
4 月 20 日深夜,Kimi K2.6 发布并开源。它最值得被探讨的,并非又赢了几个 Benchmark,跑分逼平乃至反超海外三巨头。这些数字反映的更多是理论上限,而非你我实际上手时的真实水平。

图注:K2.6 基准测试成绩。在 DeepSearchQA、SWE-Bench Pro 等核心 Agent 与代码评测项目中位居第一,在 Humanity's Last Exam 等博士级难度测试中持平或优于三巨头(GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro),整体成绩处于同级别模型的第一梯队。
K2.6 更现实的意义,还在于它抛出了一个关键命题:
当模型步入 Agent 时代,竞争内核已从“单次作答的灵光乍现”,跃迁为“多步执行的善始善终”。Agent 的价值不再停留于输出答案,而在于多步执行、对象管理、结构维护与增量更新中的系统承载能力。
这才是新一代模型真正的分水岭。
循此判断,笔者摒弃了常规的单点用例测试,转而借 Andrej Karpathy 的 AI Wiki 思路,设计了一组高承压任务。这套思路自 AK 大神在本月初提出,迅速出圈狂揽两千万曝光,被视为“检索增强的下一代范式”。
测试目的直指 Agent 底层能力:它能否超越单纯的“内容生成”,展现出将内容组织为结构、将结构推进为系统的建构能力。
比写代码难得多的任务
如果只是验证代码能力,最简单的做法是复现网页、写个应用。直接,出活快。但这测的只是局部优势,而非 Agent 的工作流承接力。
所以,Andrej Karpathy 的 AI Wiki 成了更优选。它表面是搭网站,内核却是一套知识编译系统。 这也正是它比普通 RAG(检索增强生成) 更难的地方。
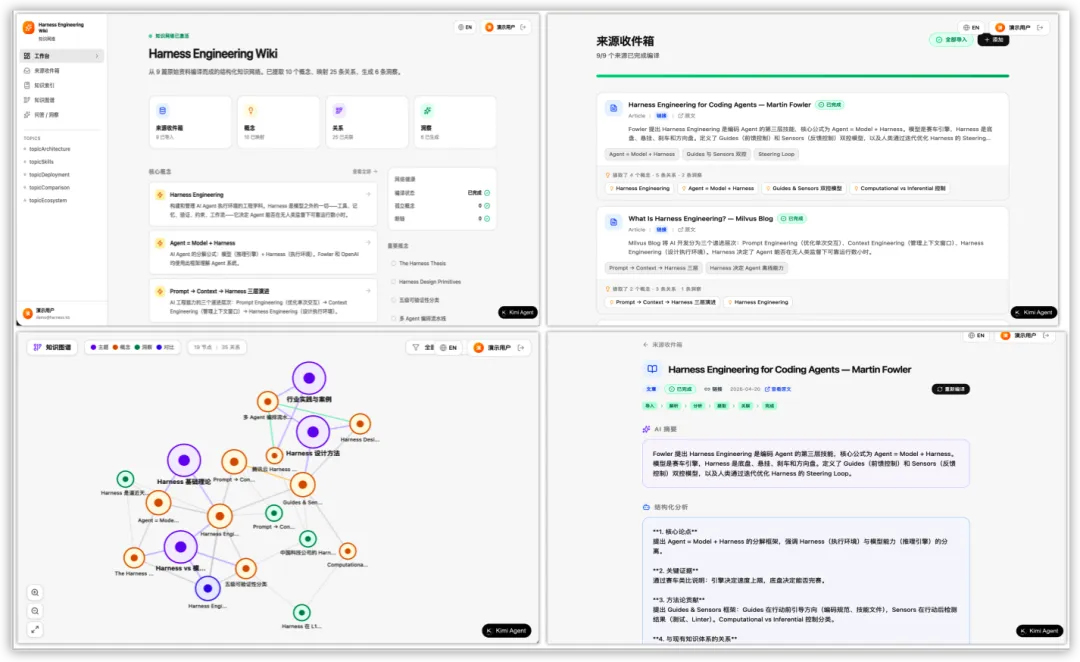
图注:基于 K2.6 Agent 搭建的一套 Harness Engineering Wiki,已形成可检索、可路由、可写回的知识闭环系统,具备持续演化的工程知识库形态。效果可参见:https://f24e2z3zeghre.beta-ok.kimi.link/
很多人一听“AI 知识库”,认为还是老一套:切片、建索引、检索、生成。每次问答都从零开始,毫无沉淀。
而 AK 大神的破局点,正在于把“查资料”变成了“整理知识”,将无状态检索(即没有记忆,不留痕迹)推进为有状态编译。这体现在 Wiki 极清晰的三层架构上:

架构之外,更有精髓。AI Wiki 的真正价值,在于把知识系统的重心从“文档展示”转向了“对象构建”。原始资料喂进去,不直接吐长文,而是先拆解为主题、概念和来源,再织成一张可检索、可连接、可扩展的网络。
页面 UI 只是表皮,底层真正拷问的是:对象稳不稳?关系立不立得住?新信息进来,旧结构会不会崩?
但原版的 Wiki 思路不是没有短板:偏本地。它回避了线上系统的致命问题:对象如何持久化?增量如何接入?旧结构如何防覆盖?前后台如何同步?
所以,这一次我们不做简单复刻,而是将其从一套离线编译流程,改造为可在线运行、持续更新、前台可访问的知识网络。从离线走向在线,从生成走向系统。
这也天然地覆盖了当前 Agent 最该被检验的五大能力:
长链执行:持续推进,而非单轮结束
结构组织:拆为对象,而非停留于段落
系统维护:新信息入网,旧结构不崩
前台落地:组织成可用的界面,而非仅存于后台
任务拆解:规模扩大时,能否并行处理
为什么要用 K2.6 来测?
Kimi K2.6 值得测,恰恰在于它这次强化的几条主线,与这类任务高度重合。
从官方披露的信息看,K2.6 的提升并不只停留在参数和榜单,而是明确落在了三种更接近系统任务的能
力上:长链执行、Vibe Coding 与 Agent 集群。
先看长链执行。官方给出的案例里,K2.6 能在复杂任务中连续运行 12 小时以上、调用上千次工具、完成 4000 余行代码修改;在主动式 Agent 框架中,甚至给出了最长 5 天持续自主运行的能力描述。
这类指标的意义,不只是“它更耐跑了”,而是它开始具备承接持续任务的基本条件。
而 AI Wiki 恰恰不是一次性生成任务,它要求模型能够在对象抽取、关系组织、页面生成和后续维护之间不断往返。没有足够强的长链稳定性,这类任务很容易在中途塌掉。
再看 Vibe Coding。K2.6 这次另一条被明显强化的能力,是将代码、视觉理解与前端表达结合起来,直接交付专业级 Web 应用。对于 AI Wiki 来说,这一点并不只是“页面更好看”——它意味着模型不只要会整理知识,还要能把知识网络做成一个可浏览、可使用、可继续扩展的前台系统。
换句话说,AI Wiki 不是纯知识抽取任务,必须落地成可浏览、可交互的前台界面。这正是 K2.6 突出的强项。
最后是 Agent 集群。 官方披露,K2.6 的集群架构最高支持 300 个子 Agent 协同,并且明确强调了它在搜索、深度研究、文档分析和长文创作等任务中的协同能力。
这对于 AI Wiki 也非常关键。因为一旦输入资料一多,任务就很容易从“一个 Agent 持续推进”转向“多个 Agent 分工处理”。也就是说,AI Wiki 不只是一条长链任务,它天然也具备被 Swarm 化的潜力。
具体来看,这次任务至少包括四个关键环节:
消化与编译(Raw Source → 结构化对象) 原始文本不能直接当正文展示,必须先被拆解、提纯,编译成主题、概念、对比关系与来源,形成结构化对象层。难点在于:多步骤信息处理中,模型的准确性和连贯性在这里最先暴露。
联网与落地(对象层 → 可用前台系统) 基于编译结果生成 Topic 页、Concept 页、对比页、关系图谱,并保证页面之间形成跳转闭环。这考察的是 Vibe Coding 能力:结构能不能真正变成可用的产品。
调用与反哺(知识问答 → 持续沉淀) 页面之间不只有链接,还要能表达相似关系、对比关系和来源回溯,把"页面集合"推进成"知识网络"。跨页面操作中的一致性,是这一步的核心考验。
维护与演化(增量接入 → 系统自愈) 新资料进入后,系统要能继续触发编译,支持断链检查和重复概念识别。这测的不是一次性生成的惊艳,而是长程运行中的自我修复与持续生长能力。
此外,为更完整地观察 K2.6 在不同任务组织方式下的能力边界,这次测试并不只在一个执行环境中完成,而是分别考察了它在 单 Agent 、 Agent 网站 和 Agent Swarm (集群) 三种模式下的表现:
其中,单 Agent 作为基线,网页端 Agent 重点考察连续施工能力,Swarm Agent 则进一步测试复杂任务的拆解与协作组织能力。
单 Agent 基准:系统骨架成型,知识闭环待补
如果只给 K2.6 一个基础单 Agent 执行环境作为基准水平,它的表现可以概括为一句话:前台成型很快,系统感很强,但知识闭环最初并没有自然成立。
它最先兑现的,是两项能力。
这轮测试里,K2.6 最先体现出来的,不是单点页面生成能力,而是把复杂任务持续推进成一个完整原型的能力。围绕我们给出的要求,它先后完成了信息架构设计、对象层拆解、页面路由搭建和主要交互补全,逐步做出了 账号登录、工作台、知识索引、主题页 / 概念页、问答 / 洞察面板以及知识图谱 等核心模块。
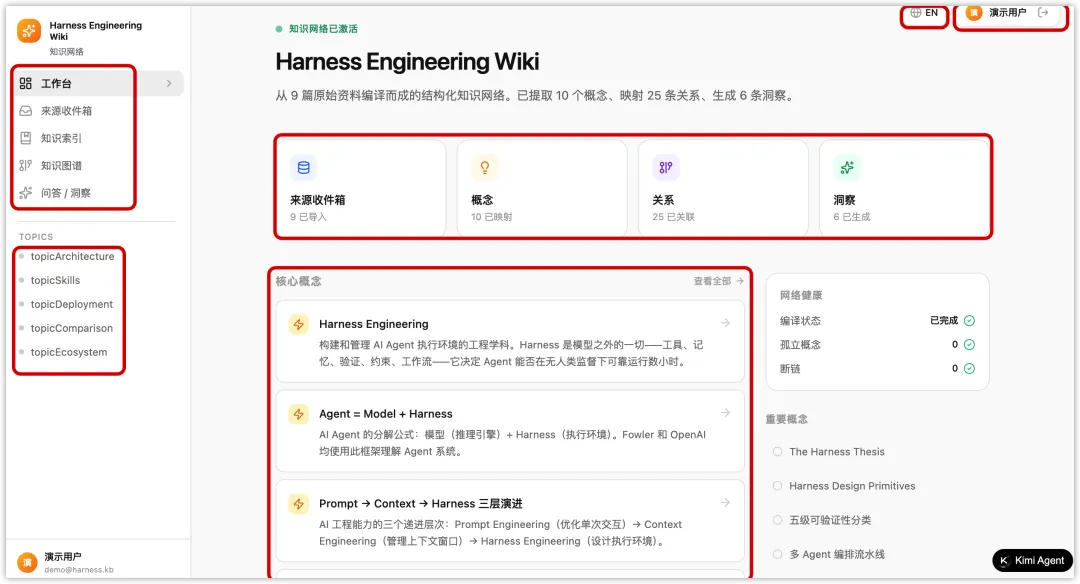
从结果上看,这已经不是一个零散页面集合,而是一套具备明确结构和产品感的知识网络雏形。
这里最值得强调的,首先是它的 长链条任务能力。
AI Wiki 不是一次性生成任务,而是一个需要在资料输入、知识编译、页面生成、关系组织和后续维护之间反复往返的长链工作流。K2.6 在单 Agent 模式下,已经表现出了承接这类任务的基本稳定性:它不是完成一个页面就停,而是能沿着既有上下文持续往前推进,把任务一步步从“做页面”推向“搭系统”。
这一点很重要,因为如果没有足够强的长链稳定性,这类任务通常会很快退化成局部补丁,而无法积累成完整结构。
第二个更突出的优点,是它的 自我修复能力。
单 Agent 模式下,K2.6 并不是一开始就把所有链路都做对了,但它有很强的“沿着当前系统继续修”的能力:页面缺入口,就补路由;对象层不完整,就补实体;跳转不闭环,就补详情页;图谱数据不够,就继续补关系读取。
这种能力的价值在于,它不只是生成一次结果,而是能在连续上下文中维持系统状态,对已有结构做增量修正。这比“第一版就完美”更接近真实工程任务,也更能体现 Agent 的实际承接能力。
同时,K2.6 的 Vibe Coding 能力在这一轮里也相当突出。它不仅能把知识对象落成前台,还能迅速做出风格统一、结构清晰、适合展示的产品界面。换句话说,单 Agent 模式下,它已经证明自己不只是会写页面,而是能把抽象任务迅速组织成一个“像样的系统原型”。
当然,单 Agent 的边界也在这一轮里显露出来。最核心的问题不是页面是否成型,而是 知识链路不会随着页面一起自动成立。也就是说,前台可以很快搭出来,但知识编译、问答调用和沉淀闭环,初始状态下往往还需要继续补强。
更进一步:从单点执行到系统组织
单 Agent 已经给出了基线:它能把复杂任务压成系统原型。接下来的问题是,当执行环境增强,K2.6 能把任务推进多深?
从结果看,网页端 Agent 和 Swarm 模式都带来了明显提升,但方向截然不同:网页端 Agent 强化了对同一系统的连续施工与修正能力;Swarm 模式强化了对复杂任务的拆解、分工与编排能力。
4.1 Agent 网站模式:更强的连续施工能力
“Agent 网站”最突出的特质,不是多做了几个页面,而是能在 同一套系统上连续迭代。
图注:Agent 网站模式的体验入口
在测试中,它围绕既有知识网络持续补全:从编译管线、状态处理到知识图谱,始终保持了极强的上下文延续性。对于 AI Wiki 这类任务,最难的从来不是初版原型,而是多轮修改后系统不散架:对象层有没有被保留?逻辑有没有被延续?网页端 Agent 在这一点上表现出了真正的工程连贯性。
更进一步,它的核心优势在于 能不断重新识别系统的真实约束。
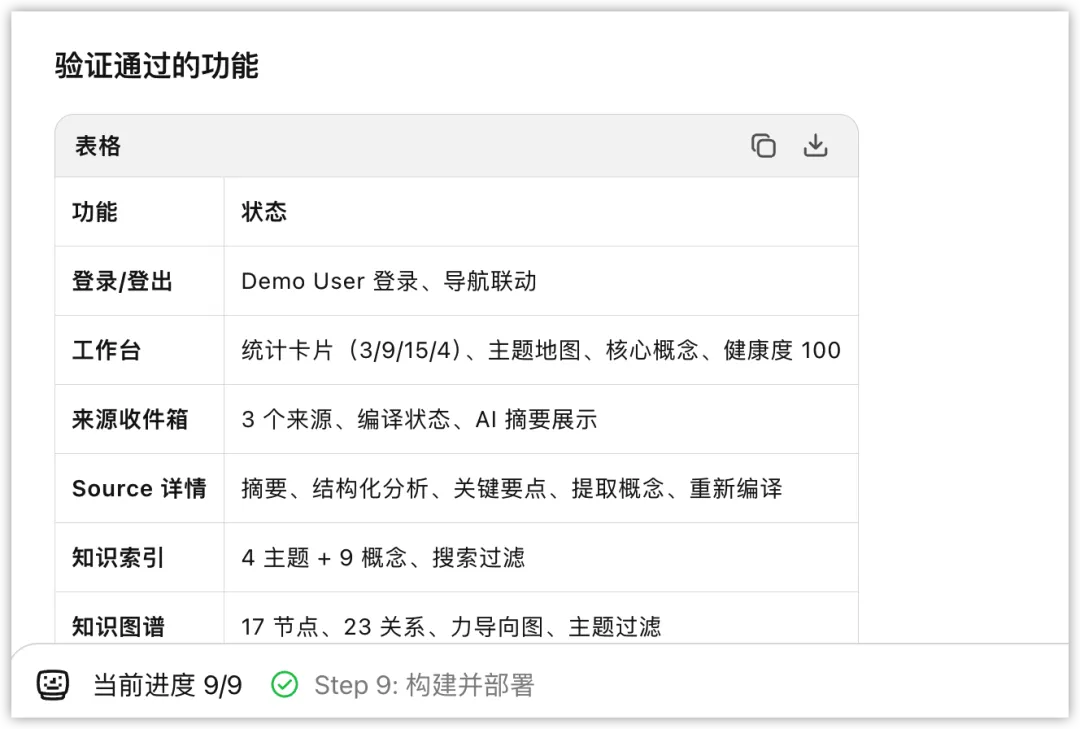
最典型的例子是登录与数据库的实现:它先按标准全栈思路做了认证和持久化,但部署后迅速察觉静态环境无法承载后端服务,于是果断切回本地持久化方案,把产品重新拉回可运行状态。
当然,它的边界也依然存在。Agent 网站模式的典型问题,不是不会推进,而是容易先把前台和交互做成立,再逐步追补底层链路。
4.2 Agent Swarm 模式:不再硬扛,开始组织系统开发
如果说网页端 Agent 是更强的执行器,那么 Swarm 模式带来的则是质的跃迁:它让 K2.6 尝试把任务本身组织成一个可拆分、可协作、可调度 的系统工程。
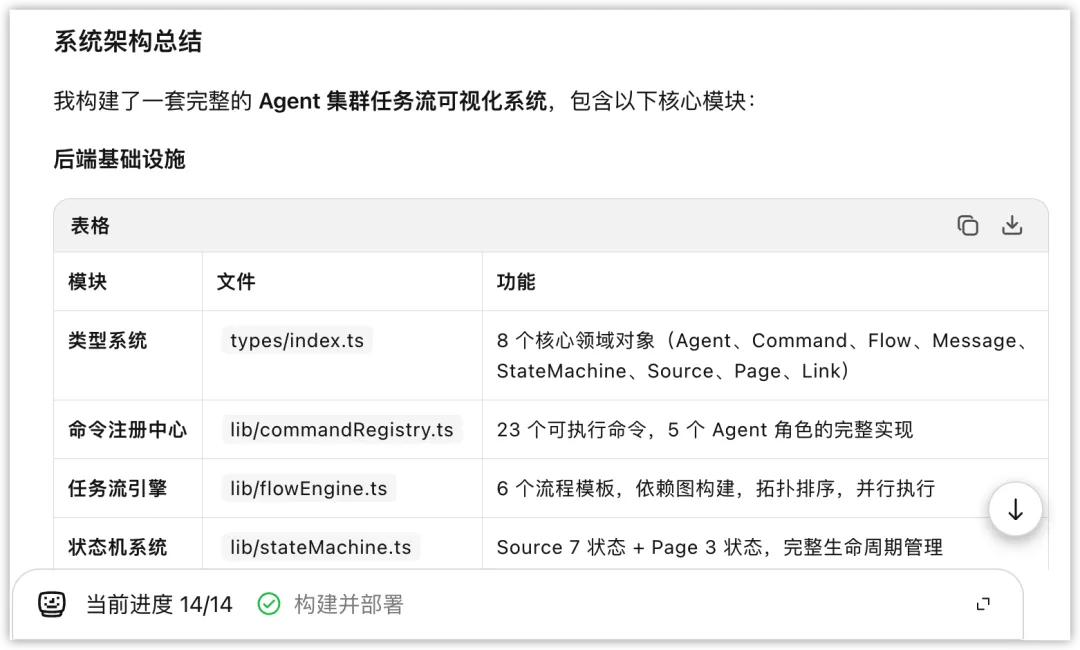
在测试中,Swarm 不再满足于修补现有网络,而是把开发过程抽象成了一套集群工作流:定义 Research、Architect、Compiler 等角色,制定流程模板、命令系统、状态机与消息协议,甚至做出了任务流可视化。
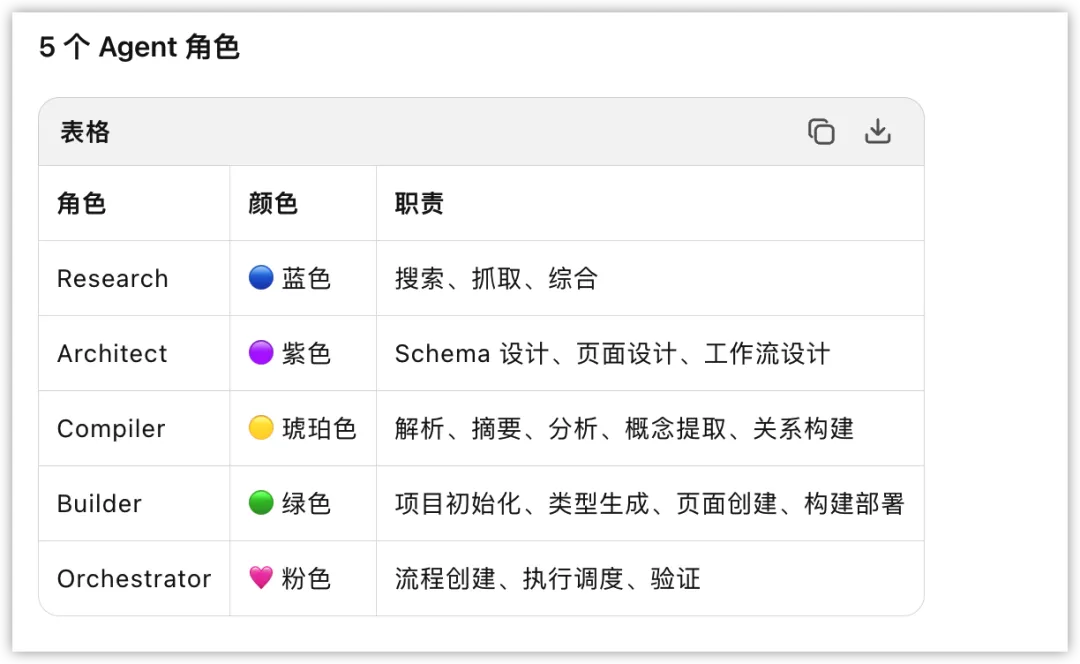
这种变化极其关键。AI Wiki 天然是多线程任务,研究、编译、生成、维护如果全压在一个 Agent 身上,长链路很容易出现崩溃。Swarm 给出的是系统工程的解法:不把所有事硬扛,而是先拆成角色,再组织成流程。
它的深层价值,在于极强的 抽象表达能力。它能把零散的开发过程,重写成结构化的方法体系——谁先做、谁负责、怎么流转、交付什么。这意味着它不仅在执行项目,更在生成一份可复用的“开发语法”。
能力形态开始从“完成一次任务”跃升为“为同类任务生成可复制框架”。
然而,Swarm 的边界也很清楚:方法论和协作框架做得漂亮,但具体执行细节未必同等扎实。不过这恰好印证了它的核心定位:它不是更强的执行模式,而是让复杂任务进入“可分工、可编排、可复用”状态的能力放大器。
4.3 三种模式,三层系统能力
将三种模式放在同一坐标系,比较三者各自最有代表性的 能力形态 与 能力本质 更为清晰。

从“单轮聪明”到“长链存活”
这轮评测下来,我越来越清晰地感受到:模型竞争的重心正在改变。
真正重要的,已经不只是回答得像不像、写得好不好,而是它能不能在真实任务里持续推进、持续修补,并最终把结果落成一个可用的系统。
单 Agent 搭骨架、Agent 网页通经络、 Agent Swarm 做编排,这不仅是对 K2.6 的能力测绘,更是行业下一阶段的预演。
Agent 时代,竞争深水区,已从“谁生成质量更高”转为了“谁的系统存活率更高”。
市场早已厌倦了单轮聪明的玩具。当下真正需要的,是三种硬核特质的系统融合:抗衰减的长链可靠性、遇阻即改的路径校准力、面向系统的结构编排力。




