
身份和认证服务公司 Authress 分享了其在重大云基础设施中断期间保持运营的策略,比如2025年10月亚马逊云科技(AWS)的大规模中断,这次中断影响了众多主要服务。Authress 首席技术官 Warren Parad 解释说,公司的弹性架构采用了依赖于多区域部署和最小化对 AWS 控制平面服务的依赖等策略。
Parad 表示,10 月 20 日的 AWS 事件是十年来最严重的一次。即便如此,Authress 仍然保持了其 SLA 可靠性承诺,这要归功于其以故障转移路由策略为中心的可靠性优先设计。
简而言之,我们的策略是利用 DNS 动态路由。这意味着请求进入我们的 DNS,它会自动选择两个目标区域中的一个,我们正在使用的主要区域,或者在出现问题时的故障转移区域。
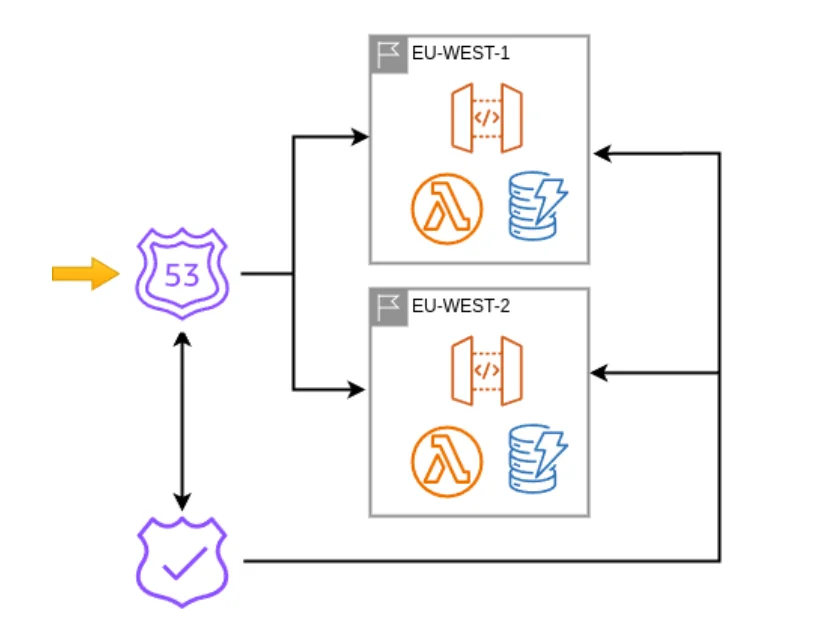
这种方法的一个关键部分是快速事件检测,使 DNS 层能够确定何时在区域之间切换流量。Parad 指出,Authress 有意避免依赖 AWS Route 53 的默认健康检查或任何第三方服务来监控可用性:
我们不知道这是 AWS 基础设施服务之间的通信问题,还是默认 Route 53 健康检查端点的问题,或者是与我们实际使用的代码交互方式有关的问题。
Authress 的自定义解决方案跨数据库、SQS 和核心授权器逻辑执行多项检查,同时还分析端到端请求延迟。这使他们能够可靠地确定主区域(总共六个)是否遇到问题,并相应地更新 DNS。
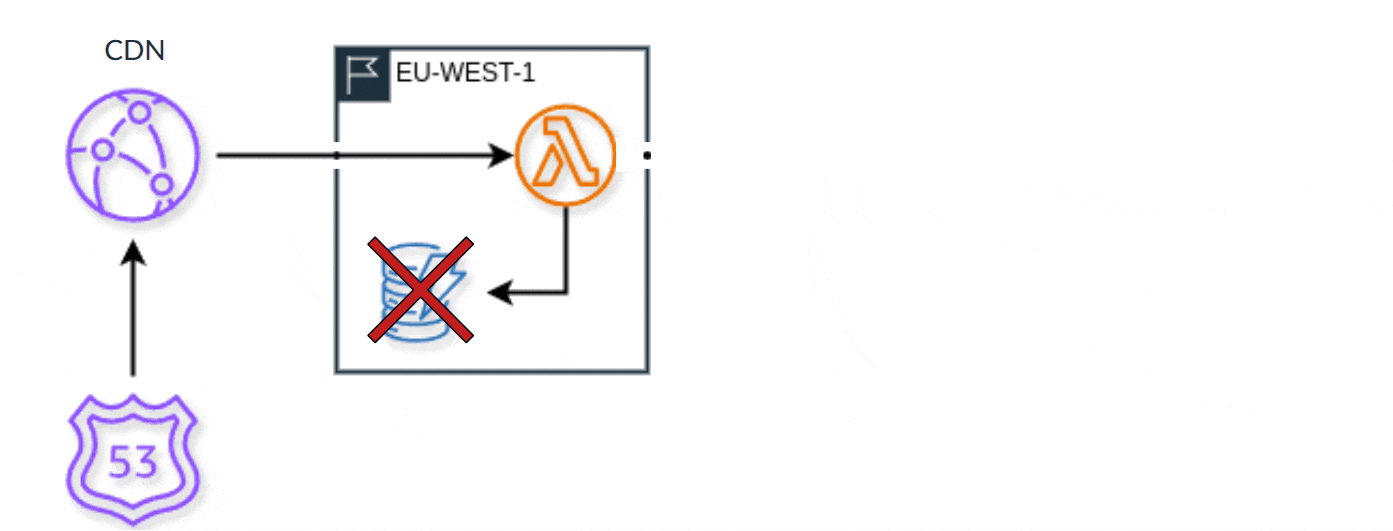
Parad 指出,虽然这种故障转移策略是一个坚实的起点,但它也有局限性。最值得注意的是,它不能很容易地隔离和替换单个故障组件。为了解决这个问题,Authress 设计了一个边缘优化架构,使用 AWS CloudFront 和 AWS Lambda@Edge 进行计算。
这种架构提供了两个好处:它使 Authress 服务更接近用户,减少了延迟,并且支持更健壮的故障转移策略。
使用 CloudFront 为我们提供了一个高度可靠的 CDN,它将请求路由到本地可用的计算区域。从那里,我们可以与本地数据库进行交互。当该区域中的数据库出现健康事件时,我们将自动进行故障转移,并检查第二个相邻区域中的数据库。当那里也有问题时,我们再对第三个区域做一次。
Authress 整体弹性策略中的另一个额外元素是解决应用程序级故障。Parad 承认,编写完全没有缺陷的代码几乎是不可能的,在设计系统时应该考虑到这一点。
Hacker News 的读者 rdoherty 指出:
这可能是对我过去 10 年 SRE 职业生涯的最佳总结。一旦你的系统变得足够复杂,总有一些东西会被破坏掉,你必须为此做好准备。检测和响应变得和预部署测试一样重要。
一些评论者担心自动化和 IaC 会引入额外的故障点。Parad 回应说,Authress 通过保持简单和小规模的方式来降低这种风险:
我们将基础设施拆分为单独的服务,所以每个基础设施都是简单的。在实践中,我们的基础架构不那么 DRY,而是更加重复,这样做的好处是避免了由于试图减少代码重复而导致的复杂性。附带的好处是,简单的东西变化不那么频繁。变化不那么频繁会减少出现问题的机会。
这是对 Authress 弹性方法的关键要素的简要概述,其中还包括根本原因分析、验证测试、影响评估、AI 驱动的非事件过滤等等。可以必查看原文以了解全部细节。
原文链接:
https://www.infoq.com/news/2025/12/infrastructure-resilience-aws/




