
云原生场景下节点/容器内存问题频发,内存一扩再扩
在云原生时代,Kubernetes(K8s)虽已成为容器编排的标准,但其复杂资源管理场景却让运维团队饱受挑战。其中,节点和容器的 OOM(Out of Memory)及内存异常占用问题尤为常见,如:
内存持续高位占用:节点长期接近
memory pressure阈值,导致 Kubelet 频繁触发驱逐机制,Pod 被迫迁移,业务稳定性受损。更糟糕的是,高内存压力还会影响节点调度评分,导致新 Pod 无法正常调度。容器 OOM 频发:Pod 因超出 memory limits 而被 cgroup 终止,表现为
OOMKilled状态,导致业务频繁重启,难以定位真正原因。应用内存泄漏隐性增长:应用存在内存泄漏时,短期压测可能完全正常,但运行数天甚至数周后,内存占用逐步攀升直至触发 OOM。这类问题隐蔽性极强,往往在生产环境才暴露。
资源配额设置失衡:
requests/limits配置不合理是常见问题——配置过低导致频繁 OOM 驱逐,配置过高则造成资源浪费和调度效率下降。而"合理值"的判断高度依赖业务特征和历史数据。
问题排查困难
但是云原生内存问题排查起来又遇到重重阻碍,通常需要多方专业人员协助投入,耗时多天才能定位定位根因找到合适解决方案。
应运而生:ACK AI 助手与 ACK&SysOM MCP
面对上述痛点,业界一直在探索更智能的解决方案。阿里云容器服务团队推出的计算 AI 助手( 也称 ACK AI 助手)、ACK MCP 工具与阿里云基础软件团队推出 SysOM MCP 工具集正是为此而生;通过将 SysOM 专业系统诊断能力以 MCP 形式深度集成至 ACK AI 助手,从而一句话闭环云原生内存问题。
ACK AI 助手 + ACK MCP:懂云原生业务场景的「智能 SRE」
ACK AI 助手是构建在阿里云容器服务 ACK 之上的智能运维助手。
容器服务 AI 助手深度融合操作系统能力,打造覆盖容器全生命周期(Day0~Day2)的智能运维体验。基于“卓越架构”理念,助手在稳定性、成本、安全与性能等维度提供最佳实践指导。
其核心能力包括:
智能诊断——通过环境全感知、多轮反问补充上下文,并协同多个专家 Agent 会诊,结合观测数据与领域经验,实现从异常发现、根因定位到一键修复的闭环;
集群优化——自动完成成本、安全、架构及弹性配置等多维度分析,生成可执行优化方案并预测效果;
智能健康检查——对集群、节点、Workload、网络、存储等全方位进行动态异常检测,融合大模型与算法,超越传统阈值告警;
同时支持复杂场景下的全自动 AIOps 流程,未来还将实现应用创建与资源管理的自动化,真正让容器服务更智能、高效、自愈。

ACK AI 助手也同样提供开源项目 ack-mcp-server tool 集合 https://github.com/aliyun/alibabacloud-ack-mcp-server/,以提供用户在自己的 AI Agent 上构建阿里云容器服务 ACK、Kubernetes 领域的 SRE Agent。
以下一些核心 AIOps 场景 demo:
SysOM MCP:深度操作系统诊断的「专业医生」
SysOM MCP 项目内置超过 20 个操作系统控制台生产级节点/容器诊断工具:
内存分析:内存全景诊断、应用内存诊断、OOM 内存诊断;
IO 诊断:IO 一键诊断、IO 流量分析诊断;
网络排查:网络丢包诊断、网络抖动诊断;
调度诊断:系统负载诊断、调度抖动诊断;
磁盘诊断:磁盘分析诊断;
宕机诊断:宕机诊断(dmesg 分析)、宕机诊断(vmcore 深入分析)。
对于内存问题,SysOM 内存工具覆盖从内核内存到应用内存的全方位内存分析,涵盖 10+ 内存异常场景:
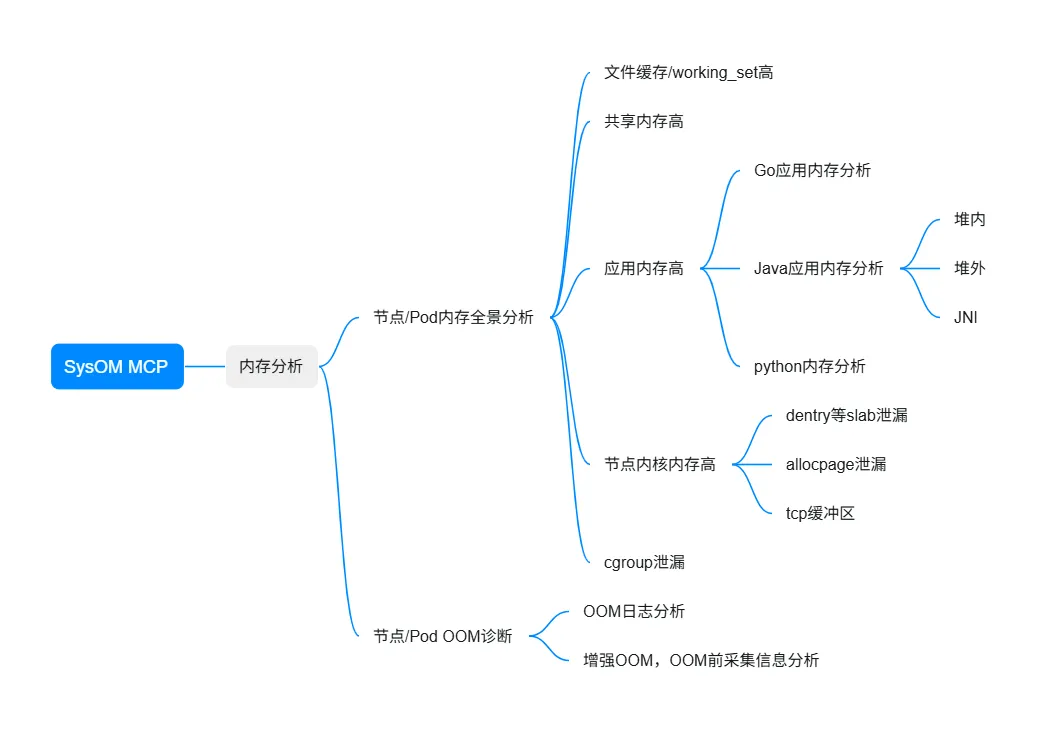
强强联合:云原生内存问题诊断闭环
为什么需要结合?
看起来我们已经有了两个强大的工具 -- 一个懂业务,一个懂内核。但在针对本文聚焦的云原生内存问题上,它们各自都存在一些局限性。如日常定位云原生内存相关问题时,通常也需要结合云原生和操作系统的相关专业知识来排查,这也正是我们需要将它们结合起来的原因。
数据维度全面打通
通过 ACK MCP 和 SysOM MCP 工具链,ACK AI 助手实现:
元数据自动关联:一次提问,AI 自动关联 Namespace → Deployment/Daemonset → Pod → Node → 实例规格,将 SysOM 的进程数据与 K8s 对象一一对应。SysOM 告诉你“是什么”(内核层面的内存异常根因结论),ACK MCP 告诉你“为什么”(K8s 配置上下文),两者结合才能形成完整的根因定位。
日志事件指标融合:OOM 发生时自动拉取容器日志、K8s Events、Prometheus 指标、审计日志等多维度数据。SysOM 提供“当前状态”(内存分布快照),Prometheus 提供“历史趋势”(何时开始异常),审计日志提供“变更事件”(是否与发布相关),三者交叉比对才能区分“流量突发”还是“版本缺陷”。
具体问题 CASE
CASE 1: kubectl top node 内存占用和节点监控不一致
客户在日常巡检中发现一个让人困惑的现象:kubectl top node 显示节点内存使用率仅 60%,但云监控控制台显示该节点内存占用已达 85%,两者差异超过 20%。这种数据不一致导致团队无法准确判断节点的真实负载状态,也无法确定是否需要扩容。
传统解决方案:找到相关同学,获取具体指标的计算方式,检查计算差异,获取差异部分具体内存占用,得出数据不一致根因。
通过 ACK AI 助手:


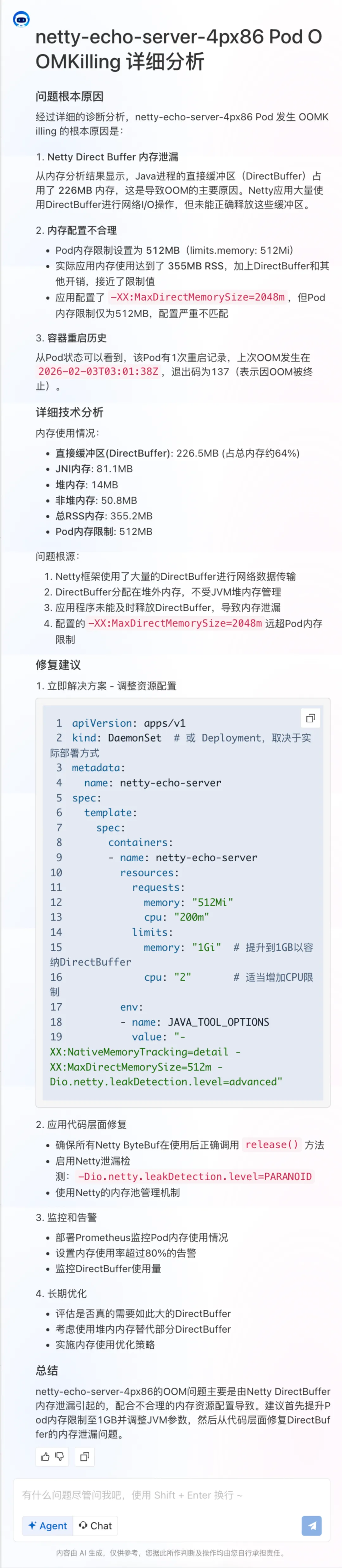
CASE 2: Java 应用 pod 频繁 OOMKilled
问题场景:一个 netty 服务在生产环境运行一段时间后,开始频繁出现 OOMKilled 重启。容器配置了 4Gi 内存 limit,JVM 堆内存设置为 `-Xmx3g`,理论上应该足够。但 Pod 仍然每隔几小时就被 OOM 终止一次,业务方抱怨服务不稳定。
传统解决方案:找到相关应用同学,通过各种各样 Java 问题排查工具,定位是哪部分内存使用不当导致;多方讨论如何改变设置或参数缓解问题。
通过 ACK AI 助手:

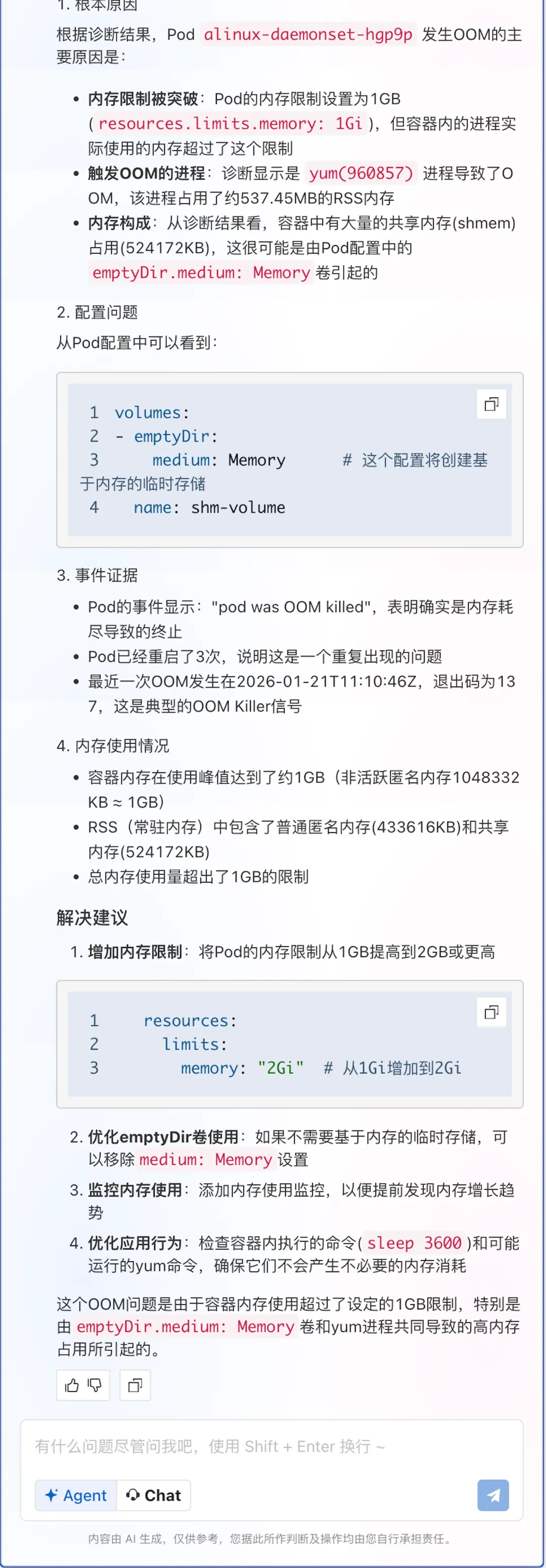
CASE 3: Emptydir 使用不当导致 Pod OOMKilled
问题场景:一个数据处理服务的 Pod 在运行过程中突然被 OOMKilled,但应用日志中没有任何内存异常的迹象,应用本身的内存占用也远低于 limits。用户百思不得其解:明明应用没用多少内存,为什么容器还是被 OOM 了?
传统解决方案:通过容器监控无法定位是哪部分内存占用导致 OOM,深入排查需要 SSH 登录节点、定位 cgroup 路径、手动解析memory.stat ,再与 Pod 配置交叉比对才能定位根因。整个过程涉及多系统切换、依赖内核经验,耗时长且门槛高。
通过 ACK AI 助手:
总结
通过 ACK AI 助手 + SysOM & ACK MCP 的组合,云原生内存问题从"凭经验"变为"有系统、有规则、有工具"的标准化闭环能力。
这不仅仅是两个工具的简单叠加,而是 "云原生视角"与"操作系统视角"的深度融合——让运维人员只需要一句话,就能获得从业务层到内核层的完整诊断报告和可执行建议。
链接:
ACK AI 助手功能说明文档:
ACK MCP 官方开源 tool 工具集:
🌟 GitHub 地址:
https://github.com/aliyun/alibabacloud-ack-mcp-server/blob/master/README.md
SysOM MCP
🌟 GitHub 地址:https://github.com/alibaba/sysom_mcp
操作系统控制台:
https://help.aliyun.com/zh/alinux/product-overview/what-is-the-operating-system-console
联系我们
若想使用更全面的 SysOM 功能,请登录阿里云操作系统控制台体验,地址:
https://alinux.console.aliyun.com/
您在使用操作系统控制台的过程中,有任何疑问和建议,可以扫描下方二维码或搜索群号:94405014449 加入钉钉群反馈,欢迎大家扫码加入交流。

操作系统控制台钉钉交流群




