
整理 | 华卫
最近,Meta 在一份研究报告中揭示了训练 Llama 3 405B 参数模型的重大挑战:该系统在包含 16384 个 Nvidia H100 GPU 的集群上运行,在训练期间平均每三个小时就发生一次故障, 54 天内经历了 419 次意外故障。
这些故障中,有一半以上的情况都归因于 GPU 及其高带宽内存 (HBM3)。由于 GPU 训练任务的规模庞大和高度同步,Llama 3 很容易发生故障,且单个 GPU 故障就会中断整个训练过程,导致必须重新启动。
不过,据介绍,尽管存在这些问题,Llama 3 团队仍在支持自动化集群维护(例如固件和 Linux 内核升级)的同时,实现了超过 90%的有效训练时间(有效训练时间是指实际用于有用训练的时间与经过时间的比例)。
正如一句古老的超级计算谚语所言,“大规模系统唯一可以确定的就是失败。”超级计算机是极其复杂的设备,使用数万个处理器、数十万个其他芯片和数百英里长的电缆。在复杂的超级计算机中,每隔几个小时出现故障是很正常的,而开发人员的主要诀窍就是确保系统在出现这种局部故障时仍能正常运行。
58.7%意外中断源于 GPU,三起事件需要显著人工干预
据悉,在为期 54 天的预训练中,共有 466 次工作中断。其中,47 次是计划内中断,是由于自动化维护造成的,如固件升级或操作员发起的配置更新或数据集更新操作;419 次是意外中断,主要源于确认的硬件问题,包括 GPU、主机组件故障或疑似与硬件相关的问题,如静默数据损坏和未计划的单个主机维护事件。
GPU 问题是最主要的意外中断类别,占所有意外问题的 58.7%,包括 NVLink 等各种 GPU 故障及 HBM3 内存故障。这并不奇怪,因为 Nvidia 的 H100 GPU 消耗约 700W 并承受大量热应力。尽管出现了大量的故障,但只有三起事件需要显著的人工干预,剩下的问题均能由自动化处理。
其余 41.3% 的意外中断是由软件错误、网络电缆和网络适配器混合造成的。有趣的是,在此期间只有两个 CPU 出现故障。
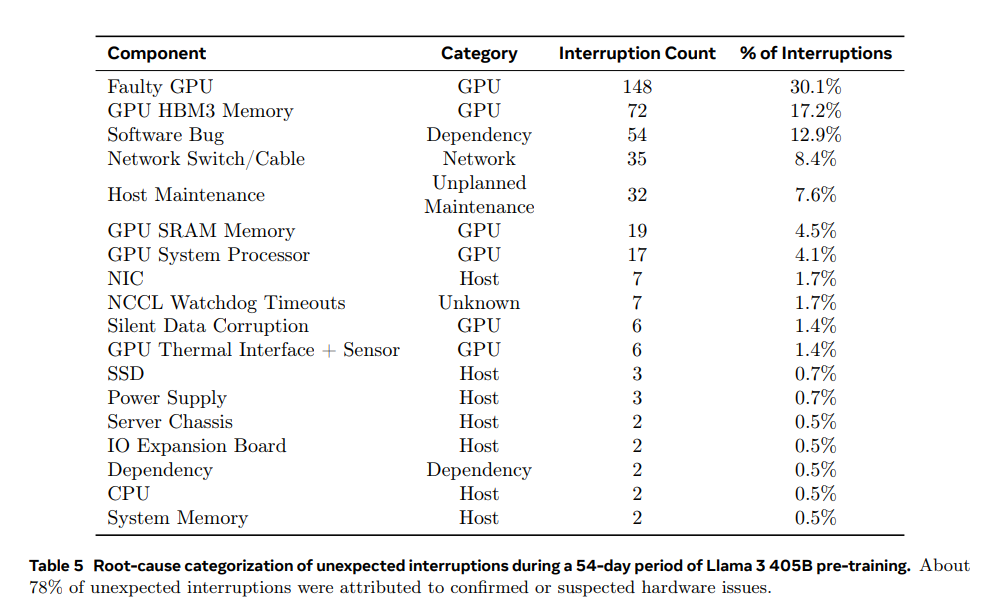
为期 54 天的 Llama 3 405B 预训练期间,对意外中断的根本原因进行分类。
Llama 3 405B 大模型训练团队面临的另一个挑战是数以万计的 GPU 同时发生功耗变化,给数据中心的电网带来了压力。
在训练过程中,成千上万的 GPU 可能同时增加或减少功耗,例如等待检查点完成或集体通信结束,或者整个训练任务的启动或关闭。当这种情况发生时,会导致数据中心的功耗瞬时波动达到几十兆瓦的数量级,可能使电网不堪重负。
而这是一个持续存在的挑战,意味着 Meta 必须确保其数据中心有足够的电力,才能维护 405B 模型以及未来更大规模 Llama 模型的正常运转。随着 AI 模型复杂性的不断增长,所需的计算资源也在增加。
实现 90%有效训练时间背后的努力
为了提高效率,Meta 开发了多种工具和优化策略,包括减少任务启动和检查点时间、广泛使用 PyTorch 内置的 NCCL 飞行记录器,以及识别滞后的 GPU。其中,NCCLX 在故障检测和定位方面发挥了至关重要的作用,尤其是对于 NVLink 和 RoCE 相关问题,与 PyTorch 的集成允许监控和自动超时由 NVLink 故障引起的通信停顿。
据了解,PyTorch 的 NCCL 飞行记录器可以将集体元数据和堆栈跟踪记录到环形缓冲区中,从而能够在大规模的情况下快速诊断和解决挂起和性能问题,尤其是与 NCCLX 相关的问题。另外,由于 Meta 在网络中混合使用了 NVLink 和 RoCE,使得大规模训练中的调试问题变得更加复杂。通过 NVLink 的数据传输通常通过 CUDA 内核发出的加载/存储操作完成,而远程 GPU 或 NVLink 连接的故障通常表现为 CUDA 内核内的加载/存储操作停滞,且不会返回明确的错误代码。
NCCLX 通过与 PyTorch 的紧密协同设计提高了故障检测和定位的速度和准确性,允许 PyTorch 访问 NCCLX 的内部状态并跟踪相关信息。虽然无法完全防止由于 NVLink 故障导致的挂起,但系统会监控通信库的状态,并在检测到此类挂起时自动超时。此外,NCCLX 还会跟踪每次 NCCLX 通信的内核和网络活动,并提供故障 NCCLX 集体的内部状态快照,包括所有等级之间已完成和待完成的数据传输。
有时,硬件问题可能会导致出现仍然运行但速度缓慢的“拖后腿者”,还很难被检测出来。而即使只有一个“拖后腿者”也可能减慢成千上万个其他 GPU 的运行速度,常常表现为正常但速度缓慢的通信。对此,Meta 开发了用于优先处理来自选定进程组的潜在问题通信的工具,从而有效检测并及时解决落后者,确保将速度减慢到最低,保持整体训练效率。
还有一个有趣的观察是,环境因素对大规模训练性能的影响。对于 Llama 3 405B,Meta 注意到一天中会有一段时间出现 1-2%的吞吐量变化,这种波动是因为中午较高的温度影响了 GPU 的动态电压和频率调整,从而影响训练性能。但这不是什么大问题,GPU 的动态电压和频率缩放通常都会受到温度变化的影响。
结语
考虑到一个包含 16384 个 H100 GPU 的集群在 54 天内经历了 419 次意外故障,每 24 小时 7.76 次,我们不禁想到,xAI 配备了 100000 个 H100 GPU 的孟菲斯超级计算机集群(Memphis Supercluster)发生故障的频率是多少?
上周,埃隆·马斯克(Elon Musk)在社交平台 X 上吹嘘自己启动了“世界上最强大的人工智能训练集群”,他将在今年 12 月之前创建“世界上所有指标最强大的人工智能”。据悉,孟菲斯超级计算机集群已经开始进行训练,采用了液冷散热和单一的 RDMA 网络互连架构。
按 GPU 规模比例来看,xAI 的孟菲斯超级计算机集群可能会面临指数级更高的故障率,出现故障的组件数量或会增加六倍,这给其未来的 AI 训练带来了更大的挑战。
参考链接:
https://www.inspire2rise.com/meta-faces-frequent-gpu-failures-llama-3-training.html
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/




