
数字公告板提供商 Pinterest 发布了一篇文章,解释了其新平台Moka在大规模数据处理方面的未来蓝图。该公司正在将核心工作负载从老化的 Hadoop 基础设施迁移到基于 Kubernetes 的系统上,该系统运行在亚马逊 EKS 上,以 Apache Spark 作为主要引擎,并即将支持其他框架。
在一个包含两篇文章的博客系列中,Soam Acharya、Rainie Li、William Tom 和 Ang Zhang 描述了 Pinterest 大数据平台团队如何考虑下一代大规模数据处理平台的替代方案,因为现有的基于 Hadoop 的系统(内部称为 Monarch)的局限性变得越来越明显。他们将 Moka 作为搜索的结果,以及基于 EKS 的云原生数据处理平台,该平台现在运行的生产负载达到了 Pinterest 的规模。该系列的第一部分关注整体设计和应用层。相比之下,第二部分转向作者所说的“Moka 的基础设施重点方面,包括经验和未来方向”。
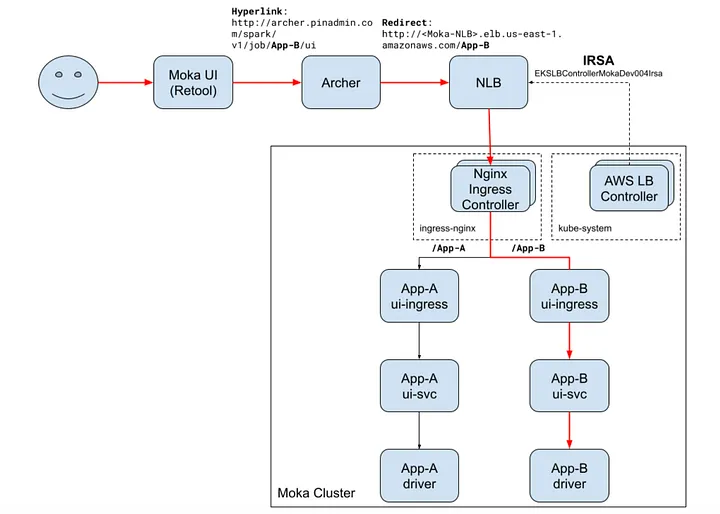
文章从实际角度描述了向 Kubernetes 的转变。它展示了一个全行业的转变,即大型技术公司现在将 Kubernetes 视为数据的控制平面,而不仅仅是无状态的服务平台。在大数据社区日益增长的受欢迎程度和越来越多的采用的鼓励下,团队探索了基于 Kubernetes 的系统,作为 Hadoop 2.x 最有可能的替代品。任何候选平台都必须满足可扩展性、安全性、成本以及托管多个处理引擎的精确标准。Moka 是如何在不放弃现有 Spark 投资的情况下现代化 Hadoop 时代的数据平台的一个例子。
第二篇文章的核心主题是如何在 Kubernetes 上以非常大的规模运行 Spark。作者解释了他们如何围绕 Moka 添加日志、指标和作业历史服务,以便工程师可以在不了解底层集群拓扑的情况下调试和调整作业。他们使用 Fluent Bit 对日志集合进行标准化,并使用 OpenTelemetry 和 Prometheus 兼容的端点发布统一指标。这为基础设施和应用程序团队提供了系统健康的一致视图。
Pinterest 还投资于通过基础设施即代码的方式使平台可重复使用。在文章中,团队概述了他们如何使用 Terraform 和 Helm 创建 EKS 集群、配置网络和安全以及部署支持组件,如 Spark 历史服务器。
Pinterest 的工程师还讨论了处理不同的硬件架构。他们描述了他们如何构建多架构镜像,以便他们的数据工作负载在 Intel 和基于 ARM 的实例上运行良好,包括 AWS Graviton,并将此与集群规模的成本和效率目标联系起来。InfoQ 编辑 Eran Stiller 在 LinkedIn上对该项目中的总结指出,Moka“提供了容器级别的隔离、ARM 支持、YuniKorn 调度,并通过整合工作负载和跨实例类型的自动扩展实现了显著的成本节省”。这些细节将工作置于云用户寻求在不牺牲性能的情况下削减基础设施成本的更大趋势之中。
关于处理引擎的更广泛的行业对话为 Pinterest 的故事增添了细微差别。在另一篇LinkedIn帖子中,Acharya 写道:“虽然 Spark 是我们的主要主力,但 Moka 的成功意味着 Pinterest 的其他用例也在效仿:Flink Batch 已经投入生产,Apache Ray 紧随其后,Flink Streaming 也将在今年晚些时候推出”。通过对 Spark 和 Flink 技术的深入探讨,我们可以了解到这一点的重要性。强调 Spark 仍然非常适合大型批处理和交互式分析工作负载,而 Flink 是“为实时、有状态的流处理而构建的”,具有严格的逐事件处理。团队将 Moka 呈现为一个灵活的基础,可以根据特定工作负载的需求添加不同的引擎,而不是一个只支持 spark 的平台。
外部观察者从 Pinterest 案例中吸取了教训。ML工程师通讯将 Moka 文章描述为“在 Kubernetes 上部署 EKS 集群、Fluent Bit 日志、OTEL 指标管道、镜像管理和 Spark 的自定义 Moka UI”的例子,将其与其他现代数据基础设施案例研究并列。这些反应表明,Moka 被视为一类云原生数据系统的参考架构。
然而,团队确实将他们的迁移工作呈现为一个正在进行的旅程,而不是一个已经完成的项目。在博客和进一步的LinkedIn帖子中,Pinterest 作者讨论了“经验和未来的方向”,并描述了早期概念验证如何导致随着对新堆栈的信心增长而逐步远离 Hadoop 的迁移。Acharya 指出,“最好的问题出现在规模上”,构建平台涉及“解决难题”,因为团队转移了实际工作负载。对于其他组织来说,这种经验可能是最重要的教训。复制围绕 Kubernetes、EKS 和 Spark 的技术选择相对简单,但从遗留系统中解耦并投资于可观测性、自动化和多引擎支持的过程可能是未来真正的工作。
原文链接:
https://www.infoq.com/news/2026/01/pinterest-kubernetes-bigdata/




