
作者 | 招商银行信息技术部 - 架构管理团队
技术方向 | AI 基础设施、大模型推理优化
大模型推理正在从单机走向分布式集群和分离式架构,但 Kubernetes 原生的工作负载原语(Deployment、StatefulSet)并不是为"多角色协作、拓扑敏感、快速和可靠升级、故障联动"的推理场景设计的。本文介绍招商银行基于 SGLang RBG 组件,在国产 AI 芯片上落地 DeepSeek-V4 Flash 大 EP 推理服务的实践,重点剖析动态端口分配、服务发现、多级故障自愈与原地升级四个核心机制的设计与实现。
问题:DeepSeek-V4 国产 AI 芯片大 EP 部署的挑战
当模型参数量达到数百 B 级别,单机已无法承载完整的推理计算。以 DeepSeek-V4 Flash 为例,它采用 MoE(Mixture of Experts)架构,专家参数分布在多张卡上通过 EP(Expert Parallelism)并行计算;同时,为了提升吞吐和降低延迟,业界通常将推理过程拆分为 Prefill(预填充)和 Decode(解码)两个阶段,分别由不同的实例组承担,再通过 Router 统一调度请求——这就是所谓的 PD 分离 + 大 EP 架构。
这个架构在算法和系统层面已经成熟,但在基于 Kubernetes 纳管异构算力卡时,其部署与运维面临的工程化挑战,在复杂度上远超传统的无状态微服务。以下,我们将这些痛点按层次进行系统性剖析。
多角色拓扑的配置复杂度
大 EP 部署本质上是一个 三级嵌套的拓扑结构:最外层是角色(Router、Prefill、Decode),中间层是每个角色的多个实例(如 2 个 Prefill 实例组),最内层是每个实例内的多个 Worker Pod(如一个 Prefill 实例跨 16 张 AI 芯片,由 1 个 Leader + 15 个 Worker 组成)。
传统 Kubernetes 的工作负载原语无法自然表达这种结构:Deployment 是无状态的,不支持 Pod 间的拓扑关系;StatefulSet 只管理单一角色的有序副本,无法表达跨角色的依赖。因此运维人员不得不手动维护三组独立的 YAML 配置,并在其中硬编码角色间的网络引用关系——Router 的启动命令里要列出所有 Prefill 和 Decode 的地址,Prefill 的配置里要写明数据传输对端 Decode 的地址。
以一个 2 Prefill + 2 Decode 的部署为例,仅 Router 的启动参数中就需要写入 32 个 --prefiller-hosts 和 32 个 --decoder-hosts 条目(每个实例 16 张卡各一个端点)。这些地址一旦写错或遗漏,轻则部分专家不可达导致推理精度下降,重则整个服务无法启动。
hostNetwork 下的端口管理
在大 EP 部署中,Prefill 和 Decode 之间的 KV Cache 传输对带宽和延迟极其敏感,通常需要使用 RDMA 实现高速数据通道。这要求 Pod 以 hostNetwork: true 模式运行,直接使用宿主机网络栈。
hostNetwork 模式带来两个层面的端口管理问题:
第一是 同节点端口冲突。每个推理 Pod 至少需要占用 3-4 个端口(HTTP API 端口、gRPC 通信端口、数据传输端口、指标暴露端口)。如果调度器将两个推理 Pod 放在同一节点上,硬编码的端口号必然冲突。传统做法是通过 nodeSelector 或反亲和性保证每个节点只跑一个推理 Pod,但这牺牲了资源灵活性和弹性伸缩能力。
第二是 跨角色的端口发现。即使端口不冲突,Router 也需要知道每个 Prefill/Decode Pod 实际监听的端口号。在端口硬编码的方案下这不是问题,但一旦引入动态端口分配(解决冲突后的必然选择),Router 如何获知每个下游节点的端口就成了新的挑战——传统的 Kubernetes Service 在 hostNetwork 模式下并不能很好地工作。
服务发现的时序依赖
即便不考虑端口问题,大 EP 部署中的服务发现本身也比普通微服务复杂得多。
首先是 启动顺序依赖。EP 并行要求同一实例内的所有 Worker 必须在通信组建立阶段(HCCL/NCCL init)同时就绪;Prefill 和 Decode 节点需要互相发现后才能建立 KV Cache 传输通道;Router 则需要等待所有下游节点就绪后才能正确路由。这些依赖关系不是简单的"先启动 A 再启动 B",而是多层嵌套的拓扑感知。
其次是 地址解析的竞态问题。若节点间的地址发现依赖启动脚本执行 DNS 查询(如 getent hosts),会面临明显的时序风险:Kubernetes 中 DNS 记录的刷新依赖目标 Pod 变为 Ready 状态。如果查询发生在目标 Pod 就绪之前,将导致解析失败或获取到陈旧(Stale)地址。在 Pod 动态扩缩容或漂移重启场景下,这种竞态条件极易引发节点的级联启动失败。
故障域的级联效应
大 EP 架构中的故障传播路径比单体服务复杂得多,呈现出 三级级联 的特征(如:NPU 场景下集合通信库为 HCCL,GPU 场景下对应 NCCL,下文统称"集合通信库"):
实例内级联。一个 EP 实例(如 Prefill-0)由多个 Worker Pod 组成,它们通过集合通信库(HCCL/NCCL)建立 communicator 协同计算。这类集合通信库本身 不具备容错能力——任何一个 Worker 故障都会导致 collective 操作阻塞或失败,整个通信组进入不可用状态,且原生不支持单 rank 的 “hot rejoin”。Kubernetes 原生的 Pod 级重启只会重启出问题的那个 Worker,但它重启后需要与其他 Worker 一起销毁旧 communicator 并重新建组——如果其他 Worker 不感知到这次中断并配合重置状态,通信组将无法恢复,重启的那个 Worker 也只能空转。
跨角色级联。Prefill 和 Decode 之间通过 Bootstrap server 注册会话、并基于 RDMA 建立 KV Cache 传输通道。需要强调的是,这里的对端关系 不是静态 1:1 配对 的——Router 按请求维度动态选择 Prefill/Decode 组合,真正"持有状态"的是 Bootstrap server 的会话注册表和 Transfer engine(如 Mooncake、NIXL)的 RDMA QP 缓存。当一个 Decode 实例故障重启后,即使它自身的推理服务恢复了:
Bootstrap server 上残留的旧 worker 注册记录、Transfer engine 上残留的 RDMA QP 握手缓存,不会随 Pod 重启而自动清理;
其他 Prefill 实例新发起的 KV 传输会因为会话 ID 不匹配或 QP 失效而失败,表现为"对端在线但传输始终建立不起来";
更上游的 Router 如果不感知 Decode 的状态变化,还会继续将新请求路由到这条已经失效的链路上。
这意味着 单独重启 Decode Pod 并不能真正恢复服务——必须让相关组件一起清理会话状态,这也是后文采用"实例级整体重建"而非"Pod 级重启"的根本原因。
重启风暴。在上述级联效应下,如果每个节点都配置了简单的健康检查 + 自动重启策略,理论上存在 A 节点故障 → B 节点通信超时 → B 的健康检查失败触发重启 → C 节点失去 B 的连接被判定不健康 → C 也被重启…… 这样的级联路径。实际生产中是否会真的"全集群崩"取决于健康检查阈值、退避策略、PDB 等配置;更常见的表现形式是 “局部反复重启 + 容量持续抖动”——服务没有完全死掉,但故障窗口内 SLA 已经塌了,且每一轮重启都会触发新一轮的会话状态残留与 Router 路由表错配,使得故障恢复时间被进一步拉长。
Kubernetes 原生的 restartPolicy: Always 只能重启单个容器,完全无法应对这种多层级、跨组件的故障传播。
异构 AI 芯片适配的复杂度高
在异构的国产算力集群上,大 EP 部署也面临较高的适配复杂度,主要源于两点:
部署芯片的不确定性:为追求极致的资源利用率,会采取“择优部署”策略,即根据模型在不同芯片上的性能与精度表现来动态选择部署目标。这就要求部署方案必须能够兼容并适配多种国产 AI 芯片。
资源变动引起的迁移:生产环境里的资源经常调整,模型需要能灵活地在不同的国产 AI 芯片之间迁移。这就要求部署方案不再依赖具体的硬件配置,抹平底层差异,让模型换到某一类卡都能正常跑。
升级的高昂代价
推理框架版本迭代快,特别是对于 DeepSeek V4 的支持依然在收敛过程中,因此不论是 SGLang 还是 vLLM 都在不断出新版本进行优化,但传统的 Kubernetes 滚动更新对大模型推理而言代价极高。
一次标准的 Pod 重建(RecreatePod)需要经历完整的生命周期:删除旧 Pod → 释放 AI 芯片资源 → 调度新 Pod → 等待 AI 芯片分配 → 拉取新镜像 → 加载模型权重到显存。对于 DeepSeek-V4 Flash 这样的模型,仅模型加载就需要数分钟。加上 AI 芯片资源的重新调度存在不确定性(如果节点资源被其他负载占用,新 Pod 可能长时间 Pending),单个实例的更新窗口难以预测。
更麻烦的是跨角色的 版本一致性 问题。Prefill 和 Decode 之间的数据传输协议可能因框架版本不同而不兼容。在滚动更新过程中,如果 Prefill 组已经全部升级到新版本,而 Decode 组还在用旧版本,就可能出现协议不匹配导致的传输失败。传统的 Deployment 滚动更新策略无法保证两个独立工作负载的更新进度同步。
方案选型:为什么是 RBG
SGLang RBG(RoleBasedGroup)是一个 Kubernetes API 扩展,专门为分布式推理工作负载设计。它的核心抽象是"角色组"——将 Router、Prefill、Decode 等角色定义为一个逻辑整体,由统一的控制面进行编排。
在确定方案前,我们做了两层评估:第一层是"工作负载编排 API",这类方案和 RBG 处在同一抽象层级,是真正意义上的候选;第二层是更上层的"推理服务平台"( 比如 AIBrix 等)。它们的关注点是"模型 + 路由 + 弹性 + 可观测"的端到端产品化,此类平台的代价是与某个推理引擎(如 vLLM)、某套模型管理范式或者硬件深度绑定,定位与 RBG 不同,不适合直接并列比较。
同层方案对比
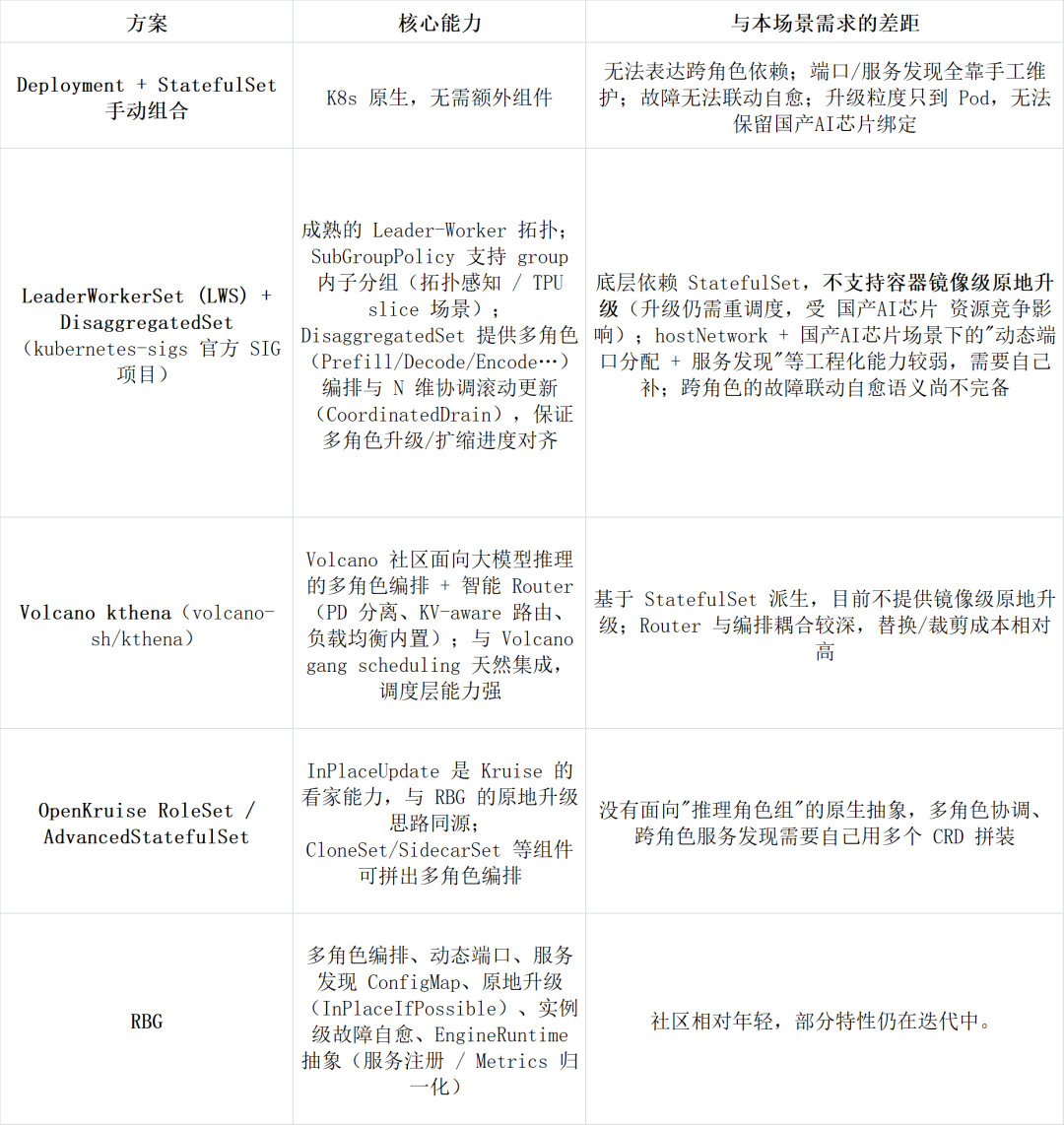
最终选择 RBG,我们主要看重了三点:
第一,面向“hostNetwork + 国产 AI 芯片 + PD 分离”场景的工程化封装最完整。动态端口分配、服务发现 ConfigMap、EngineRuntime(服务注册和 Metrics 归一化的 sidecar 抽象)这几件事,LWS/DisaggregatedSet 和 kthena 都没有原生覆盖,需要团队自行扩展,且实现难度较大;RBG 把这些痛点直接变成了软件能力。
第二,原地升级语义可用。在国产 AI 芯片资源紧张、模型加载耗时长的生产环境里,"保留调度位置和 AI 芯片的绑定、只换镜像"是非常实际的需求。LWS / Kthena 目前都还停留在类似 StatefulSet 的重建式滚动更新,RBG 与 OpenKruise 是少数能拿出可用方案的项目。
第三,不侵入推理框架,轻量无依赖。RBG 工作在 Kubernetes 控制面,不修改 SGLang/vLLM 任何代码,也不依赖额外的外部中间件,部署到已有 K8s 集群的成本几乎为零。
生产实践
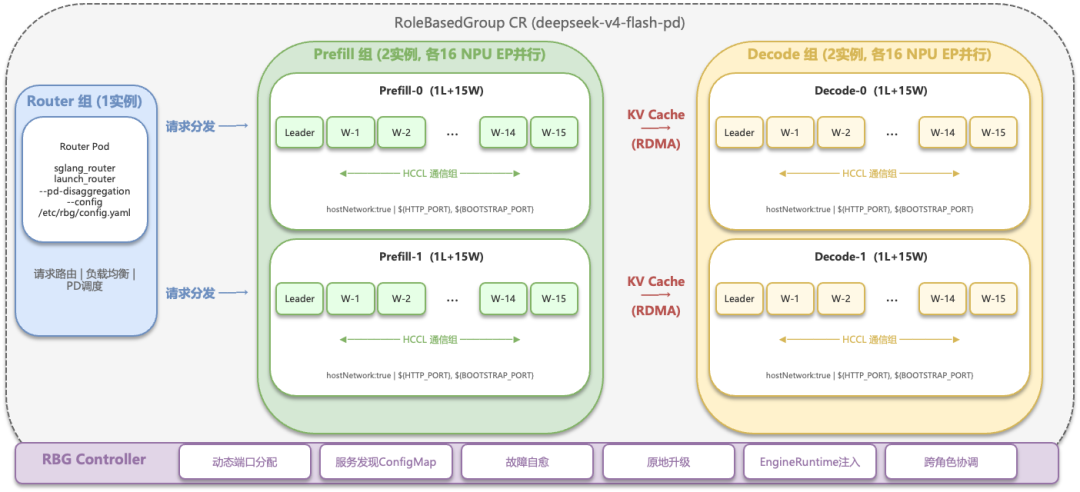
本章节以在 NPU 生产集群中自动化部署 DeepSeek-V4 Flash 的大 EP 推理服务为例,详细阐述如何基于 RBG 组件落地国产 AI 芯片的云原生推理方案。整体拓扑架构如下:
Router 组:1 个实例,负责请求路由和负载均衡
Prefill 组:2 个实例,每个实例跨 16 张 NPU 做 EP 并行
Decode 组:2 个实例,每个实例同样跨 16 张 NPU
三个角色通过一个 RoleBasedGroup CR 统一定义和管理。Controller 自动完成端口分配、服务发现 ConfigMap 生成、以及故障时的自愈重建。
以下为整体部署架构:
部署配置示例(以 SGLang 为例,可支持 vLLM)
apiVersion: workloads.x-k8s.io/v1alpha2kind: RoleBasedGroupmetadata: name: deepseek-v4-flash-pdspec: roles: - name: router replicas: 1 standalonePattern: template: spec: containers: - name: router image: registry.xxx/sglang:0.5.9 command: ["tini", "--"] args: - | python3 -m sglang_router.launch_router \ --host 0.0.0.0 --port ${HTTP_PORT} \ --pd-disaggregation \ --config /etc/rbg/config.yaml - name: prefill replicas: 2 engineRuntimes: - profileName: "ascend-npu-runtime" rolloutStrategy: type: RollingUpdate rollingUpdate: type: InPlaceIfPossible maxUnavailable: 1 inPlaceUpdateStrategy: gracePeriodSeconds: 30 standalonePattern: template: metadata: annotations: rolebasedgroup.workloads.x-k8s.io/port-allocator: | { "allocations": [ {"name": "http", "env": "HTTP_PORT", "scope": "PodScoped"}, {"name": "bootstrap", "env": "BOOTSTRAP_PORT", "scope": "PodScoped"} ] } spec: hostNetwork: true containers: - name: sglang-prefill image: registry.xxx/sglang:0.5.9 command: ["tini", "--"] args: - | python3 -m sglang.launch_server \ --model-path /model/DeepSeek-V4-Flash \ --disaggregation-mode prefill \ --disaggregation-transfer-backend ascend \ --port ${HTTP_PORT} \ --disaggregation-bootstrap-port ${BOOTSTRAP_PORT} \ --host 0.0.0.0 - name: decode replicas: 2 engineRuntimes: - profileName: "ascend-npu-runtime" rolloutStrategy: type: RollingUpdate rollingUpdate: type: InPlaceIfPossible maxUnavailable: 1 inPlaceUpdateStrategy: gracePeriodSeconds: 30 standalonePattern: template: metadata: annotations: rolebasedgroup.workloads.x-k8s.io/port-allocator: | { "allocations": [ {"name": "http", "env": "HTTP_PORT", "scope": "PodScoped"} ] } spec: hostNetwork: true containers: - name: sglang-decode image: registry.xxx/sglang:0.5.9 command: ["tini", "--"] args: - | python3 -m sglang.launch_server \ --model-path /model/DeepSeek-V4-Flash \ --disaggregation-mode decode \ --disaggregation-transfer-backend ascend \ --port ${HTTP_PORT} \ --host 0.0.0.0实践初期,我们通过 getent hosts 解析 IP,并硬编码端口列表的方式去获取 IP 和端口。为了简化运维并支持动态扩缩容,后来我们引入动态端口分配和服务发现机制(见高级特性章节),将所有的地址发现和端口管理都交给 Controller 处理。运维人员只需要关注业务语义层面的配置,例如"几个 Prefill、几个 Decode、用什么镜像"等,极大地降低了运维工作量。
生产中的注意事项
在 NPU 环境下落地这套方案,有几个实际碰到的问题值得分享:
第一,RDMA 网络要求。跨机的 Prefill-Decode 数据传输依赖 RDMA 网卡。我们通过 hostNetwork: true + 端口动态分配解决了端口冲突问题,但需要确保 RDMA 设备正确挂载到容器中(通过 EngineRuntimeProfile 中的 device plugin 配置)。
第二,健康检查配置。我们为每个推理 Pod 配置了 readinessProbe 和 livenessProbe。readinessProbe 用于判断模型是否加载完成(模型加载可能需要数分钟),livenessProbe 用于检测推理服务是否卡死。RBG 的自愈机制依赖这些 Probe 来正确判断 Pod 状态。
第三,PID 1 与信号传播。生产中启动命令若采用 sh -c "python3 ..." 形式,此时容器内 PID 1 是 shell,推理进程是其子进程。POSIX shell 默认不会主动向子进程转发 SIGTERM,导致 gracePeriodSeconds(原地升级中用于优雅停流的关键参数)期间推理进程实际上收不到优雅退出信号——宽限期一过,kubelet 直接 SIGKILL,长 Prefill 请求被一刀斩断,原地升级承诺的"优雅停流"形同虚设;与此同时 fork 出的 HCCL/tokenizer 等子孙进程容易成为孤儿,可能仍持有 NPU 设备或 RDMA 端口,导致下一次重建出现 device busy 而启动失败,反过来触发 RBG 的实例级重建,放大故障域。因此建议引入 tini 作为 PID 1,或在启动脚本中以 exec 替换 shell 进程,确保信号正确转发并完成孤儿进程回收——这是原地升级机制能否真正成立的前提。
高级特性深入剖析
动态端口分配
如前所述,hostNetwork 模式下的端口冲突和端口发现是大 EP 部署的基础性难题。传统做法要么人工规划端口分配表(运维成本高且容易出错),要么通过 nodeSelector 保证节点互斥(牺牲资源灵活性,无法弹性伸缩)。RBG 在 Controller 层提供了一套系统化的解决方案。
RBG 在 Controller 层引入了一个全局端口分配器(Port Allocator),采用 随机分配 + 范围隔离 的策略:
# Pod 模板中声明需要动态分配的端口metadata: annotations: rolebasedgroup.workloads.x-k8s.io/port-allocator: | { "allocations": [ {"name": "http", "env": "HTTP_PORT", "scope": "PodScoped"}, {"name": "grpc", "env": "GRPC_PORT", "scope": "PodScoped"}, {"name": "transfer", "env": "TRANSFER_PORT", "scope": "PodScoped"} ], "references": [ {"env": "PREFILL_GRPC_PORT", "from": "prefill.leader.grpc"} ] }分配流程 如下:
Controller 在创建 RoleInstanceSet 时,从配置的端口范围 [startPort, startPort + portRange) 中随机选取端口,写入 RoleInstanceSet 的 annotation(RoleScoped 端口)。
创建 RoleInstance 时,为每个 Pod 独立分配 PodScoped 端口,同样写入 RoleInstance annotation。
Pod 实际创建时,Controller 从 annotation 中读取端口值,以 环境变量 的形式注入到容器中。
两级作用域设计 的考虑是:有些端口(如用于角色间通信的 bootstrap 端口)在整个角色内应保持一致,用 RoleScoped;有些端口(如 Pod 自身的 HTTP 服务端口)必须每个 Pod 不同,用 PodScoped。
跨 Pod 端口引用 解决了另一个痛点——一个角色如何知道另一个角色分配到了哪个端口?通过 references 字段,Controller 会在创建 Pod 时自动解析 “prefill.leader.grpc” 这样的引用,找到目标 Pod 的实际端口值并注入为环境变量。
在最初的部署方式中,端口是硬编码在启动命令里的:
# 原始方式:端口硬编码,多副本部署必须手动改python3 -m sglang.launch_server --port 8000 \ --disaggregation-bootstrap-port 34000使用端口分配器后,启动命令变为:
# 优化后:端口从环境变量读取,Controller 自动分配python3 -m sglang.launch_server --port ${HTTP_PORT} \ --disaggregation-bootstrap-port ${BOOTSTRAP_PORT}这个改变看似简单,但它意味着我们可以安全地在同一节点上调度多个推理副本,支持超分和弹性伸缩,而不再受限于"一个节点只能跑一个推理实例"的约束。
服务发现与 EngineRuntime
前面分析了大 EP 部署中服务发现的两个核心困难:启动顺序依赖和地址解析的时序竞态。在原始方案中,节点间地址通过启动脚本中的 DNS 查询获取:
# 原始方式:启动时通过 DNS 解析获取其他节点 IPexport prefill_0_ip=$(getent hosts prefill-0.svc | awk '{print $1}')export decode_0_ip=$(getent hosts decode-0.svc | awk '{print $1}')这种方式的问题在于:DNS 解析发生在启动时刻,如果目标 Pod 尚未就绪,解析会失败或拿到旧地址;同时端口信息完全硬编码,一旦引入动态端口分配就完全失效。RBG 通过三层递进的服务发现机制系统性地解决了这些问题。
三层服务发现机制
第一层:环境变量注入。Controller 为每个 Pod 自动注入一组标准化环境变量,包括 RBG_GROUP_NAME、RBG_ROLE_NAME、RBG_ROLE_INDEX 等。对于 LeaderWorker 模式,还会注入 Leader 地址 RBG_LWP_LEADER_ADDRESS 和 Worker 索引。
第二层:拓扑 ConfigMap。Controller 维护一个全局的服务发现 ConfigMap,包含整个角色组的完整拓扑信息,并以 Volume 形式挂载到每个 Pod 的 /etc/rbg/config.yaml:
# 由 Controller 自动生成并实时更新group: name: deepseek-v4-inference roles: [router, prefill, decode]roles: prefill: size: 2 instances: - address: deepseek-v4-prefill-0.prefill-svc.ns ports: http: 18392 # 动态分配的端口 grpc: 29401 bootstrap: 34127 - address: deepseek-v4-prefill-1.prefill-svc.ns ports: http: 18501 grpc: 29455 bootstrap: 34289 decode: size: 4 instances: - address: deepseek-v4-decode-0.decode-svc.ns ports: http: 19003 grpc: 30112 # ...推理引擎只需读取这个文件就能获得完整的集群拓扑,不再依赖启动时的 DNS 解析,也天然适配动态端口。
第三层:组件级发现。对于同一个 RoleInstance 内的多组件场景(比如一个推理实例包含 leader 和多个 worker),RBG 支持通过 annotation 声明组件间的地址和端口引用:
rolebasedgroup.workloads.x-k8s.io/component-discovery: | { "addressRefs": [{"env": "LEADER_ADDR", "component": "leader", "index": 0}], "portRefs": [{"env": "LEADER_PORT", "component": "leader", "portName": "grpc", "index": 0}] }Controller 会在 Pod 创建时解析这些引用,将实际地址和端口值注入为环境变量。
EngineRuntime 配置解耦:ClusterEngineRuntimeProfile 的作用
在实际部署中,不同的硬件平台需要不同的运行时配置——驱动初始化脚本、设备挂载方式、监控 sidecar 等。RBG 通过 ClusterEngineRuntimeProfile 这个集群级 CRD 实现了运行时配置的复用:
apiVersion: workloads.x-k8s.io/v1alpha2kind: ClusterEngineRuntimeProfilemetadata: name: ascend-npu-runtimespec: updateStrategy: RollingUpdate initContainers: - name: npu-driver-init image: registry.xxx/ascend-driver-init:v1.2 # NPU 驱动初始化逻辑 containers: - name: npu-metrics-exporter image: registry.xxx/npu-exporter:v0.9 # NPU 指标采集 volumes: - name: npu-driver hostPath: path: /usr/local/Ascend角色定义中只需通过 engineRuntimes 字段引用 Profile 名称,Controller 会自动完成 sidecar 和 init-container 的注入。当 Profile 更新时(比如升级驱动版本),Controller 可以根据配置的策略(NoUpdate 或 RollingUpdate)决定是否触发 Pod 滚动更新。
这种设计使得硬件适配层与推理服务定义解耦——同一份推理服务 YAML 可以通过切换不同的 EngineRuntimeProfile 运行在不同的硬件上,而不需要修改业务配置。
EngineRuntime 的能力扩展:统一服务注册与 Metrics 归一化
上面介绍了 ClusterEngineRuntimeProfile 在硬件驱动注入方面的作用,但 EngineRuntime 的能力远不止于此。在分布式推理场景中,不同的推理引擎(SGLang、vLLM 等)在服务注册和指标暴露上各有一套实现,这给多引擎混合部署带来了显著的集成复杂度。RBG 通过 EngineRuntime 机制提供了两个关键的可扩展抽象层:统一服务注册和 Metrics 归一化。
统一服务注册
在前面的服务发现机制中,介绍了 RBG Controller 为每个 Pod 注入环境变量(RBG_GROUP_NAME、RBG_ROLE_NAME、RBG_ROLE_INDEX 等)并挂载服务发现 ConfigMap(/etc/rbg/config.yaml)的机制。这些拓扑信息为服务注册提供了基础,但"如何将自己注册到 Router"这个动作,则由 EngineRuntime 注入的服务注册 Sidecar 来完成。
具体工作流程是:服务注册 Sidecar 启动后,读取 Controller 注入的环境变量和 ConfigMap,获取当前 Pod 的角色信息、实例索引和 Router 地址,然后主动调用 Router 提供的 Worker 注册接口,将自己注册为可用的推理节点。这种主动注册模式相比被动发现有几个显著优势:
第一,服务有效性保障更强。Worker 只有在真正就绪(模型加载完成、推理服务可响应)之后才会发起注册,Router 收到注册请求时即可确认该节点可以接收流量。不像被动发现模式下,DNS 或 Endpoints 更新可能先于服务实际就绪,导致 Router 将请求路由到未准备好的节点。
第二,不依赖任何 Kubernetes 资源或外部中间件。整个注册过程是 Worker 与 Router 之间的直接通信,不需要 Consul、ZooKeeper、etcd 等服务注册中心,也不依赖 Kubernetes Service 的 Endpoints 更新机制。这极大简化了部署架构,减少了故障点。
第三,引擎无关的可扩展性。不同的推理引擎的注册协议和接口各不相同——SGLang 有自己的 bootstrap 注册流程,vLLM 通过 gRPC 服务发现。通过 EngineRuntime,用户可以为每种引擎编写对应的注册 Sidecar 实现,封装为独立的 ClusterEngineRuntimeProfile。RBG 层面只关心"角色组"的编排语义,而"如何注册到 Router"的具体实现则完全委托给 EngineRuntime Profile——切换推理引擎时,只需替换 Profile 即可,无需修改 RoleBasedGroup 配置。
Metrics 归一化
另一个痛点是推理引擎的指标暴露不统一。SGLang、vLLM 等引擎在底层暴露的指标语义是一致的——都会报告吞吐量(tokens/s)、队列深度、请求延迟、KV Cache 使用率、AI 芯片利用率等核心指标——但它们的 Prometheus Metric 命名却各不相同。例如同样是"当前排队请求数",SGLang 叫 sglang_num_queue_reqs,vLLM 叫 vllm:num_requests_waiting,Dynamo 叫 dynamo_pending_requests。
这种命名差异带来的后果是:Prometheus 的告警规则、Grafana Dashboard、以及基于指标的 HPA/Autoscaler 策略,都需要针对每种引擎单独配置一套。当生产环境中同时运行多种引擎(或频繁切换引擎版本)时,运维配置的复杂度会线性增长。
因此通过使用 EngineRuntime 注入一个 Metrics 归一化 Sidecar 来解决这个问题。该 Sidecar 的职责是:从推理引擎的原生 Metrics 端点采集指标,按照统一的命名规范进行转换,然后通过标准的 Prometheus 端口对外暴露。对上层的监控、告警和弹性伸缩系统而言,无论底层运行的是哪种推理引擎,看到的都是同一套指标名称和语义。
这种设计同样具备可扩展性。当需要支持一个新的推理引擎时,只需在 Metrics Sidecar 中增加该引擎的指标映射规则,封装为对应的 ClusterEngineRuntimeProfile,上层的 Prometheus 配置、告警规则和 Autoscaler 策略完全不需要调整。
以下示例展示了一个典型的 EngineRuntime Profile,同时包含服务注册和 Metrics 归一化两种能力:
apiVersion: workloads.x-k8s.io/v1alpha2kind: ClusterEngineRuntimeProfilemetadata: name: sglang-engine-runtimespec: updateStrategy: RollingUpdate containers: # 服务注册 Sidecar:主动向 Router 注册当前 Worker - name: service-registrar image: registry.xxx/rbg-service-registrar:v1.0 env: - name: ENGINE_TYPE value: "sglang" # RBG Controller 自动注入 RBG_GROUP_NAME, RBG_ROLE_NAME, # RBG_ROLE_INDEX 等环境变量,并挂载 /etc/rbg/config.yaml # Sidecar 读取这些信息后调用 Router 的注册接口 # Metrics 归一化 Sidecar:采集引擎原生指标并转换为统一格式 - name: metrics-normalizer image: registry.xxx/rbg-metrics-normalizer:v1.0 env: - name: ENGINE_TYPE value: "sglang" - name: SOURCE_METRICS_PORT value: "30000" # SGLang 原生 metrics 端口 ports: - containerPort: 9090 name: metrics # 统一的 metrics 暴露端口当需要切换到 vLLM 时,只需创建一个新的 Profile(如 vllm-engine-runtime),将 ENGINE_TYPE 设为 vllm,服务注册 Sidecar 和 Metrics Sidecar 内部会根据引擎类型选择对应的注册协议和指标映射规则。角色定义中只需替换 engineRuntimes 引用的 profileName:
roles: - name: prefill engineRuntimes: - profileName: sglang-engine-runtime # 换引擎时只改这里 standalonePattern: template: spec: containers: - name: sglang-prefill image: registry.xxx/sglang:0.5.9这种架构带来了几个实际价值:
推理引擎可替换性——从 SGLang 切换到 vLLM 时,上层的监控、告警、弹性伸缩策略完全不受影响,因为它们对接的始终是统一的指标接口。
服务注册零依赖——不引入任何外部中间件,Worker 与 Router 直接通信完成注册,架构简洁、故障点少。
平台与业务分离——平台团队维护 Profile(服务注册和 Metrics 归一化的实现),业务团队只需关注推理服务本身的配置。
多级故障自愈
前面分析了大 EP 架构中故障域的三级级联特征:实例内的通信组断裂、跨角色的连接状态失效、以及全局的重启风暴。Kubernetes 原生的 restartPolicy: Always 只能重启单个容器,完全无法应对这种多层级的故障传播。RBG 针对性地设计了实例级重启策略和防级联保护。
下图对比了无 RBG 保护时的故障级联传播与 RBG 自愈机制的处理流程:
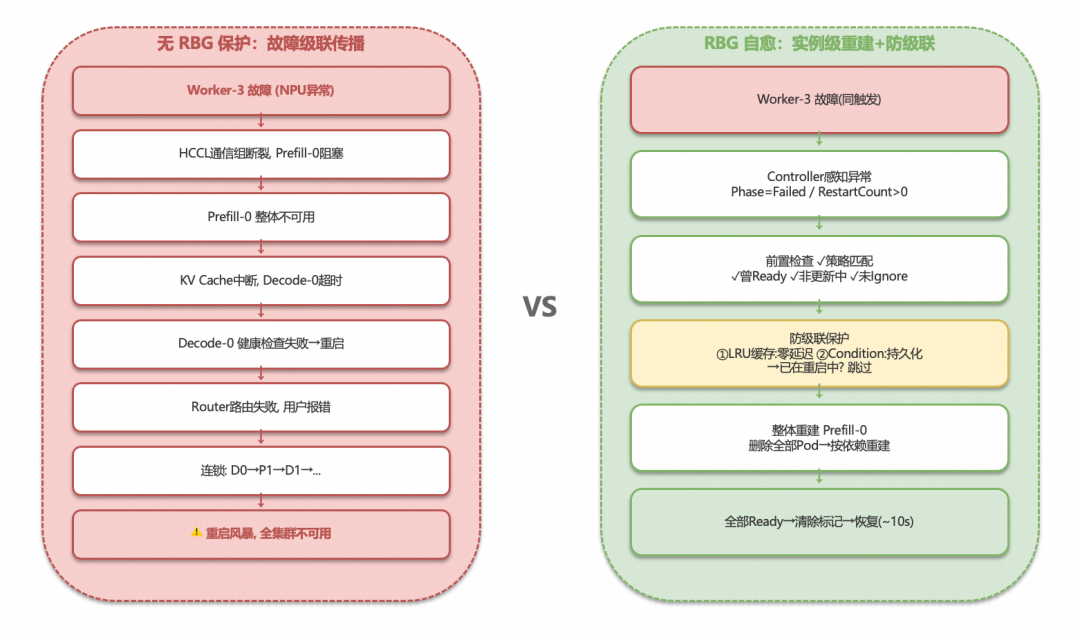
自愈模型
RBG 在 RoleInstance(角色实例)级别实现了重启策略,默认策略是 RecreateRoleInstanceOnPodRestart——当实例中任何一个 Pod 故障或容器重启时,整个实例的所有 Pod 会被一起重建。
具体的自愈流程:
┌───────────────────────────────────────────────────────┐│ Controller 感知到 Pod 异常 ││ (Pod Phase=Failed 或 Container RestartCount > 0) │└───────────────────────┬───────────────────────────────┘ │ ▼┌───────────────────────────────────────────────────────┐│ 前置检查 ││ 1. 重启策略 == RecreateRoleInstanceOnPodRestart? ││ 2. 实例之前是否处于 Ready 状态?(排除首次启动失败) ││ 3. 是否正在进行滚动更新?(避免与升级操作冲突) ││ 4. Pod 是否标记了 restart-trigger-policy: Ignore? │└───────────────────────┬───────────────────────────────┘ │ 全部满足 ▼┌───────────────────────────────────────────────────────┐│ 防级联保护检查 ││ - 检查内存缓存:该实例是否已在重启中? ││ - 检查 API Server:Restarting Condition 是否为 True? ││ → 如果已在重启中,跳过,等待当前重启完成 │└───────────────────────┬───────────────────────────────┘ │ 未在重启中 ▼┌───────────────────────────────────────────────────────┐│ 执行重建 ││ 1. 写入内存缓存 + 设置 Restarting Condition ││ 2. 删除实例中所有 Pod(包括已 Failed 的) ││ 3. 下一轮 Reconcile 中创建全新 Pod ││ 4. 新 Pod 全部 Ready 后清除 Restarting 标记 │└───────────────────────────────────────────────────────┘防级联保护 是这个机制中最关键的设计。在分布式推理集群中,一个节点故障很容易引发连锁反应——A 节点故障导致 B 节点通信超时,B 节点的健康检查失败触发重启,B 节点重启又导致 C 节点异常……如果不加控制,整个集群可能在短时间内陷入重启风暴。
RBG 通过双层守卫防止这种情况:内存中的 LRU 缓存提供零延迟的判断(避免 informer 缓存延迟导致的重复触发),API Server 上的持久化 Condition 则确保 Controller 自身重启后也不会重复执行。只有当实例完全恢复到 Ready 状态后,守卫才会被清除。
组件依赖感知
对于多组件的 RoleInstance(比如 Leader-Worker 模式),重建时还需要尊重组件间的启动依赖:
重建(Scale-out)阶段:按依赖顺序逐步创建组件,Leader 就绪后才创建 Worker。
销毁(Scale-in)阶段:按依赖的逆序删除,先停 Worker 再停 Leader。
环检测:如果依赖关系中存在环(通过 DFS 三色算法检测),回退到并行模式避免死锁。
跨角色协调
单个角色的自愈解决了实例级别的问题,但跨角色的协调同样重要。RBG 通过 CoordinatedPolicy CRD 来管理跨角色的一致性:
apiVersion: workloads.x-k8s.io/v1alpha2kind: CoordinatedPolicyspec: policies: - name: pd-coordination roles: [prefill, decode] strategy: rollingUpdate: maxSkew: "1%" # Prefill 和 Decode 的更新进度差不超过 1% scaling: maxSkew: "10%" progression: OrderReady # 当前批次全部 Ready 后才继续下一批这确保了在滚动更新或扩缩容时,Prefill 和 Decode 保持步调一致,不会出现"Prefill 已经全部更新到新版本,但 Decode 还在用旧版本"导致的协议不兼容问题。
原地升级
为什么推理服务需要原地升级
在传统的 Kubernetes 滚动更新中,更新一个 Pod 意味着:删除旧 Pod → 释放 AI 芯片资源 → 重新调度新 Pod → 等待新 Pod 获得 AI 芯片 → 拉取新镜像 → 重新加载模型 → 服务就绪。对于大模型推理场景,这个过程的代价远高于普通的 Web 服务:
首先是 模型加载时间长。DeepSeek-V4 Flash 的模型权重超过数百 GB,从存储加载到 AI 芯片显存需要数分钟。在这段时间内,该推理实例完全不可用。
其次是 AI 芯片资源调度不确定。高性能计算资源是稀缺资源,删除旧 Pod 后新 Pod 不一定能立即被调度到合适的节点——如果节点上的 AI 芯片 正好被其他工作负载占用,新 Pod 可能长时间处于 Pending 状态。
最后是 网络身份变化。在使用 hostNetwork 的场景下,Pod 重建意味着 IP 可能改变,所有与之关联的服务发现配置都需要更新,其他角色节点需要感知并重建连接。
理想的升级方式是:只替换容器镜像,保持 Pod 的调度位置、IP 地址、挂载卷不变——这正是 RBG 原地升级的核心思路。
下图对比了两种升级方式的时间线差异:
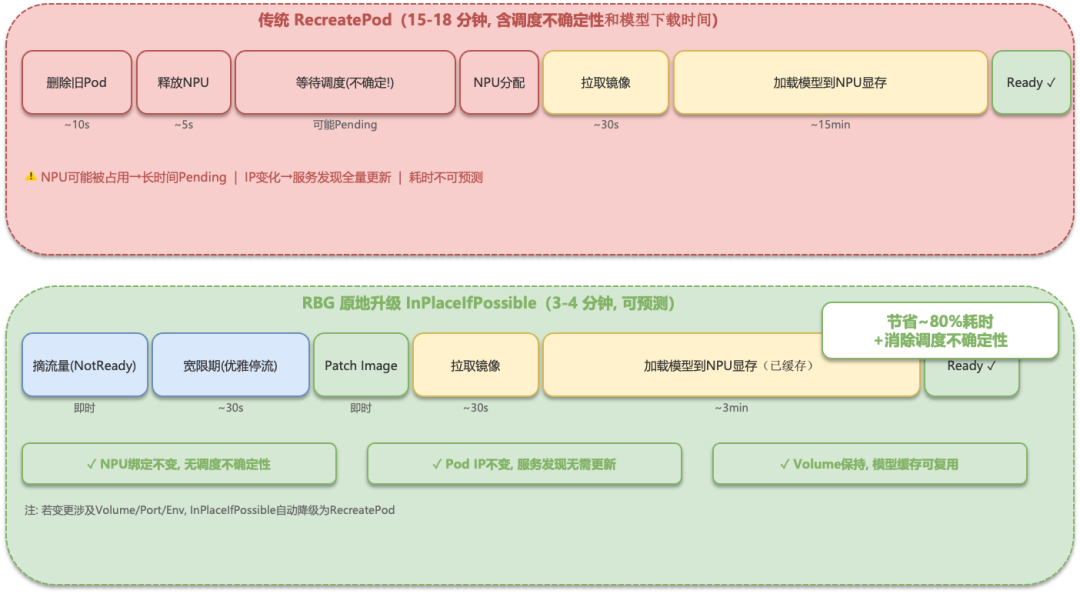
三种更新策略
RBG 在每个角色的 rolloutStrategy 中提供了三种更新策略:
spec: roles: - name: prefill rolloutStrategy: type: RollingUpdate rollingUpdate: type: InPlaceIfPossible # 更新策略类型 maxUnavailable: 1 # 同时更新的最大实例数 inPlaceUpdateStrategy: gracePeriodSeconds: 30 # 流量排空宽限期RecreatePod:传统方式,删除旧 Pod 后创建新 Pod。适用于需要变更挂载卷、网络配置等非镜像字段的场景。
InPlaceIfPossible:优先尝试原地升级,如果变更内容超出原地升级的能力范围(比如修改了 Volume 或新增了容器),自动降级为 RecreatePod。这是推荐的生产策略——兼顾效率与安全。
InPlaceOnly:强制原地升级,如果变更无法原地执行则直接报错。适用于对升级停机时间有严格要求、且能确保只做镜像变更的场景。
原地升级的执行流程
当 Controller 检测到角色模板发生变化时,会进入如下决策和执行流程:
┌─────────────────────────────────────────────────────────────┐│ Controller 检测到 ControllerRevision 变更 ││ (新旧 Revision 的 JSON Patch Diff) │└─────────────────────────┬───────────────────────────────────┘ │ ▼┌─────────────────────────────────────────────────────────────┐│ 能否原地升级?逐组件检查: ││ 1. 组件数量是否变化?(增减 Pod → 不能原地) ││ 2. ServiceName 是否变化?(网络身份变更 → 不能原地) ││ 3. Pod 模板的 /spec/ 变更是否全部是 image 替换? ││ ✓ 只有 /spec/containers/N/image → 可以原地 ││ ✗ 涉及 volume/port/env 等 → 不能原地 ││ 4. metadata 变更(labels/annotations)→ 允许,合并处理 │└────────────┬──────────────────────────┬─────────────────────┘ │ 可以原地 │ 不能原地 ▼ ▼┌────────────────────────┐ ┌──────────────────────────────┐│ 执行原地升级 │ │ 降级为 RecreatePod ││ │ │ (InPlaceIfPossible 模式) ││ │ │ 或报错 ││ │ │ (InPlaceOnly 模式) │└────────────┬───────────┘ └──────────────────────────────┘ │ ▼┌─────────────────────────────────────────────────────────────┐│ Step 1:设置 InPlaceUpdateReady Condition = False ││ → Pod 被标记为 Not Ready,流量从负载均衡中摘除 │└─────────────────────────┬───────────────────────────────────┘ │ ▼┌─────────────────────────────────────────────────────────────┐│ Step 2:宽限期等待(如果配置了 gracePeriodSeconds) ││ → 等待已有请求处理完毕,避免中断正在进行的推理 ││ → 更新指令暂存在 annotation 中,不立即生效 │└─────────────────────────┬───────────────────────────────────┘ │ 宽限期结束 ▼┌─────────────────────────────────────────────────────────────┐│ Step 3:Patch Pod spec ││ → 记录旧容器的 ImageID(用于完成检测) ││ → 直接修改 Pod.Spec.Containers[i].Image 为新镜像 ││ → 更新 Revision 标签 ││ → 单次 API 调用完成所有变更 │└─────────────────────────┬───────────────────────────────────┘ │ ▼┌─────────────────────────────────────────────────────────────┐│ Step 4:Kubelet 执行容器重启 ││ → 拉取新镜像,重启变更的容器 ││ → Pod IP、Volume、节点调度位置均保持不变 ││ → 未变更的容器不受影响 │└─────────────────────────┬───────────────────────────────────┘ │ ▼┌─────────────────────────────────────────────────────────────┐│ Step 5:完成检测 ││ → Controller 对比 ContainerStatus.ImageID 与记录的旧值 ││ → ImageID 变化 → 确认新容器已启动 ││ → 设置 InPlaceUpdateReady Condition = True ││ → Pod 重新进入 Ready 状态,恢复接收流量 │└─────────────────────────────────────────────────────────────┘这里有几个设计细节值得关注:
宽限期(Grace Period) 的意义在于优雅停流。在推理场景中,一个请求(尤其是长文本的 Prefill 阶段)可能需要数十秒才能完成。如果不等待当前请求结束就直接重启容器,用户会收到中断错误。通过设置合理的 gracePeriodSeconds,Controller 先将 Pod 标记为 Not Ready(不再接收新请求),等待已有请求处理完毕后再执行镜像替换。
完成检测 不依赖"容器是否启动"这样的粗粒度信号,而是通过对比 ImageID 的变化来精确判断——只有当 Kubelet 确实拉取并启动了新镜像后,ImageID 才会改变。这避免了因网络抖动或镜像拉取失败导致的误判。
防重复更新:Controller 在执行原地升级后会通过 updateExpectations 追踪该操作,在 API Server 确认变更之前不会推进 CurrentRevision。这防止了因 informer 缓存延迟导致同一个实例被重复升级。
原地升级与跨角色协调
原地升级与前面提到的 CoordinatedPolicy 天然兼容。协调层只控制"多少个实例可以同时更新",而不关心"用什么方式更新"。这意味着在跨角色协调场景下,Prefill 和 Decode 的原地升级也会受到 maxSkew 的约束——Controller 确保两个角色的更新进度差异不超过配置的阈值,防止出现版本不兼容的状态。
实际收益
在生产环境中,将推理框架从 SGLang 0.5.8 升级到 0.5.9 时:
传统 RecreatePod 方式下,每个 Prefill 实例的更新需要经历"Pod 删除 → 重新调度 → 模型加载 → 就绪"的完整周期,单实例更新耗时约 5-8 分钟。整个集群的滚动更新需要数十分钟,期间服务容量持续受损。
使用 InPlaceIfPossible 策略后,Pod 的调度位置和 AI 芯片绑定关系保持不变,省去了重新调度的等待时间。虽然模型仍需重新加载(因为推理进程重启),但消除了资源竞争的不确定性,单实例更新耗时稳定在 3-4 分钟,整体升级时间和服务影响窗口显著缩短。
效果与思考
目前,大 EP 推理服务的自动部署与自愈方案已在线上稳定运行,主要改善体现在以下几个方面:

同时也有一些局限性值得坦诚面对:
端口分配存在理论冲突风险:采用随机策略而非全局注册,在端口范围较小或 Pod 密度极高时存在冲突概率(实际中可通过设置足够大的范围来规避)。
服务发现存在短暂不一致窗口:ConfigMap 的更新依赖 Controller 的 Reconcile 周期,更新期间可能出现短暂的不一致。
原地升级能力有限:目前仅支持容器镜像变更,如需修改 Volume 挂载或网络配置,仍需走 RecreatePod 路径。不过 InPlaceIfPossible 策略会自动处理降级,无需人工判断。
跨角色故障联动依赖框架自身:例如 Decode 故障后 Router 自动摘除对应节点,目前需要推理框架自身支持,RBG 尚未提供开箱即用的流量摘除能力。
从更大的视角看,LLM 推理基础设施正在从"单一框架 + 单一硬件"演进为"多框架 + 多硬件 + 多拓扑"的异构集群。RBG 提供了一个合理的抽象层——将"角色"作为基本编排单元,将"角色组"作为服务治理的原子粒度——这个抽象足够通用,可以适配 PD 分离、MoE 分布式、Pipeline 并行等多种推理架构。
我们后续的工作将围绕两个方向:一是在 RBG 基础上增强弹性伸缩能力,根据实时负载自动调整 Prefill 和 Decode 的比例;二是持续参与上游社区建设,将生产中遇到的问题和解决方案回馈给开源项目。




