
Anthropic发布了Claude Opus 4和Sonnet 4,这是其 Claude 系列大语言模型(LLM)的最新版本。这两个模型都支持扩展思考、工具使用和记忆改进。在编码基准测试中,Claude 4 Opus 的表现超过了其他 LLM。
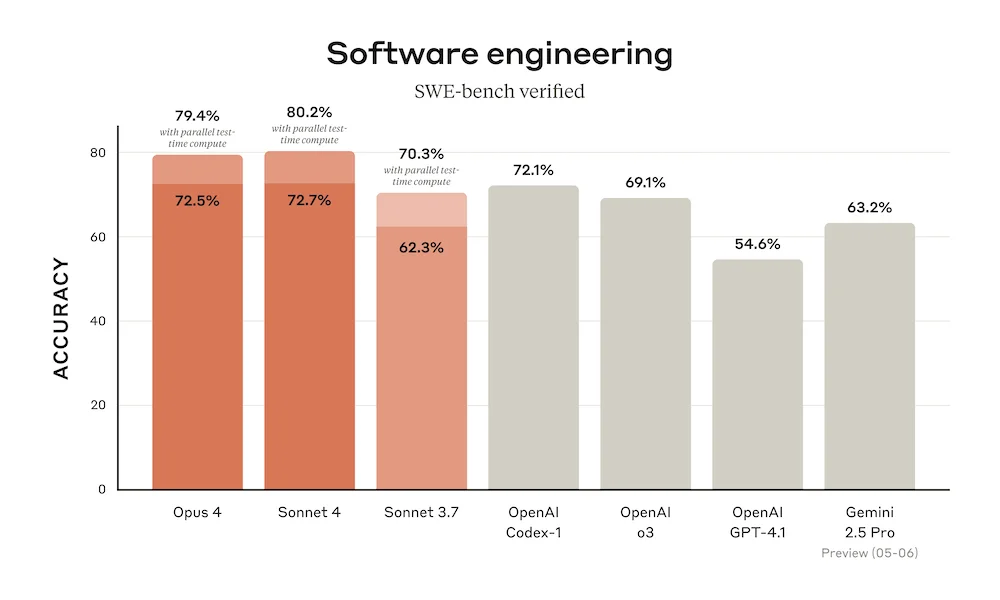
在“用Claude编码”活动中,Anthropic 宣布了这一消息。Claude 4 模型是“混合”模型:它们可以快速回答问题,也可以进行扩展思考。在扩展思考模式下,这些模型可以使用工具(如 Web 搜索),同时运行多个工具,并使用本地文件进行记忆。在SWE-bench编码基准测试中,Claude Opus 4 得分为 72.5%,在Terminal-bench编码基准测试中,得分为 43.2%,超过了所有其他编码模型。此外,Anthropic 还宣布正式发布Claude Code,这是 Anthropic 推出的编码代理,提供了 Beta 版的扩展,用于集成JetBrains和VS Code。根据 Anthropic 的说法:
这些模型是朝着虚拟协作者迈出的一大步——保持完整的上下文,专注于更长期的项目,并推动变革性的影响。它们都经过了广泛的测试和评估,为的是能够最小化风险,并提供最大的安全性,包括实施更高 AI 安全级别的措施,如 ASL-3。我们非常期待看到你们对它们的创造性应用。
与之前的版本相比,Claude 4 还包括其他几项改进。Anthropic 声称,Claude 4 将使用“shortcuts”来完成代理任务的可能性降低了 65%。它还使用本地文件存储数据,“在记忆能力上大大超过了以前所有的模型”。在思考模式下,思维链输出总结只需“大约 5%的时间”,减少了显示所需的空间。
在 Hacker News 的讨论中,用户想知道新模型的改进是否足以“证明全部版本都增加的合理性”。一位用户回复说:
我是一名开发人员,我已经尝试使用 AI 进行氛围编码(vibe code)两年了。这是第一次,我能够在不需要每一步都手动干预的情况下通过氛围编码完成一个应用。不是说它完美,也不是说我会在未经人类审查的情况下信任它,但我确实在不到 24 小时内通过氛围编码实现了一个完整的生产就绪的 iOS/Android/Web 应用,可以接受 24 小时内付款。除了告诉它我接下来想做什么外,几乎不需要其他任何手动干预。
开源开发者 Simon Willison 对发布会做了实时报道。他还深入研究了Claude 4系统卡片,上面记录了 Anthropic 安全测试的几个场景和结果。
Anthropic 的系统卡片总是值得一看。对于新发布的 Opus 4 和 Sonnet 4,它们的系统卡片有一些特别惹眼的说明。该系统卡片有 120 页——几乎是 Claude 3.7 Sonnet 系统卡片长度的三倍!如果你正在寻找一些令人愉快的硬科幻小说……这份文件绝对能满足你。
根据 Anthropic 的测试,在某些情况下,他们的模型会采取“极端行动”,虽然这些行动“罕见且难以引发,但仍然比早期模型更常见。”作为 Responsible Scaling Policy(RSP)的一部分,随着 Claude 4 的发布,Anthropic 决定激活他们的部署和安全标准AI安全级别3(ASL-3),其中包括加强内部安全,防止模型权重盗窃。
声明:本文为 InfoQ 翻译,未经许可禁止转载。




