
整理 | 杨宇佳、罗燕珊
《2023 年金融级分布式数据库市场报告》主要从产品能力(如高可用性、运维迁移工具、可观测性)以及厂商能力(包括落地案例、产品文档、生态建设)等维度分析,研究周期为 2022 年下半年到 2023 年上半年。
由于遗留系统的负担和迁移的复杂性,我国金融机构通常面临着从国外数据库产品向国产数据库迁移的挑战。不过这些年,随着对安全合规和自主可控的需求增加,国产数据库在金融行业中得到了加速发展。
根据咨询研究机构沙利文(FROST & SULLIVAN)发布的《2023 年金融级分布式数据库市场报告》,近四年,金融级分布式数据库市场的发展经历了以下三大节点:
•2018-2020 年,自主可控需求显著提升,金融机构开始加强对金融级分布式数据库的规划布局,外围系统开始进行投入验证;
• 2021-2022 年,经过合作的验证,头部国产数据库厂商得到认可,金融级分布式数据库开始向核心系统转移;
• 2023 年,已在核心系统投产的案例已得到积累,市场对于金融级分布式数据库的关注逐步从“能用”转变为“好用”。
沙利文认为,当前金融级分布式数据库行业发展对数据库厂商的能力要求更为精细化,经过深度合作打磨产品性能与提高场景需求适配能力的厂商已形成难以打破的竞争壁垒,金融级分布式数据库市场竞争格局已越来越明确。
当前实际应用和挑战
该报告分析了金融级分布式数据库的实际应用和挑战。理论上,金融级分布式数据库是可以提高性能、可靠性,实现成本降低和效率提升。但实际操作中,存在诸如系统复杂性管理、应用架构改造、保持数据一致性、数据迁移整合等难题,以及对技术人员的高能力要求。并且金融机构还需要考虑业务连续性和各种内外部压力。

为实现真正的降本增效,沙利文建议在数据库的选型评估、部署配置、运维迭代等三个阶段,结合数据库厂商竞争核心要素中的能力进行周密规划,从而做好投入总成本的控制(包括产品学习成本、部署与适配成本、使用成本等)。
另一方面,数据库厂商应提供帮助,包括优质社区资源、产品文档、案例参考、兼容性高的产品等,以降低用户的学习、部署适配、使用成本。
信创是市场发展核心驱动力
报告强调,信创是国产分布式数据库发展的核心驱动力,核心在于实现自主可控。
但自主可控不仅限于掌握核心技术和源代码,还包括建立持续发展的自研团队、构建体现实践和经验的回归测试用例、进行知识共享以及有效沟通。而除了技术自主可控,还要实现服务、标准、生态的自主可控,以提供优质、安全、可靠的产品和服务,推动行业高质量发展。
报告进一步指出,信创技术推广遵循“先试点后全面、由外围到核心”的发展路线,通过小规模与在非核心系统落地,控制影响范围,同时也为全面推广积累经验和数据。在该背景下,金融级分布式数据库在市场整体呈现出“银行先行,非银后起”的趋势。
不过,随着多个金融行业核心系统的成功案例,分布式数据库在核心系统中的应用增加,提升了金融机构对分布式数据库的信任度和认可度,从而为整个市场的发展提供了强大的推动力。
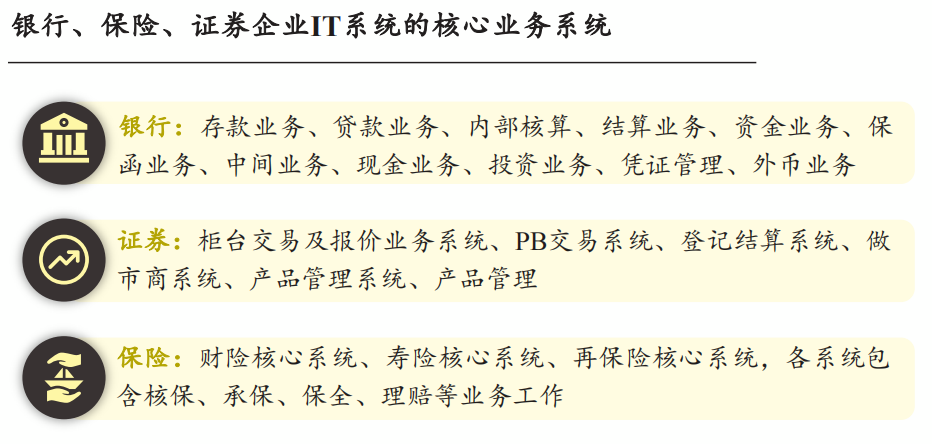
因此,在当前市场需求与竞争环境下,沙利文认为数据库厂商需要在性能与运维优化、安全能力、服务能力、实践积累四大方面完成较好的布局与积累,这也是它们展开高质量竞争的核心基础。
金融应用逐渐成熟,步入整合阶段
从行业生态的角度,报告指出,国产数据库行业在金融领域应用逐步成熟,标志着从混沌阶段向整合阶段的过渡。
沙利文认为,行业应坚持“以产品为中心”的理念来完善数据库发展生态,通过有效合作推动可持续发展。同时,行业标准和规范的建立,加上技术、服务、人才等方面的发展,将为整合阶段提供良好基础。此外,为了适应市场和技术的变化,需要加强行业的可持续发展能力,通过增强利益相关方间的合作与交流,顺利完成整合阶段的任务。
特别是在金融行业,采用产-金-研-用模式(即厂商根据金融客户的需求,与高校合作提前布局研发、与金融科技企业合作研发、独立自研,完成技术需求的工业化实现),进一步加强与产业链伙伴和技术咨询机构的合作,提高产品文档和技术分享的质量,促进对国产数据库的理解和使用。
再者,针对国产数据库所面临的落后或抄袭等争议,政府和行业机构需制定标准来筛选厂商、规范市场,推动高质量发展,同时加强产学研布局,建立经验交流和知识共享机制,促进技术创新和市场认知。通过这些措施,国产数据库将能实现健康发展、消解劣评标签。

参考链接:https://mp.weixin.qq.com/s/VN_MO9jHRblCAKDSI5dBwQ
延展阅读:《国产金融级分布式数据库在金融核心场景的探索实践》





