
中国 AI 产业正在全面爆发,各行业的 Agent 应用发展更是迅猛。对企业来说,管好这些 Agent 并不容易,首先难算清的就是“成本账”——算力使用情况看不清、Token 资源浪费管不住、AI 投入省不下。
为了帮助各行业用户实现 AI 模型和算力的高效治理,深信服发布 AI 算力网关,与用户共同应对 AI Agent 时代的算力挑战。
深信服 AI 算力网关,是用户自己的“AI 算力智能调度中枢”,能为用户实现 Token 治理、成本治理、安全治理。通过强大的可见性,以及“看到 - 管好 - 用好”的全生命周期护航,将 AI 能力转化为驱动业务持续增长的核心引擎,让用户的每一份算力都看得清、管得住、省得下、用得稳、更安全。
用深信服自己来举例,3000 人的研发团队,在用上 AI 算力网关之前,每个月 Token 花费上百万,AI Coding 本地算力成本上亿。现在,通过 AI 算力网关对算力的调度及一系列的优化手段,外部 Token 调度成本每月可节省 40 万+,本地算力成本直降数千万!
深信服 AI 算力网关从 3 个层面解决问题。
一、3 个角度,方方面面搞定 Token 治理
Token 用了多少、用在哪里,搞不清、管不住;模型频频卡顿出错,业务稳定性无从谈起。要让 AI 转型更高效,就得先治理好 Token 资源,在这方面,深信服能帮用户做到:看得清、管得住、用得稳。
1、看得清:强大的算力+模型可见性,提升 AI 落地效率
如果你还在经历:各种算力买了很多,使用量很大,但难以获知各部门 Token 的使用情况,有了深信服 AI 算力网关之后,一切状况都能看得清了。
(1)开放兼容、统一入口,所有算力及模型资源皆在眼前
通过统一的入口,我们可以看见各类云端模型、本地和租赁算力,在统一的管理界面里,用户可以直接完成模型和算力资源的接入。
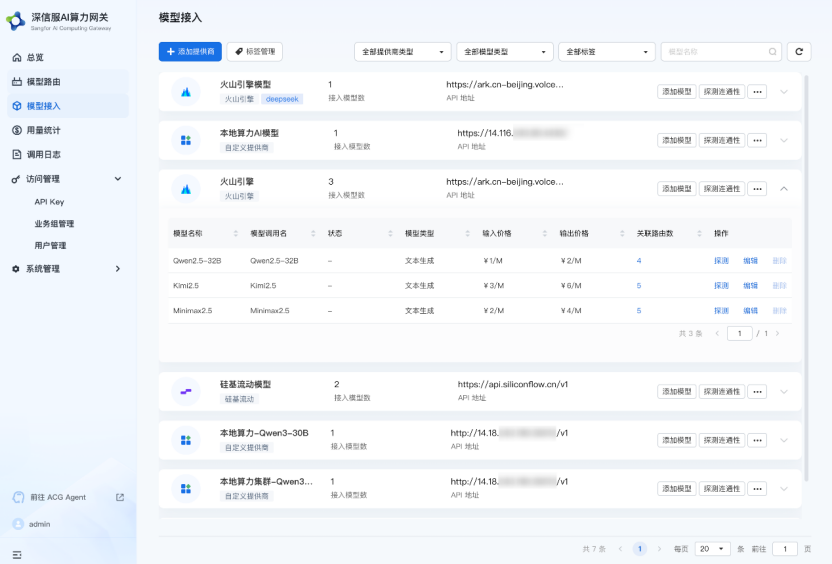
各类模型接入兼容 OpenAI 和 Anthropic 等协议,各类算力的接入也不会被算力平台厂商绑定。当需要扩展更强大的模型服务时,无需改造 AI 应用即可快速获得最新模型能力,并由 AI 算力网关统一对接。
(2)可视可控,Token 用量一览无遗,加速 AI 转型
AI 算力网关可以进行精细化用量统计,用户可分别从业务组、应用等维度看见 Token 的调用量、消耗额度、成功率、配额等情况,从而有效推动各部门 AI 转型、推动明星 AI 应用的推广。
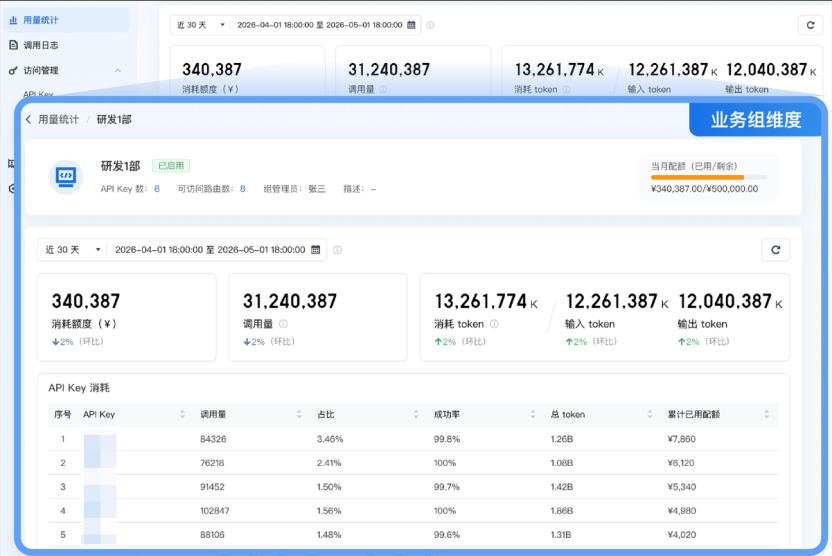
从业务组维度查看 Token 使用情况
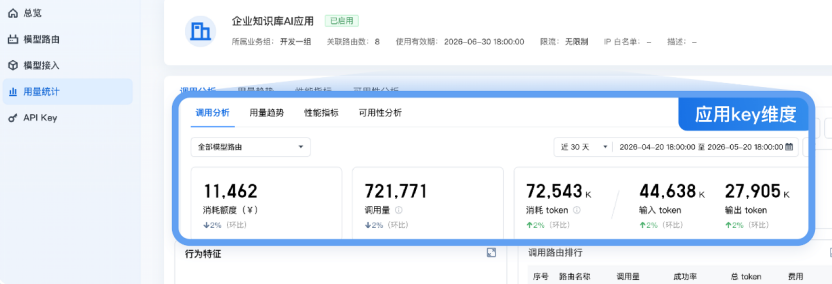
从应用维度查看 Token 使用情况
通过打造强大的可见性,帮助用户以细颗粒度的 Token 治理,真正看清算力资源的状况,让 AI 创新在组织内的落地速度得到数倍提升。
2、管得住:AI 算力精准管理,让每一分算力用有所值
各部门都说算力不够用,但这些资源到底有没有用在真正有价值的场景?有了 AI 算力网关,AI 资源的管理和控制就有了科学手段,想知道算力用在哪、哪些业务需要重点保障,都没问题。
在 AI 算力网关里,我们可以按照组织架构和 API Key 进行配额管理,管理员可以为下属组织和员工设置 Token 费用配额。为保障重点业务的运行,还可以对不太关键的需求或异常请求进行精准限流,让算力优先流向更有需要的地方。
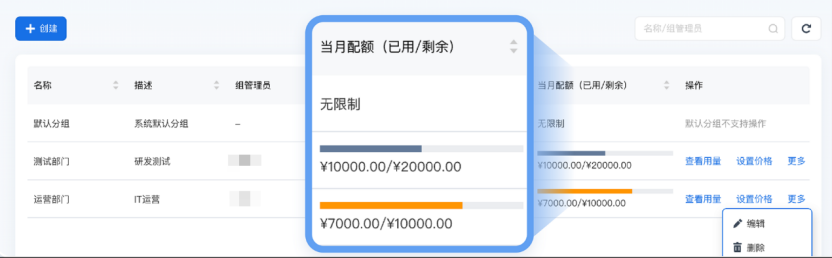
AI 算力网关通过对 Token 的精细管控,可以让全局 Token 消耗降低 50%,核心业务 AI 算力保障能力提升 2-3 倍。
管好算力资源之余,AI 算力网关还能帮助用户更好地管理显卡资源,将私有基础设施服务化,实现本地算力 API Key 的管理和限流,模型服务也可进行多 Key 精细化权限控制,满足不同部门的资源需求,显卡资源利用率倍增。
同时,面向所有算力建设,AI 算力网关提供 GPU 基础设施服务化能力,现在已经完成业界主流显卡的兼容适配,各类新卡新模型可快速适配。
3、用得稳:让 AI 业务运行更稳定、更可靠
把 AI 算力管好了、治好了,我们还需要关注 AI 业务的实际运行够不够稳定。在这方面,AI 算力网关主要从两个方面发力——
(1)创新技术模型聚合路由,让单点故障不再影响业务,敏态 AI 业务体验更流畅可靠。
模型服务一旦出现卡顿、异常,甚至宕机问题,就会严重影响业务的正常运转,带来业务损失。AI 算力网关通过配置跨本地资源池、跨模型供应商的轮询调度策略,来避免业务高峰单点模型服务过载故障,保障服务流畅稳定。
同时,还可以通过配置本地算力+云端模型优先级策略,让云上云下的模型弹性切换,自动分流,缓解高峰压力,从而保障 AI 业务的流畅运行。
(2)平台自身生产级可靠,匹配生产级核心业务需求
除了规避故障风险,AI 算力网关本身具备生产级可靠性,以极低开销时延、多实例热备能力和高可靠基础设施底座,保障用户的生产业务体验。
在看得清、管得住、用得稳之余,AI 算力网关还为 Token 治理配置原生 Agent,CEO、财务、HR、CIO、研发等各角色,只要向它提个问,就可以在此获取 Token 投入与业务成效的投入情况,一目了然。
二、关键技术加持,分分钟搞定成本治理
当用户的 AI 建设越来越深入,和成本挂钩的难题就会越来越多——云端各种 MaaS 模型如何选择?算力不够只好堆显卡?云端和本地哪个更划算?
深信服全力打造创新技术,为用户持续、大幅降低本地算力和模型费用。
省得下:创新技术加持,让 AI 越用越省钱
传统的模型调度方式基本是黑盒化,各类问题都可能去调用最贵的模型,导致企业成本居高不下。本地算力也存在类似问题,如异构品牌显卡算力不均,导致大参数资源池算力不够用,中小参数模型资源池却利用率低下。现在,AI 算力网关可以帮忙优化这类成本难题了。
深信服创新自研的智能路由引擎,就是 AI 算力网关实现成本优化的核心技术之一。
智能路由引擎有两个硬核的特点:
可解释性高:支持在页面端实时追溯不同场景下的决策因子,这种白盒化的调度机制,让用户对每一笔算力流向都心中有数。
准确率高:深度适配 OpenClaw 等典型 Agent 请求特征。通过对任务意图的精准分类,AI 算力网关能确保不同类型的 AI 诉求都能匹配到最合适的算力资源。
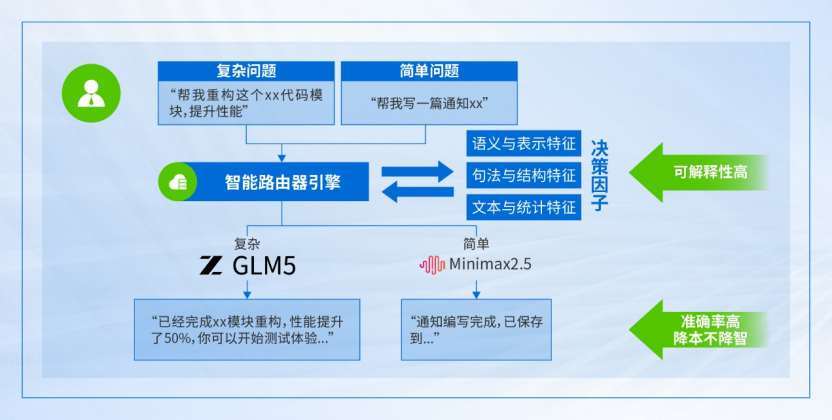
因此,AI 算力网关可以实现精准判断并将简单的问题调度到更简单的模型,将复杂问题调度到顶尖模型。保障效果的同时,用户每月可节省约 50%的成本!
而针对本地算力的使用,深信服也有创新技术突破,可实现大幅成本优化。
(1)对于大量大小模型混合使用的 Agent 构建场景
如 Embedding、Reranker、OCR、TTS 等,AI 算力网关支持算力 1%,256MB 级显卡资源切分,单卡承载模型数量可翻 8 倍以上,显卡越高端、模型使用越多,越省钱。
(2)对于重载 AI 应用场景
深信服 AI 算力网关通过自研的自适应架构层,提供工具、集成的监控等手段,来辅助定位应用场景的性能瓶颈,再结合自适应的原子优化能力,实现应用端到端承载的 ROI 提升。
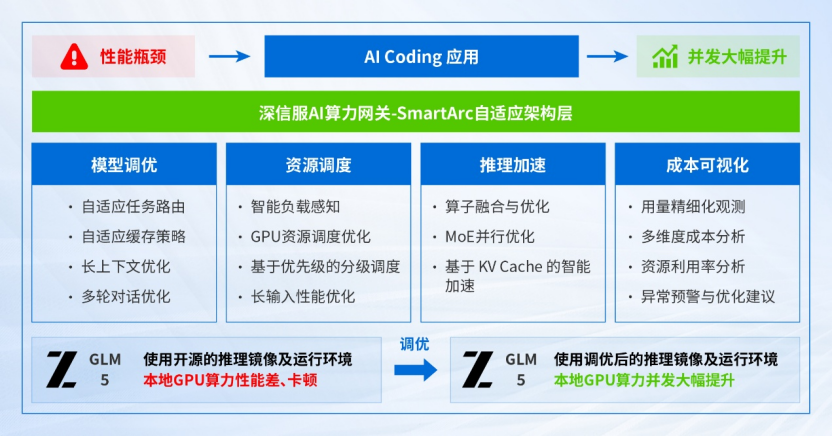
如 AI Coding 场景,深信服 AI 算力网关可以实现本地算力的 ROI 提升 2~5 倍起!
三、告别翻车,轻松搞定安全治理
Agent 的大量落地本身会带来巨大的安全风险。应用隐私数据无管控造成核心资产泄露、智能体自行删光数据信息等等,“翻车”事件频频发生。
更安全:核心资产不泄密
深信服 AI 算力网关继承了深信服自身的安全基因,在这方面做了充足防护。
AI 算力网关集成深信服大模型安全护栏,对接简单,一键即可开启,应用端无需改造即可根据不同的路由灵活配置安全策略,保障核心资产不外泄,业务运行更安全。
AI 落地、算力爆发,深信服 AI 算力网关不同于业界通用 API Gateway、单一 MaaS 平台或单点优化工具,不是“替代一切”,而在于补齐各行业用户在 AI 供给侧最缺失的治理与调度中枢,助力各行业用户 AI 创新效率大幅提升,在 AI 转型中告别成本焦虑,轻装上阵,让每一笔投入都转化为实实在在的、安全可靠的 AI 生产力。




