减少开发人员、站点可靠性工程师和其他与系统交互的人员的上下文切换。
基于这些原因,在构建这个 API 所依赖的回放系统时,我们利用了 Account Activity API 现有的实时系统设计。这有助于我们重用现有的工作,并最小化上下文切换负担和培训工作。
实时系统采用了发布和订阅架构。为了保持架构的一致性,构建一个可以读取数据的存储层,我们想到了传统的流式技术——Kafka。
背景
两个数据中心产生实时事件,事件被写入到跨数据中心的主题上,实现数据冗余。
但并不是所有的事件都需要被传递,所以会有一个内部应用程序负责对事件进行筛选。这个应用程序消费来自这些主题的事件,根据保存在键值存储中的一组规则来检查每一个事件,并决定是否应该通过我们的公共 API 将消息传递给特定的开发者。事件是通过 Webhook 传递的,每个 Webhook URL 都有一个开发人员负责维护,并有唯一的 ID 标识。
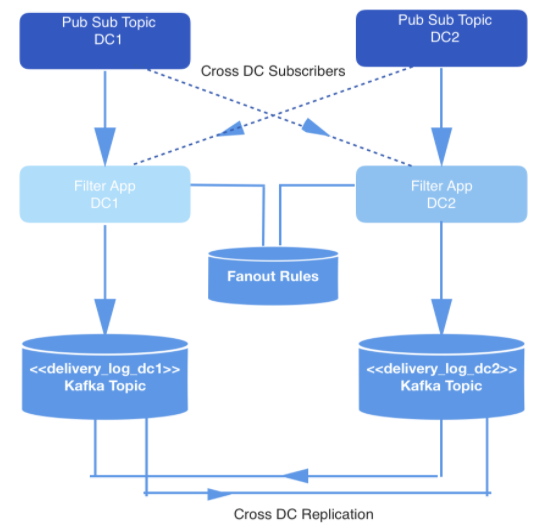
图 1:数据生成管道
存储和分区
通常,在构建一个需要存储层的回放系统时,人们可能会使用基于 Hadoop 和 HDFS 的架构。但我们选择了 Kafka,主要基于以下两个原因:
已有的实时系统采用了发布和订阅架构;
回放系统存储的事件量不是 PB 级的,我们存储的数据不会超过几天。此外,执行 Hadoop 的 MapReduce 作业比在 Kafka 上消费数据成本更高、速度更慢,达不到开发者的期望。
要利用实时管道来构建回放管道,首先要确保事件被存储在 Kafka 中。我们把 Kafka 主题叫作 delivery_log,每个数据中心都有一个这样的主题。然后,这些主题被交叉复制,实现数据冗余,以便支持来自数据中心之外的重放请求。事件在被传递之前经过去重操作。
在这个 Kafka 主题上,我们使用默认的分区机制创建了多个分区,分区与 WebhookId 的散列值(事件记录的键)一一对应。我们考虑过使用静态分区,但最终决定不使用它,因为如果其中一个开发人员生成的事件多于其他开发人员,那么这个分区包含的数据将多于其他分区,造成了分区的不均衡。相反,我们选择固定数量的分区,然后使用默认分区策略来分布数据,这样就降低了分区不均衡的风险,并且不需要读取 Kafka 主题的所有分区。重放服务基于请求的 WebhookId 来确定要读取哪个分区,并为该分区启动一个新的 Kafka 消费者。主题的分区数量不会发生变化,因为这会影响键的散列和事件的分布。
我们使用了固态磁盘,根据每个时间段读取的事件数量来分配空间。我们选择这种磁盘而不是传统的硬盘驱动器,以此来获得更快的处理速度,并减少与查找和访问操作相关的开销。因为我们需要访问低频数据,无法获得页面缓存优化的好处,所以最好是使用固态磁盘。
为了最小化存储空间,我们使用了 snappy 压缩算法(https://opensource.google/projects/snappy)。我们知道大部分处理工作都在消费端,之所以选择 snappy,是因为它在解压时比其他 Kafka 所支持的压缩算法(如 gzip 和 lz4)更快。
请求和处理
在我们设计的这个系统中,通过 API 调用来发送重放请求。我们从请求消息体中获取 WebhookId 和要重放的事件的日期范围。这些请求被持久化到 MySQL 中,相当于进入了队列,直到它们被重放服务读取。请求中的日期范围用于确定要读取的分区的偏移量。消费者对象的 offsetForTimes 函数用于获取偏移量。
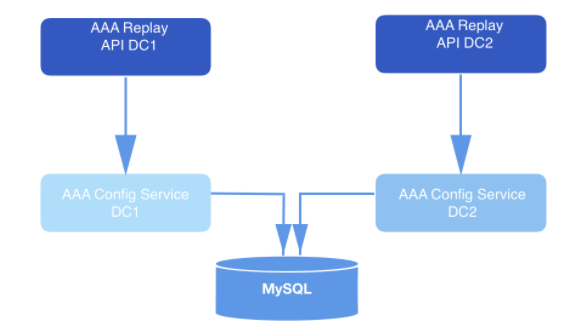
图 2:重放系统接收请求,并将请求发送给配置服务(数据访问层),然后被持久化到数据库中。
重放服务处理每个重放请求,它们通过 MySQL 相互协调,处理数据库中的下一个需要重放的记录。重放进程定期轮询 MySQL,获取需要被处理的挂起作业。一个请求会在各种状态之间转换。等待被处理的请求处于开放状态(OPEN STATE),刚退出队列的请求处于启动状态(STARTED STATE),正在被处理的请求处于进行中状态(ONGOING STATE),已处理完成的请求将转换到已完成状态(COMPLETED STATE)。一个重放进程只会选择一个尚未启动的请求(即处于打开状态的请求)。
每隔一段时间,当一个工作进程将一个请求退出队列后,它会在 MySQL 表中写入时间戳,表示正在处理当前的重放作业。如果重放进程在处理请求时死掉了,相应的作业将被重新启动。因此,除了将处于打开状态的请求退出队列之外,重放操作还将读取处于已开始或正在进行中的、在预定义的分钟数内没有心跳的作业。
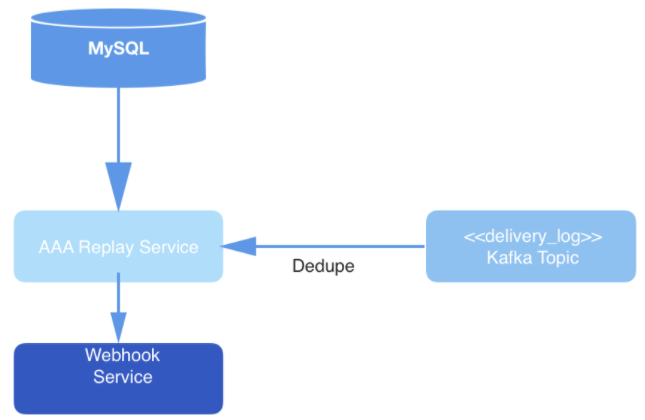
图 3:数据传递层:重放服务通过轮询 MySQL 来读取作业,消费来自 Kafka 的消息,并通过 Webhook 服务传递事件。
在读取事件时会进行去重操作,然后事件被发布到消费者端的 Webhook URL 上。去重是通过维护被读取事件的散列值缓存来实现的。如果遇到具有相同散列值的事件,就不传递这个事件。
总的来说,我们的解决方案与传统的将 Kafka 作为实时、流式系统的用法不一样。我们成功地将 Kafka 作为存储系统,构建了一个 API,在进行事件恢复时提升了用户体验和数据访问能力。我们利用已有的实时系统设计让系统的维护变得更加容易。此外,客户数据的恢复速度达到了我们的预期。
原文链接:
https://blog.twitter.com/engineering/en_us/topics/infrastructure/2020/kafka-as-a-storage-system.html




