
新年伊始,焱融科技再次在存储性能领域取得突破。通过最新的实验室测试,焱融 AI 存储产品——焱融追光全闪存储一体机 F9000X,搭载 4 张 NVIDIA 400Gbps NDR InfiniBand 网卡,并结合自主研发的 Multi-Channel 多网卡聚合技术,实现了 1.6Tb/s 的网络带宽聚合。3 节点存储集群的测试结果显示,性能达到 480GBps 带宽和 750 万 IOPS,相较市场同类产品提升了 3 倍。
这一突破性方案不仅大幅提升了性能,还有效降低了企业的总拥有成本:每 GB/s 成本减少 75%,每 IOPS 成本降低 30%。焱融科技凭借业界顶级性能,为大规模 AI 计算提供了理想的存储解决方案,加速 AGI 时代的全面到来。

AI 技术发展催生存储性能升级
近年来,AI 技术特别是生成式 AI 迎来了飞速发展的黄金时期,不断刷新着能力边界。伴随而来的是不断提升的对数据处理速度和效率的要求,这也在引发一场新的存储技术革命,对存储性能的要求不断提高。
1. AI 模型复杂度不断提升,存储性能需求攀升
随着生成式 AI 技术的持续创新,基础大模型已迈入多模态时代,模型参数和计算复杂度均呈指数级增长。这种发展显著提升了对存储带宽、容量和计算性能的要求。此外,随着模型规模和训练精度的不断提升,Checkpoint 也变得更大,进一步加剧了对存储吞吐量的压力。如果存储性能无法匹配模型的复杂度,整个 AI 训练链条将因“存储瓶颈”而受阻,影响模型迭代的效率。
而在模型推理环节,更大的数据量、更庞大的模型,以及更长的上下文窗口能够显著提升人工智能的效能。然而,推理过程需要应对大量并发请求且对响应时间要求极高。同时,AI 模型频繁更新和快速部署的需求也在不断增加。这使得存储系统必须具备低延迟和高吞吐量,以满足不断增长的应用需求。
2. 算力资源紧缺,GPU 利用率提升需求迫切
AI 技术的发展推动了算力需求的急剧增长,GPU 等算力资源供需矛盾突出。随着模型参数和复杂度的提升,模型训练所需的 GPU 算力也随之增加,目前最高已扩展到万卡乃至十万卡规模的大型 AI 算力集群。但现有基础设施在算力资源的可用性和优化方面仍存在诸多挑战。频繁的 CheckPoint 数据写入和断点续训造成算力资源闲置,算力集群的利用率偏低,增加了训练时间和计算成本。
在这种情况下,若能够将 GPU 利用率提升,就相当于增加了额外算力,从而能在更短的时间内完成更多的计算任务,降低模型训练的时间成本和经济成本。而提升 GPU 利用率的关键之一便是存储性能的升级。通过提升数据加载效率、加快断点续训速度,显著减少训练过程中的等待时间,提升算力资源的使用效率。
焱融存储全面激发,大规模 AI 计算集群效能释放
作为国内专注于 AI 存储领域的领先存储解决方案提供商,焱融科技针对日益复杂的 AI 模型训练和推理需求,不断进行存储技术创新,持续带来存储性能突破,以满足不断提升的 AI 计算需求。此次,焱融科技推出的 4 张 NVIDIA 400Gbps NDR InfiniBand 网卡的存储方案,依托于焱融追光全闪存储一体机 F9000X,通过公司自主研发的 Multi-Channel 多网卡聚合技术,提供 1.6Tb/s 网络带宽接入能力,完美适配 PCIe 5.0 NVMe 闪存,大幅提升数据访问速度和处理效率,释放 AI 算力的全新潜能。
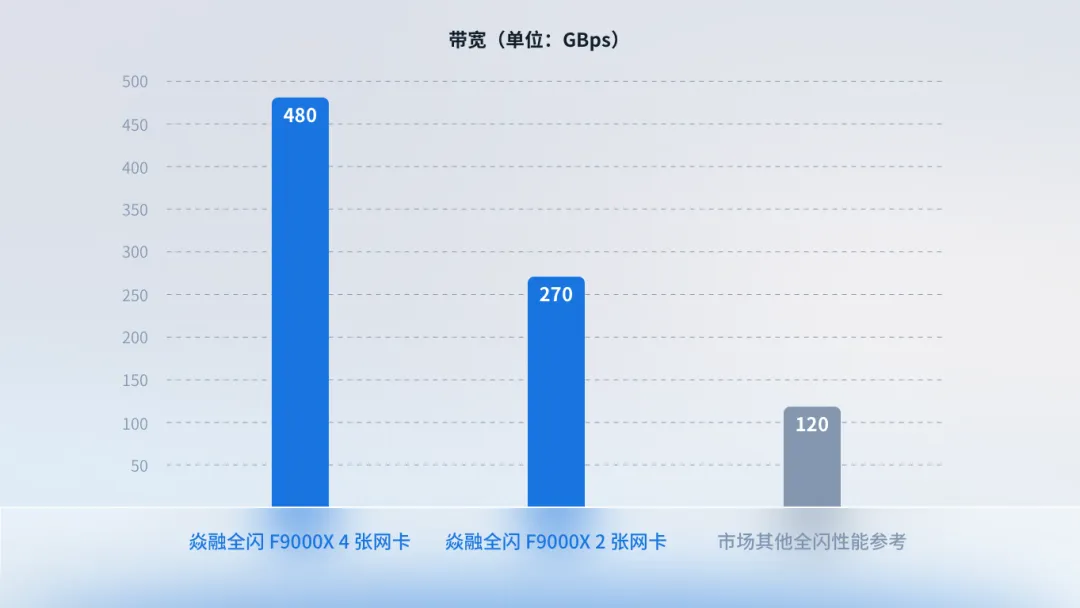
焱融全闪 F9000X 3 节点存储集群带宽性能对比
上图展示了焱融全闪分布式文件存储 F9000X 分别搭载 2 张和 4 张 NVIDIA 400Gbps NDR InfiniBand 网卡的 3 节点存储集群的实测性能。可以看到,采用 4 张 InfiniBand 400Gbps 网卡的焱融全闪 F9000X 存储方案,3 节点存储集群的带宽性能达到了 480GBps, 相较于 2 卡方案性能提升了近 80%,相比市场同类产品性能提升 3 倍;同时,其 IOPS 性能也达到了 750 万,保持业界领先水平。
在性能大幅提升的同时,用户的成本效益也得到了显著优化,年省算力成本达到千万级。每 GB/s 的成本降低了 75%,每 IOPS 的成本降低了 30%。这一成本优势意味着,企业在享受高性能存储带来的业务效率和竞争力提升的同时,还能够有效降低总体拥有成本,是大规模 AI 计算场景下的理想全闪存储解决方案。
先进的 AI 存储需要紧跟技术发展的步伐,满足日益增长的计算需求,提升用户体验。继在国际权威 AI 测评舞台 MLPerf Storage 中崭露头角后,焱融全闪 F9000X 再次实现性能飞跃。这不仅再次彰显了焱融科技在 AI 高性能存储领域的领先地位,也为行业树立了新的标杆,为不断迭代的大规模 AI 模型训练和推理等各类复杂计算任务提供强有力的支撑。
面向未来,焱融科技将继续深耕 AI 存储技术创新,持续提供领先的 AI 存储产品,为 AI 大模型、智算中心、自动驾驶、生信分析、金融量化等领域提供更强大的数据存储基座,推动这些领域的持续发展和创新。




