
整理 | 华卫
“这是我写过的最精神错乱的作品之一。”刚刚,特斯拉前 AI 总监、OpenAI 创始成员 Andrej Karpathy(安德烈·卡帕西)发布了自己最新的开源项目,一个名为 nanochat 的存储库。截止当前,该项目已在 GitHub 破了 7.9kStar!
GitHub 仓库:
https://github.com/karpathy/nanochat
据介绍,和卡帕西之前那个只包含预训练功能的类似仓库 nanoGPT 不同,nanochat 是一个极简的、从零构建的全流程训练 / 推理工具链,可用于搭建简易版 ChatGPT 复现模型,且整个代码库仅一个文件,依赖项极少。
花半天用 100 美元训练的模型,打败了 GPT-2
“100 美元能买到的最好的 ChatGPT”,卡帕西在公告中这样形容 nanochat。通过 nanochat,你只需启动一台云 GPU 服务器,运行一个脚本,最快 4 小时后,就能在类 ChatGPT 的网页界面上与你自己训练的大语言模型(LLM)对话。
具体来说,该项目可实现以下功能:
基于全新 Rust 语言实现版本训练分词器(tokenizer)
在 FineWeb 数据集上对 Transformer 架构大语言模型进行预训练,并通过多项指标评估 CORE 得分
在 SmolTalk 用户 - 助手对话数据集、多项选择题数据集、工具使用数据集上进行中期训练(Midtrain)
对聊天模型进行指令微调(SFT),并在世界知识多项选择题(ARC-E/C、MMLU)、数学题(GSM8K)、代码任务(HumanEval)上评估模型性能
可选通过 “GRPO” 算法在 GSM8K 数据集上对模型进行强化学习(RL)训练
在带有 KV 缓存的推理引擎中实现高效推理,支持简单的预填充 / 解码流程、工具使用(轻量级沙箱中的 Python 解释器),可通过命令行界面(CLI)或类 ChatGPT 网页界面(WebUI)与模型交互
自动生成一份 Markdown 格式的 “报告卡”,对整个项目流程进行总结,并将各项指标以 “游戏化” 方式呈现
据卡帕西介绍,即便成本低至约 100 美元(在 8 卡 H100 节点上训练约 4 小时),也能用 nanochat 训练出一个可对话的简易版 ChatGPT 复现模型,它能写故事、写诗,还能回答简单问题。训练约 12 小时后,模型性能便可超过 GPT-2 的 CORE 指标。

在 Github 上,卡帕西讲解了用 100 美元“极速训练”出最优 ChatGPT 模型的详细过程。
详细技术步骤:
https://github.com/karpathy/nanochat/discussions/1
若进一步将成本提升至约 1000 美元(训练约 41.6 小时),模型的连贯性会显著提升,能够解决简单的数学题、代码任务,还能完成多项选择题测试。例如,一个深度为 30 的模型训练 24 小时后(其计算量 FLOPs 与 GPT-3 Small(12.5 亿参数)相当,仅为 GPT-3 的 1/1000),在 MMLU 数据集上可取得 40 多分,在 ARC-Easy 数据集上可取得 70 多分,在 GSM8K 数据集上可取得 20 多分。
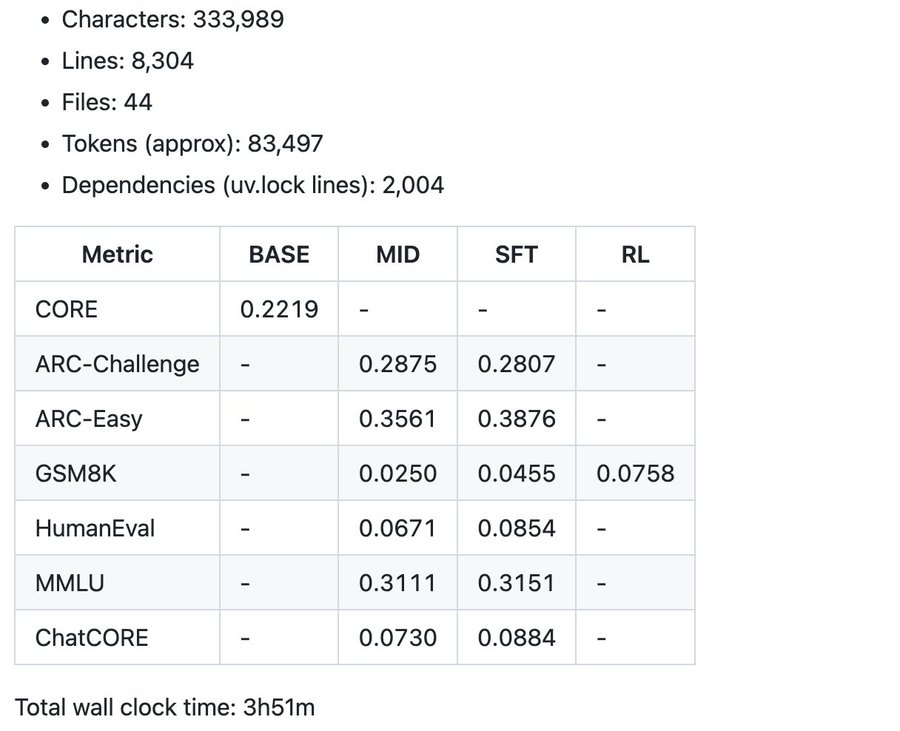
卡帕西的目标是将这套完整的 “强基准” 工具链整合到一个逻辑连贯、极简、易读、可修改性强、极适合分支开发(forkable)的代码仓库中。“nanochat 将成为 LLM101n 课程(目前仍在开发中)的核心项目。我认为它还有潜力发展成一个研究工具框架或基准测试工具,就像之前的 nanoGPT 一样。”
据其透露,目前这个项目绝非最终版本,既未完成全面调优,也未进行性能优化,但它的整体框架已足够完善,可以发布到 GitHub 上,后续所有模块都能在社区中进一步改进。并且,卡帕西称,实际上 nanochat 还有不少容易实现的优化点。
纯手写 8000 行代码,“Agent 帮不上忙”
整个项目总共只有约 8000 行代码,但卡帕西强调“代码结构相当清晰”。并且,这个代码仓库基本上完全是卡帕西手写的 , 也就用了个 Tab 键自动补全功能。
“我之前试过几次用 Claude 或者 Codex 的 Agent 来辅助,但效果都特别差,到头来反而帮不上忙;可能是因为这个仓库的代码风格和功能,跟这些工具训练数据里的常规代码偏差太大了吧。”卡帕西表示。
谈及 nanochat 的模型架构,卡帕西介绍,整体类似 Llama 模型,结构上更简洁一些,同时借鉴了 modded-nanoGPT(改进版 nanoGPT)的部分设计思路。
他尝试为该规模的模型确定一个可靠的基准架构,具体如下:
稠密 Transformer(无稀疏结构)
旋转位置编码(Rotary Embeddings),不使用其他位置编码
QK 归一化(QK Norm,对查询向量 Q 和键向量 K 进行归一化)
嵌入层(embedding)与解嵌入层(unembedding)权重不共享
对词元嵌入(token embedding)结果进行归一化
多层感知机(MLP)中使用 relu 平方(relu²)激活函数
根均方归一化(RMSNorm)中不包含可学习参数
线性层(linear layers)中不使用偏置项(biases)
多查询注意力(Multi-Query Attention, MQA)
对数概率软截断(logit softcap,限制 logit 数值范围以稳定训练)
nanochat 的优化器采用 Muon+AdamW 组合,该设计很大程度上参考了 modded-nanoGPT。据悉,目前卡帕西有一个待办项:尝试通过优化 Adam 的学习率(例如为不同模块设置专属学习率),来移除对 Muon 的依赖,但目前他还没有投入足够精力去做这件事。
网友:喜提机器学习工程师头衔
除了 Github,这次发布的 nanochat 在社交平台的热度也非常高。
“一直喜欢 Nano 系列项目!这套极简的端到端训练 / 推理工具链,一定会给众多机器学习学习者和科研人员带来深远影响。”一位网友说道。
也有网友表示,“对我个人而言,这个代码仓库是一份超棒的未来学习资料 —— 不管是理解基于 Rust 的底层深度学习实现,还是(更基础的)Python 深度学习开发,都很有帮助。”同时,他指出,“要是现在每个人都能借助这个仓库,用最少的精力训练出自己的大语言模型(LLM),那 Anthropic、OpenAI 这类公司的技术优势不就被削弱了吗?毕竟市面上有很多优秀的工程师,只要有足够的资源,他们完全有可能训练出更强大的大语言模型。”
还有人指出,“我认为这个代码仓库最大的受众是科研人员。很多人可能都有改进大语言模型(LLM)的想法,但要把想法落地成完整的实现,不仅需要投入大量精力,最终效果还充满不确定性。而现在,我们有了这样一套现成的工具流程,大家可以直接用它来做实验。以前只是‘如果能这样做会怎么样?’ 的空想,现在变成了 ‘我下周末就能试着把这个想法实现出来’ 的切实行动。”
甚至有网友开玩笑道,“跑完这个之后,我肯定要在简历上加上‘机器学习工程师’这个头衔。”
参考链接:
https://x.com/karpathy/status/1977755427569111362
https://github.com/karpathy/nanochat
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。




