
本文描述了一个自动化的 CPU 垂直扩展系统的实现,在该系统中,优步(Uber)上运行的每个存储工作负载都被分配到了理想数目的内核。如今,该框架已被用于调整超过 50 万个 Docker 容器,自其建立以来,已净减少了超过 12 万个内核的分配,从而每年节省了数百万美元的基础设施支出。
在优步(Uber),我们在容器化环境中运行所有的存储工作负载,如 Docstore、 Schemaless、M3、MySQL、Cassandra、Elasticsearch、etcd、Clickhouse 和 Grail。总的来说,我们在将近 7.5 万台主机上运行了超过 100 万个存储容器,其中 CPU 内核数超过了 250 万个。为了降低相邻组件间互相干扰的风险,每个工作负载都分配了一组独立的 CPU 内核,并且主机不会超额配置。我们还运行了一个多区域复制设置,它允许数据流量作为事件响应的一部分从整个区域中流出。
图 1:优步状态管理平台的关键指标。
一个主要挑战是为每个容器分配正确数量的 CPU 内核。 直到最近,为每个容器设置的适当内核数量都是由负责每种存储技术的工程师手动确定的。
这种方法的优点是,领域专家有责任监控他们的每项技术并做出正确的决策。缺点是,需要人工来完成这项工作,而且当设置会导致成本或可靠性问题时,这往往会成为一种响应式的扩展策略,而不是一种主动的方式,即根据实际使用情况垂直扩缩容器,以确保以尽可能低的成本实现一致的性能。
为 CPU 垂直扩展选择正确的度量指标
正确调整容器大小的第一步是定义我们所说的“合适大小”。简而言之,我们希望在不影响容器中运行的工作负载的性能的情况下,为每个容器分配尽可能少的资源。
可以使用不同的策略来确定要分配给每个存储容器的正确内核数目。一种非常直接的方式是在核心业务指标(例如,P99 延迟)和容器分配之间建立反馈回路。如果反馈回路足够紧凑和快速,则可以提高或降低分配,以确保始终能有正确分配。然而,这种方式不太适合管理存储工作负载,原因如下:
在主机之间移动存储工作负载可能需要数小时。由于数据需要与计算资源一起携带,因此必须避免使用在主机之间频繁移动工作负载的模型。
负载在一周之内可以很容易地改变 2-5 倍。由于负载变化如此之大,很难创建一个模型来确定要分配的最佳内核数量,因为大多数情况下,容器都会被超额配置。
不同的用例将有不同的关键指标来进行监控。构建一个适用于批处理工作负载的模型将与低延迟用例(比如,为 Uber Eats 应用程序提供餐厅菜单)大不相同。
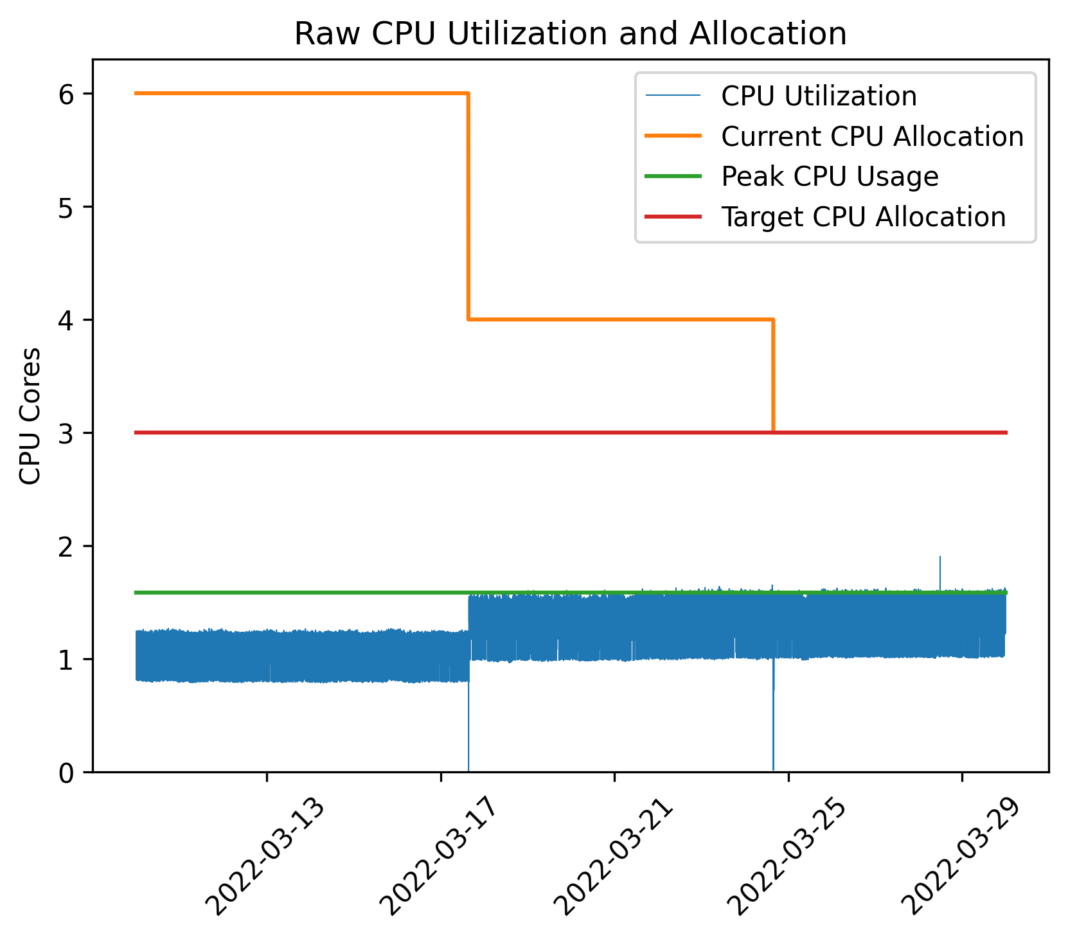
图 2:展示了存储容器的 CPU 利用率(蓝色)、整个期间测量的峰值利用率(绿色)、当前分配(橙色)和要达到的最佳分配(红色)。在数周的时间内,扩缩器在几周内逐渐将分配收敛到最优值。
我们没有监控关键业务指标,而是基于每个存储容器的外部测量 CPU 利用率构建了一个模型。该模型确保了历史测量的峰值 CPU 利用率和分配给容器的内核数量之间的特定比率。峰值使用率和分配之间的比率将被称为 CPU 使用率。图 2 显示了基于过去 14 天 CPU 使用率的模型如何确定峰值使用率(绿色),并由此计算目标分配(红色)。该图还显示了当前 CPU 分配(黄色)如何逐渐收敛到绿线的。
这种方式的好处如下:
CPU 利用率指标始终可用。这确保了我们可以创建一个“适合所有人的模型”,避免了为每种存储技术或用例创建模型的耗时工作。
CPU 利用率指标每周都相当稳定,因此在大多数情况下,过去两周就能相当准确地预测未来几周的峰值使用情况。
在区域故障转移(failover)期间,CPU 利用率往往会以可预测的方式增加。通过设定目标,比如 40% 的 CPU 利用率,可以相当肯定的是,在区域故障转移期间,CPU 利用率不会超过 80%,在最坏的情况下,负载会短暂地增加一倍。有关如何计算峰值 CPU 利用率的更多详细信息将会在下一节中介绍。
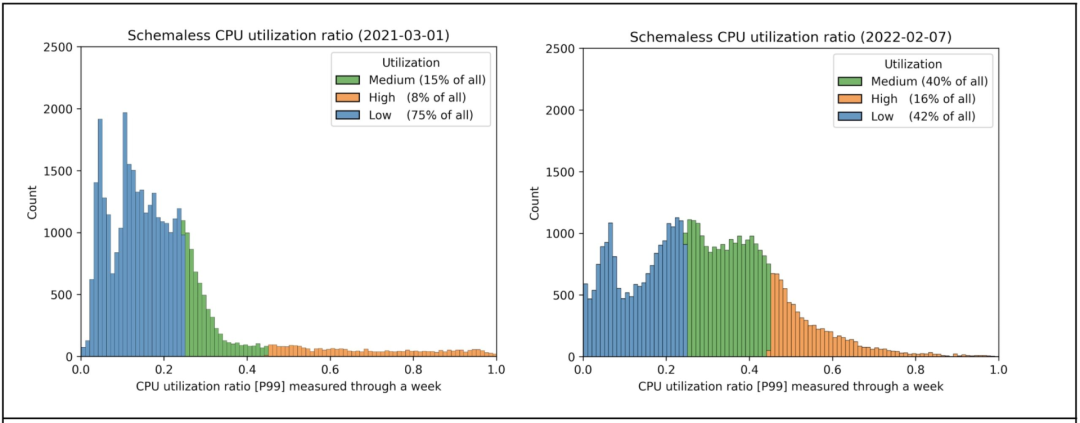
图 3:对大多数 Schemaless 实例应用 CPU 扩展前后的峰值 CPU 利用率直方图。低(Low)是指峰值使用率低于 25%,高(High)是指峰值利用率高于 45%。处于低类别从来都是不理想的,但有时是必要的。对于不受事件 / 故障转移影响的存储实例来说,处于高类别是有意义的。
图 3 显示了 Schemaless 技术启用 CPU 垂直扩展前后的峰值 CPU 使用率的直方图。默认情况下,扩缩器设置为以 40% 的峰值 CPU 使用率为目标。选择 40% 是为了确保有空间进行区域故障转移(可能会使负载增加一倍)。之所以选择 40%,是因为我们不想超过大约 80% 的 CPU 利用率。由于启用了超线程,当 CPU 利用率超过 80% 时会出现拥塞问题。
对比图 3 中的前后,我们可以观察到超额配置分配(低类别)的比率显著下降了。它之所以没有完全消失,主要是因为 Schemaless 运行在基于 Raft 的领导者 / 追随者 (Leader/Follower) 设置中,每个集群只有一个领导者(leader)。只有领导者可以提供一致的读取,并且对于某些用例,它的请求率明显高于其他用例。在任何给定的时间里,任何其他容器都可以成为领导者,因此,来自同一集群的所有容器都要均衡扩缩。
从图 3 也可以清楚地看出,高类别容器的比例有所上升。这实际上是有意为之的,因为我们已经意识到,在区域故障转移期间,一些存储集群的负载不会增加太多。因此,对于这些集群,我们可以设定一个明显更高的峰值使用率。
正确调整与 Schemaless 相关的所有容器的大小的最终效果是总体减少了大约 10 万个内核,即约 20%。Uber 使用的典型主机有 32 核或 48 核,分配率在 83% 左右,在大多数情况下,CPU 内核是瓶颈。因此,这 10 万个内核可以节省 3000 台主机(终端用户的延迟不变)。
CPU 垂直扩缩器 不仅节省了大量的成本,而且还确保了全面一致的性能和可靠性。在区域故障转移期间,这一影响非常明显,因为现在容器普遍地被分配了所需的资源,因此不会像过去那样产生延迟下降。
计算分配目标
上一节讨论了为什么可以使用 CPU 容器指标来垂直调整存储工作负载的大小。在本节中,我们将更详细地介绍如何准确地计算目标。术语 Pod,借用自 Kubernetes,在下文中它将用于描述在单个主机上运行的存储工作负载的容器集合。
如前所述,计算每个 Pod 要设置的 CPU 分配模型是:基于计算峰值 CPU 利用率,然后将其转换为确保给定峰值 CPU 利用率的分配。另一个重要的注意事项是,同一存储集群中的所有 Pod 必须分配相同数量的内核。原因是存储集群内的职责可能会随着时间的推移而变化,因此必须为所有 Pod 分配足够的资源,以便它们能够成为集群中最繁忙的 Pod。
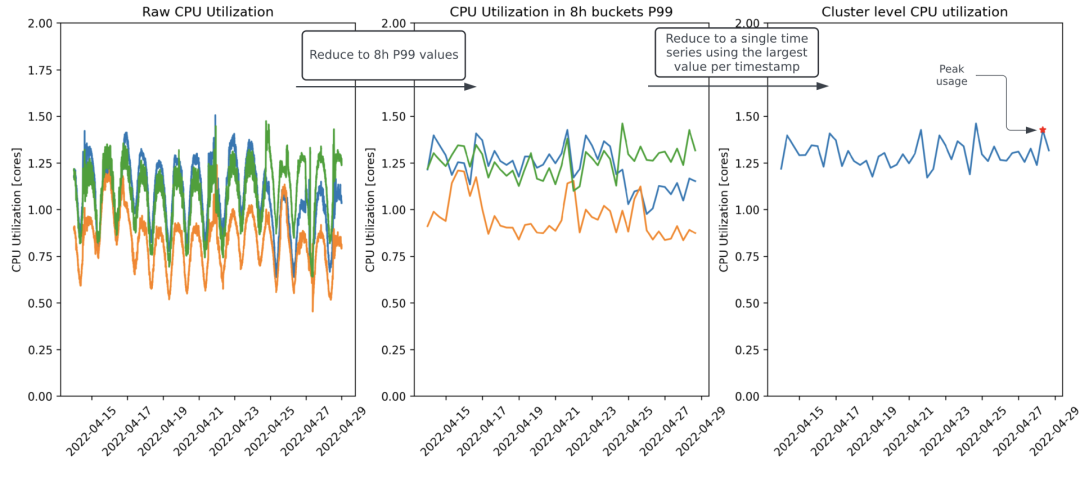
图 4:计算给定存储集群的峰值 CPU 利用率所涉及的步骤。默认情况下,总是回溯两周,以确保周末峰值在数据集中得到很好的体现。
图 4 显示了如何根据过去 14 天的 CPU 利用率数据计算峰值 CPU 利用率。CPU 利用率数据是使用 cexporter 收集的,并作为时间序列发布到我们的监控堆栈 M3 中。该算法的步骤如下:
从同一存储集群所有 Pod 的原始 CPU 利用率信号开始。使用两周的窗口与优步系统负载变化的时间尺度相匹配,因为我们以每周模式为主,峰值负载发生在周五和周六晚上。使用 2 周回溯可以确保数据集中始终包含 2 个周末。
将原始时间序列降采样(downsample)到 8 小时分辨率。在此步骤中,每个 Pod 的原始时间序列被降采样为 8 小时分辨率,计算每个时间窗口的 P99 CPU 利用率。8 小时时间间隔的 P99 确保 CPU 利用率在每 8 小时的窗口中最多有 5 分钟超过这个值。我们已经尝试了从 4 小时到 24 小时的不同采样窗口。使用 8 小时似乎可以提供良好的信噪比,可以避免过度索引异常值,但也不会错过重要的峰值。
将每个 Pod 信号压缩为集群信号。在此步骤中,根据时间戳来选择最繁忙的 Pod 的值。这会将每个 Pod 的信号压缩为集群级信号。对于像 Cassandra 这样的存储技术,每个集群有大量的 Pod,因此取而代之的是根据时间戳选择 P95 值。
将第三高峰值定义为集群的峰值 CPU 利用率。在最后一步中,从集群的 42 个数据点(14 天 *3 个数据点 / 天)中提取峰值 CPU 利用率。峰值 CPU 利用率被定义为第三高的数据点。通过选择第三高的数据点,我们避免了对异常值的过度索引。在确定了每个集群的峰值 CPU 利用率后,我们将配额计算为:

配额被四舍五入到最接近的整数,以避免小数内核分配。我们希望避免由于使用 cpusets 进行工作负载分离而导致的小数内核分配。
总 结
自 2021 年初启用 CPU 垂直扩展以来,优步通过该工具减少了超过 12 万个内核分配,节省了数百万美元的硬件开支。同时,我们通过确保所有存储 Pod 的大小一致性,提高了平台的整体可靠性。
由于工程师现在只需要表达所需的利用率,而不必手动计算和执行分配更改,因此在正确调整存储集群大小方面所花费的工程工作也大大减少了。他们正在进行根据故障转移行为和临界性确定每个存储群集要设置的最佳利用率的工作。
原文链接:




