
看图能解高中函数题,能分析物流单和发票这样的复杂图表,还能根据风景照片推测出拍摄地点,多模态理解、推理能力再次迎来突破。近日,阿里国际 AI 团队发布多模态大模型 Ovis2.5,在通用多模态基准、复杂图表理解与 OCR 等实际应用场景,Ovis2.5 均展现出领先的理解与推理能力。
在主流多模态评测套件 OpenCompass 上,Ovis2.5-9B 综合得分 78.3,超越众多更大参数量的模型,在 40B 以下参数规模的开源模型中位居前茅;Ovis2.5-2B 综合得分 73.9,延续了 Ovis 系列小尺寸、高性能的理念,在同尺寸模型中性能显著领先。
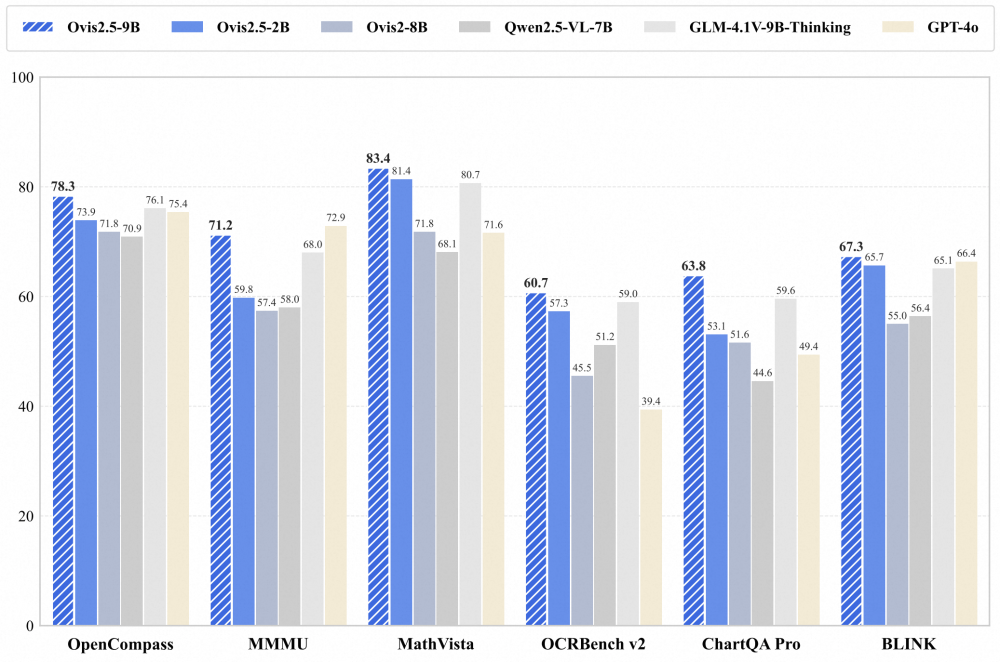
Ovis2.5-9B 在多个 benchmark 上取得了同尺寸开源最佳性能,Ovis2.5-2B 在很小的模型尺寸下也展现了优异的性能
相比 Ovis2 等早期版本, 升级版的 Ovis2.5 在处理复杂图表、数学题推理、知识储备等方面都有亮眼表现。例如,Ovis2.5 可以看图求解函数题、看风景照片分析地点并找到应景的古诗。

Ovis2.5 数学推理能力示例

Ovis2.5 复杂图表分析能力示例
Ovis2.5 知识能力示例

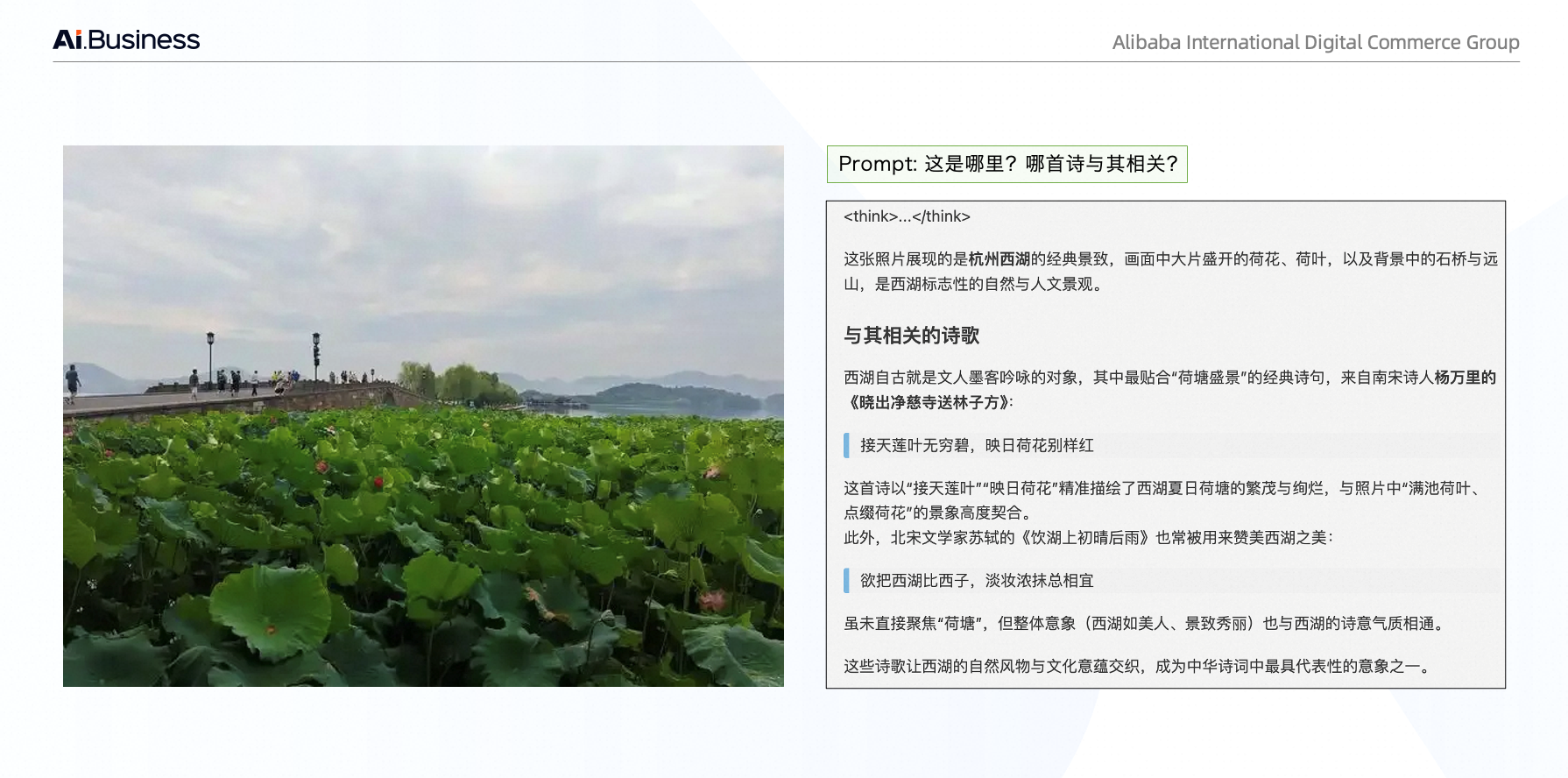
Ovis2.5 定位能力示例
具体来说,Ovis2.5 有三方面的能力进化:
1、看图更完整,不需要“先切分再合并”
在 Ovis2 及早期版本中,高分辨率图片需要通过“切图-拼接”处理,这往往导致整体结构与细节信息的损失。为解决这一问题,Ovis2.5 集成了原生分辨率视觉编码器(NaViT),能够直接处理任意原生分辨率的图像,让模型真正做到“完整看图”。无论是宏观布局还是微小文字细节,都能精准捕捉,为复杂场景下的深度推理奠定坚实基础。
2、深度推理“思考模式”,能自我检查与修正
Ovis2.5 融入了包含自我检查与修正环节的长链思考训练,使模型能够在解决问题时进行自我反思。在推理时,用户可以选择开启“思考模式”:模型会生成中间步骤,主动检视并修正推理过程,从而在数学题求解、复杂图表等高难度任务中获得更高的准确率。这一机制提供了延迟与精度的灵活权衡,用户可根据需求自由切换。
3、攻克复杂图表难题
复杂图表理解一直是多模态领域的“硬骨头”,大量噪声和密集的视觉信息给模型带来了巨大挑战。Ovis2.5 针对这一痛点,从三个层面进行了系统性增强:
数据端:新增了海量高质量的图表、OCR、Grounding 数据。
视觉端:利用原生分辨率编码器,准确全面地理解图表中的元素。
推理端:结合深度思考能力,对图表中的数据和逻辑关系进行精准分析。
在模型尺寸较小的情况下,Ovis2.5 实现了性能与效率的双重突破,在端侧和资源受限的场景下能发挥出“小身板、大能量” 的效果。据悉,Ovis 累计下载量超 280 万,在多模态领域最近一个月下载量仅次于 QwenVL 模型。
在 AI 领域,具有推理能力的多模态大模型应用场景特别广泛。例如,在快递分拣场景,能够识别快递面单照片上的订单号、收件地址等各种信息,并遵循指令以 JSON 格式输出,提升物流效率;在自动驾驶场景,能够处理不同模态的信息,精准感知环境、作出决策。随着人工智能的发展,大模型的多模态理解能力、推理能力升级也逐渐成为行业趋势。
据此前报道,阿里国际 AI Business 团队成立于 2023 年,基于全球化电商场景探索 AI 技术。目前,阿里国际的所有电商平台均已应用 AI,已服务了超 50 万卖家,形成了以服务中小企业出海为核心,覆盖全球多元市场、多种电商模式的规模级 AI 应用。当下,阿里国际 AI 服务的调用量每两个月就会翻一番,截至 2025 年 7 月,平均日调用量已突破 10 亿次。
附相关链接:
技术报告:https://arxiv.org/abs/2508.11737
代码: https://github.com/AIDC-AI/Ovis
9B 模型: https://huggingface.co/AIDC-AI/Ovis2.5-9B
2B 模型: https://huggingface.co/AIDC-AI/Ovis2.5-2B




