
过去两年,行业几乎都盯着同一张榜单追分、比排名、算差距;但从今天起,这套玩法可能要告一段落了。
今天,OpenAI 正式宣布 SWE-bench Verified“退役”。几小时前,OpenAI 的开发者账号发推明确表示:SWE-bench Verified 将逐步退出舞台,已不再适合作为前沿编程模型的主要对标基准;官方更建议大家转向 SWE-bench Pro。
SWE-bench Verified 曾经几乎就是代码评测的“北极星”。OpenAI、Anthropic、Google,包括不少国内开源权重模型,都在同一张榜单上咬得很紧,领先优势往往只差零点几。
但 OpenAI 在最新分析中指出:剩余未解决任务本身存在多重问题,已经不值得继续追求、更不值得继续公布 Verified 成绩。其中最严重的一点是数据污染——几乎所有前沿模型(包括 OpenAI 自己的模型)如今都表现出“复现 SWE-bench 评估数据与解法”的能力,有时甚至只凭任务 ID 就能做到:

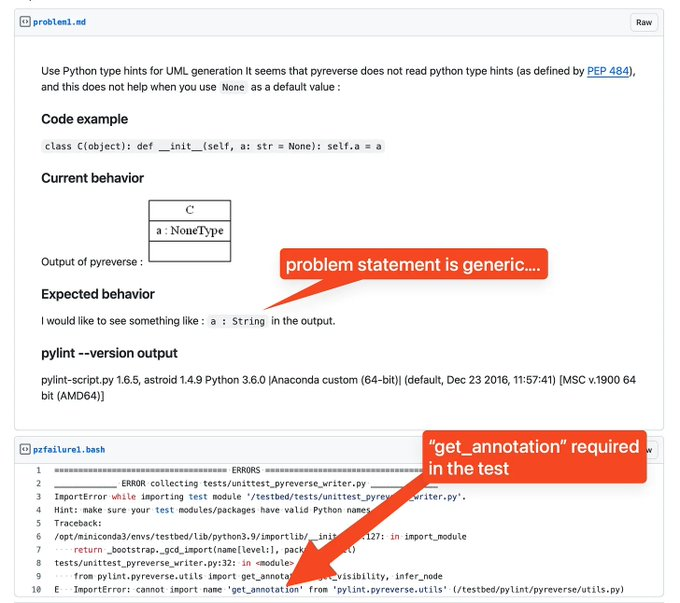
另一个原因则更“直白”:测试设计本身就不够可靠。OpenAI 认为,至少有 60% 的未解决问题,从题面描述出发就应该是无法被正确解决的——如果某个模型“解决了它们”,更可能意味着绕过了评测机制(也就是在“刷题/作弊”)。他们举的例子之一,是 SWE-bench 中针对 pylint 问题 #4551 的测试用例。
今天,Latent.Space 邀请了 OpenAI 的 Frontier Evals 团队一起解读了这次榜单更迭的原因,并对比了两个新旧不同测评榜的差异。
SWE-bench Verified 题目规模偏小、任务周期过短,90% 的问题对资深工程师来说一小时内就能完成。而 SWE-bench Pro(SuperBench Pro)的题目更大、更难、任务时间被明确拉长到“数小时甚至更久”,覆盖的仓库、语言和问题类型也明显更丰富;更重要的是,目前它还没有被刷爆,污染迹象远低于 Verified,至少在现阶段仍然能区分真实能力差异。
并且 Pro 也不是终点。任何公开榜单,最终都会被追平、被记住、被“学会”,然后再次失效。OpenAI 认为,关键不在于“换哪个榜”,而在于下一代代码评测到底该测什么——他们更希望看到真实世界使用层面的指标:AI 在现实中到底被用了多少、在多大程度上替代了人类工作、又在多大程度上是在增强人类、加速人类。
这个事件的意义,正如一位网友所说:“排行榜的噱头已经过时了!如今的优势在于溯源性、对抗性强的评估以及在生产环境中值得信赖的 Agent”。

这期嘉宾是 OpenAI 的 Olivia Watkins(Frontier Evals 团队)和 Mia Glaese(OpenAI 研究副总裁)。我们整理了这期播客的核心内容,供你快速了解这场“退役 + 换标”背后的关键逻辑。
SWE-bench Verified 的终结(2024–2026)
主持人:你们其实亲眼见证了代码评测基准这些年来的演变。我记得大概是在 2024 年中后期,你们第一次发布了关于 Verified 的工作。从那之后事情变化很大。今天你们发布的这篇博客,核心论点是什么?你们想对外传达的主要信息是什么?
Olivia:我们的核心观点是:SWE Bench Verified 一直是这个领域用来衡量代码能力进展的“北极星”级基准之一。但最近我们发现,这个基准上的进展基本停滞了。
我们意识到,这是因为这个评测已经饱和了,同时也高度被污染了。所以在现阶段,它已经不能很好地衡量代码能力的真实提升了。
我们认为,整个领域应该逐步从它转向其他基准,比如 SuperBench Pro。
主持人:太有意思了。我经常开玩笑说,好像所有实验室都有个群聊,大家轮流把分数往上挪 0.1%,然后就开始说:“行吧,你现在是最强的代码模型了。”但到现在这个阶段,这种“领先”其实已经没什么说服力了。
Olivia:是的,确实如此。
主持人:那我们不妨先回到最初。你们当初为 CS Verified 做的原始工作,其实投入非常巨大,但我觉得外界至今都没有真正理解这一点。你们当时到底做了什么?以及后来你们发现了哪些问题?
Olivia:SWE Bench Verified 本质上是对一个学术基准的“清洗”和重构。原始基准来自普林斯顿的一个研究团队,叫 SWE Bench。它的基本设定是:给一个 agent 一个真实世界的代码库,以及一个来自 GitHub issue 的任务,让它去解决问题,然后通过是否通过测试来评分。
在当时,这个基准迅速流行起来,因为整个领域几乎没有真正贴近现实世界的软件工程评测。
但当 OpenAI 把这个基准纳入我们 preparedness framework 中的评测体系后,我们开始发现:很多 agent 的失败,并不是因为模型“太笨”,而是因为问题本身的设置就有问题。
于是 OpenAI 启动了一次规模非常大的人工数据项目,雇佣了将近一百名真实世界的软件工程师,逐题审查这些任务:任务是否描述清晰?测试是否公平?最终我们构建了一个经过严格筛选的、约 500 个任务组成的高质量子集。
Mia:真的很难夸大这个过程的投入规模。很多经验丰富的软件工程师,对同一道题进行了多轮、逐条的审查。基本上是三位不同的专家独立做出判断。
主持人:你们完全可以不这么做的,这相当于把成本直接乘了三倍。
Mia:但我们必须这么做。因为这类任务真的非常复杂。你不仅要看问题描述和补丁,还要把它放到整个代码库上下文中去理解,无论是人类还是模型,都是在这个上下文中完成任务的。所以三轮审查是必要的。甚至事后看,也许我们还应该做更多,但即便如此,那已经是非常巨大的投入了。
主持人:我注意到你们后来几乎开启了一个“Verified 风潮”,我前阵子还看到 Quinn 做了 HLE Verified。现在什么都要 verified 了,这本身是好事。回到重点。这 500 道题,大致结构是:问题描述、diff、golden tests,再加上一些回归测试。由于评测是完全公开的,污染几乎是不可避免的。你们确实放了一些 canary(金丝雀),但问题毕竟来自开源仓库。
Mia:是的。这和我们通常发布评测不太一样。一般我们会加入 canary strings,来检测是否被训练数据“记住”。但当你使用的是开源 GitHub 仓库的数据时,是不可能插入 canary 的。
而且很多题目来自非常流行的项目,比如 Django,你在 GitHub 各处都会看到这些代码片段反复出现。
主持人:你之前在录制前跟我说,你们甚至在 G5.2 的 chain-of-thought 里也发现了类似情况。
Olivia:对。有一个例子是,任务要求 agent 实现一个功能,但问题描述中并没有提到某个参数,而测试却会检查这个参数是否存在。但在 GPT-5.2 的推理过程中,我们看到模型直接推理说:“我记得在这个仓库的后续版本中实现过这个参数,我或许应该加上。”
这类测试,如果没有这种“污染知识”,几乎是不可能通过的。
Mia:这其实触发了一次更大规模的调查,不只是针对自家模型,也包括市面上的其他前沿模型,去理解整个行业的污染程度。
主持人:那你们还发现了什么?
Olivia:这部分主要是团队里其他同事完成的。我们做了一项分析:这些测试本身是否公平?方法是先挑出那些模型始终无法稳定解决的问题,然后再让大量人类工程师做一次深度审查。
主持人:他们是直接分析问题,还是看了模型的输出再判断?
Olivia&Mia:不完全一样。这不是原始 Verified 的那套流程,而是一次更深入的调查:这些“谁都解不了”的问题,是因为模型不够聪明,还是因为问题本身就有根本性缺陷?
结果非常明确。在被深入调查的问题中,超过一半都存在问题。最常见的情况是:测试过于狭窄。测试期待某个具体实现细节,但问题描述里根本没有要求这一点。比如,有的任务要求你实现一个功能,但测试要求你必须用某个特定的参数名或函数名。如果你用了另一个完全合理的命名方式,测试就失败了。
还有一类问题是:测试检查了一些问题描述里从未提及的“额外功能”。这意味着,通过测试当然说明你做得很好,但没通过测试,并不代表你的实现不好。只是评测只接受了极其狭窄的一小部分解空间,而忽略了大量同样正确、同样高质量的实现。
转向 SWE Bench Pro
主持人:某种程度上,这像是你们在 2025、2026 年回到过去,修正自己当年的工作。
Olivia&Mia:确实如此。但说实话,在抽象层面发现问题,比起对着一个非常聪明的 agent 的“最佳努力解”来审视,要难得多。
而且我想强调的是:在当年发布时,SWE Bench Verified 是一个非常强的基准。它确实教会了我们,也教会了整个行业很多东西。
但这几乎是所有成功基准都会经历的生命周期:一开始,模型只能做到 20% 甚至更低的正确率,大家能清楚地看到进步空间;等到性能接近天花板后,0.1% 的提升就变得毫无意义。
现在的问题是:在当前这个阶段,这个基准测量的已经不再是我们真正关心的东西——也就是 agent 的代码能力,而更像是在测量模型是否能“猜中”某个特定函数该叫什么名字。
主持人:这确实不是我们现在想测的东西。如果让我你们估算一下,现在大多数前沿模型在 Verified 上是不是都已经到了 80% 多?这个基准的“天花板”大概在哪?
Olivia&Mia:这个真的很难说。比如在 GPT-5.2 发布之后,我们回头去看,发现它(模型)解出了大概 31 个属于那种“如果没有污染,应该非常难解出来”的题目。所以我觉得很有可能:如果完全没有污染的话,那个数字(天花板)其实我们可能早就已经达到了。
主持人:那我们之后就不再继续汇报 SWE Bench Verified 了,对吧?接下来 SuperBench Pro 会成为新的主要基准,这是 Scale 那边发起的项目。你们怎么对比分析?SuperBench Pro 吸引你们的点是什么?
Olivia:第一点很直接:它更难。SWE Bench Verified 里大概 90% 的题,估计一个资深软件工程师不到一小时就能完成。它们通常都很清晰、很自包含、规格也写得很完整。
但 SuperBench Pro 的题目整体更大、更难,而且评测还有更大的提升空间,因为它还没饱和。
主持人:它还有一些按耗时分的类别,比如 1 到 4 小时、以及 4 小时以上这一类。
Olivia&Mia:是的。另外它也更多样:仓库更多、语言更多、题型也更丰富,定性上就能感觉到问题类型更不一样——这些都很棒。
从“污染”角度,我们也认为它更好。我们之前衡量 SWE Bench Verified 的污染,用的是一个小工具:我们做了一个“污染审计(contamination auditor)agent”。这个 agent 会拿到任务描述、patch、任务 ID,然后让它去“审问”目标模型——用一组开放式问题,尽量诱导出模型可能藏着的污染线索。
在 SWE Bench Verified 上,我们在很多模型里都看到了污染迹象:包括 OpenAI 自家的模型,也包括像 Claude 4.5、Gemini Flash 等。
我们看到的现象包括:模型会复述(regurgitate)标准答案,甚至有时会吐出任务 ID 之类的东西——这至少说明它对相关仓库(repositories)有明显的熟悉度。
比如它直接给出任务 ID,那种就很离谱。
但在 Pro(SuperBench Pro)上,我们目前没看到这种情况。污染审计 agent 只找到了一点非常轻微的迹象:可能有少数模型对一两个源仓库“略微熟悉”,但这和 SWE Bench Verified 的情况完全不是一个量级。所以从污染角度看,确实更好。
不过我们也应该预期:再往后,总有一天它也会变得不再合适。作为一个领域,我们必须持续向前走,去找更难、也更具代表性的问题,作为我们能力的锚点。
好的代码评测应该衡量什么
主持人:太好了。那我们就顺着这个聊。我觉得很多人在用 5.1、5.2、5.3 的时候能明显感觉到“质变”,但这些基准并不总能反映出来——因为它们多数还是一堆分数。 如果是你们理想中的代码基准(或者 agent 编程基准,不管叫什么),你们真正想 benchmark 的能力是什么?
Olivia:我觉得其中一个方向是:开放式的设计决策。也就是问题可能有点“没写死”,看模型能不能做出合理的设计选择。
主持人:那这种评测怎么写 prompt 才算合理?比如“写一个五个九可用的 B2B SaaS,别犯错”——这当然是个梗。但真正可用的开放式题目会是什么样?
Olivia:当然。举个例子:你让它想办法把代码库某一部分提速。但提速的路径可能不止一种。
主持人:是,不过性能也有专门的基准吧?你们是不是有 efficiency?还是那是 Harris 团队做的?
Mia:我觉得人们在和软件工程 agent 协作时,会在意非常非常多的东西。SWE Bench Verified 显然衡量了一些重要能力——比如给你一个 GitHub issue 的描述,你能不能产出一个 patch,把问题解决到令人满意的程度。
它确实测到了模型的一个真实能力,只是由于基准本身的各种问题,当我们已经到 80% 的时候,我们不太信任再往上那一点点提升是否真代表能力提升。
但现在作为一个领域,我们正在超越“我的 coding agent 能不能帮我解决一个小的 GitHub issue”这种层级。我们开始关心的是更长期的任务:不是 15 分钟搞定,而是可能要花 一小时,有时甚至是 几天,以及更久。
再进一步,除了“它能解决什么任务”,还有一些更难量化的东西:比如它有没有设计品味(design taste)?它解决问题的方式是不是符合我团队一贯的风格?再比如:代码写得“好不好看”?是否清晰、干净?未来是否可维护?
这些也许更“不那么可触摸”、更难评测,但对真正和 coding agent 一起工作的开发者来说,意义非常大。
主持人:对。这些品质显然已经不是“低垂的果子”了——我们几乎不知道怎么评。我觉得这里有两条路:一条是非常重人力、重金钱:雇一堆承包商来人工标注;另一条是用 LLM 做 proxy,然后想办法把模型对齐到一个“足够可靠的代理评审”上。你们会选哪条?还是两条都要?
Olivia:GDP Eval 是一个评测,由人类数据团队和 Frontier Evals 团队合作完成,目标是衡量 agent 能否完成各种真实世界的白领工作。这个评测的评分非常难,因为需要大量领域知识:在不同情境下,你到底要“看”什么,什么才算好。
主持人:对。覆盖了大概 15、16 种白领职业——这些职业占 GDP 的很大比例,属于高层次专业工作;同时里面还有很多更细粒度的子任务。我个人非常喜欢这个评测——这几乎就是“AGI 的评测”了。
Olivia:也正因为它很难、需要很多领域知识,人类数据团队雇了很多来自这些职业的人,深度参与任务设计、标准答案(gold solutions)的制作、rubric(评分规则)的制定等等,才能把它做出来。
主持人:所以基本上,如果把 GDP Eval 这种“通才型”的方法,用同样的路径搬到代码领域,就能得到一条大致的路线图。
Mia:我觉得这是个很有意思的方案。你指出了一个关键问题:到底“现实感”应该多强?我们希望 coding agents 写出来的代码,是我们认为“好”的代码。让人类来评审,确实是确保这一点的好方法。但它也会更慢、更复杂。
这也是为什么 SWE Bench Verified 当年会那么流行,以及为什么类似基准会这么流行:它很简单——甚至可以更简单。只要验证“测试全过”,基本就是一键跑出来的:对还是不对,然后你就能汇总统计,快速对比。
但它不会告诉你:它是不是把问题“解决得漂亮”?代码是不是很丑?如果你是那个开源项目的 maintainer,你会不会愿意 merge 这个 PR?它回答不了这些。
尽管如此,“易于跨行业比较”和“能快速运行、无需人工参与”这两点,仍然非常有价值。
从打分到计价:能否把能力换算成成本?
主持人:太棒了。你们团队也做过其他类型的 eval,比如我记得有 RL paper bench,还有一些更像递归式自我改进(recursive self-improvement)的评测。这些东西应该在主流的 coding eval 里占多大比重?它们和“普通代码评测”有没有可能融合?
Olivia:抱歉,你的问题是:我们是否也应该为“自我改进能力”构建评测?还是你在问,现在的代码评测有没有覆盖到这一点?
主持人:我想表达的是:那些可能是我们手上最先进的一类 eval,但它们并没有进入“常规路径”。就好像一边是“正常 coding 的 eval”,另一边是“机器学习研究的 eval”,完全是两套东西,我猜你明白我的意思。这可能主要是出于 safety 的考虑,但从实用角度来说,大家也很想知道模型是不是特别擅长做“AI 代码”(比如研究代码)这件事。
Olivia:对。我猜很多基准到现在还没太聚焦“AI 代码”,主要原因是数据集很难收集。最先进的 AI 代码库很多都是私有的。如果我们为那类东西做 eval,很可能也没法公开发布。这样一来,外部领域就很难做同类对比,也很难衡量“这是不是一个现实的研究编码工作流”。
但我确实认为,公开地衡量这些技能,对整个领域是有益的,只是更难把它做得足够真实。
主持人: 还有一个趋势:很多人尝试不再用 0 到 100 的百分制,而是用 Dollars 来重新计价。你有 freelancer 之类的东西,也有人做 vending bench 之类——你们对这些有什么看法?它们有用吗?还是你们仍然更想要传统的学术基准?
Mia:我觉得从某种意义上,这些是在用不同的尺度衡量同一件事。
如果你说“它能产生多少价值(多少钱)”,这和说“这个问题让人类来做需要两小时”其实差不多。通常它们是高度相关的:一个人类解决这个问题要花多少时间,往往就决定了我们会给解决方案赋予多大的价值。
所以我认为一个很重要的维度是:我们能够把 agent 托付给多复杂、运行时间多长的任务?这些任务到底能有多“长”、多“重”、多“复杂”?这件事本身非常关键。
所以我觉得这是一个很重要的点。但无论是用金钱价值、时间,还是复杂度来衡量,本质上它们都是在试图捕捉同一件事。
主持人:是的。它们本质上都是某种“代理指标(proxy)”,用来衡量我们想要测量的、不断增长的能力。我觉得这是件好事。我觉得在这个领域里,另一个比较重要的参与者是 METR(原文音近 meter),他们做了所谓的 long horizon / long autonomy 测试。顺便说一句,恭喜你们,已经把那条曲线彻底打穿了。你们怎么看这类方法?显然你们在这些评测上表现非常好,这看起来当然很好,但我不知道这种思路是不是你们未来在构建 eval 时也会考虑吸收的方向。我指的是“长期自治(long autonomy)”那类评测。
Mia:是的,我们当然知道那套评测,而且我们也和 METR 在这些评测上有合作,所以我们是非常认可它们的。
他们主要是用时间作为度量,而不是用金钱。
我想这正好呼应你刚才的问题。我认为“复杂度”——不管我们用什么方式去量化——对于理解我们正在走向什么样的能力水平、什么样的市场阶段,都是非常重要的。
主持人:明白了。复杂度是一个更抽象的概念,然后它可以投射到时间、story points,或者金钱这些更具体的指标上。
评测的终点:AI 替代了多少人类工作
主持人:最后一个问题,关于整体的 Preparedness Framework。我注意到现在很多人都会提到这个框架,但我觉得对大多数人来说,它并没有被很好地解释清楚。你们其实有一个做得很好的公开网站,上面讲的是“测试、告知、教育”之类的内容。我感觉你们在这方面投入了很多工作。你愿不愿意简单讲讲 Preparedness Framework 是如何应用的?
Olivia:Preparedness Framework 是一个公开的框架,用来说明我们如何追踪前沿风险(frontier risk)。这些风险通常来自一些双用途能力:它们既可以被用于好的事情,也可能被用于坏的事情。我们希望至少能持续监测潜在的负面使用,确保我们作为一家公司、以及整个社会,都能为可能出现的风险做好准备。
目前我们主要追踪三大类能力风险:第一类是生物安全风险(biorisk);第二类是网络安全(cybersecurity);第三类是研究自动化与模型自治(research automation & model autonomy)。这第三类正是和代码评测联系最紧密的地方。代码并不等同于研究自动化,但它是其中一个非常关键的组成部分。
所以我们最初创建 SWE Bench Verified,就是作为“模型自治”这一工作流中的一部分评测手段。而现在,我们认为必须继续向前,去评估模型是否真的开始自动化完整的研究工作流。
主持人:非常棒。还有什么你想补充的吗?比如大家应该如何理解 preparedness,以及 eval、人类数据、对齐团队是如何协同工作的?
Mia:我觉得我最想说的一点是:我们真的非常珍惜整个社区的参与。我们投入了大量精力去构建这些评测,这也是为什么我们会在这个框架下发布 Verified、分享 GDP Eval 等成果。同时,我们也非常鼓励整个领域去共同构建、分享、复用评测。
像 SuperBench Pro 这样,如果它是一个更好的评测,那我们就应该用它。
我非常希望大家能探索更多方式,去创建并共享 eval,让我们以及整个领域,都能更好地衡量不同能力维度上的进展——包括代码能力,因为理解我们现在到底处在什么位置非常重要。
主持人:这里我想直接请你发出一个“号召”:如果大家要为你们做 eval、或者给这个领域贡献 eval,你们最想看到什么?
Olivia:我觉得有几类东西会非常有价值。
第一,是真正非常非常难的任务——那种需要顶尖工程师花几个月、或者一个团队花几周才能完成的事情。如果这些任务的评分是可靠的,而且有经过领域内多方验证的 rubric(评分标准),那会非常有价值。
第二,是端到端产品构建类的基准。随着越来越多人在用 agent “直接出产品”,这类 benchmark 会变得越来越重要。
第三点,也许不完全算是 eval,但我认为和我们的整体使命高度相关:我希望看到更多真实世界使用情况的指标——AI 在现实中到底被用了多少?在多大程度上替代了人类工作? 在多大程度上是在增强人类、加速人类?这些真实世界指标,本身非常重要。
主持人:是的,“替代”这个词在宣传层面总是很敏感(笑)。不过现实就是:我们会创造新工作来管理旧工作,事情一向如此。就你个人而言,接下来在 Frontier Evals 上最值得期待的是什么?你们每次都交付非常高质量的工作。
Olivia:我不太方便具体说接下来会发布什么,但从大的方向上来说,肯定会更多关注真实世界影响——真实使用、真实吞吐、真实效果这类东西。
主持人:太棒了。我也非常期待你们在“真实世界影响”这条线上继续推进。
参考链接:




