
ClickHouse 现已推出专为分析和可观测性构建的全新全文搜索功能,在一个引擎中结合了快速多词条搜索和大规模聚合。
这使得它成为 Elasticsearch 在日志分析领域一个极具吸引力的替代方案。本基准测试将揭示其原因。
最后一块“护城河”被填平
多年来,人们的选择很简单:Elasticsearch 用于文本搜索,ClickHouse 用于分析。
现在 ClickHouse 二者兼具。
ClickHouse 现已 集成了一个 重新设计的、由倒排索引 (inverted indexes) 驱动的全文搜索功能。但与传统搜索引擎不同的是,匹配的文档会直接送入其原有的向量化分析引擎 (vectorized analytical engine),该引擎在过滤、聚合和大规模扫描方面已 表现出色。
这种结合在搜索仅仅是第一步时显得尤为重要。在 可观测性领域,尤其是在日志分析中,搜索很少仅仅是为了查找文本。用户通常会先搜索某个错误模式,然后统计其出现次数、按服务分组、深入更小的时间范围,或者隔离受影响的主机。
换句话说:日志是恰好包含文本的分析数据。
在本次基准测试中,我们将在真实的 OpenTelemetry 日志工作负载下,对比 ClickHouse 和 Elasticsearch 的开源版本 (OSS versions) 在高达 500 亿行的数据集上的表现。
抢先看:在所有测试的数据集规模上,ClickHouse 执行全文分析工作负载的速度比 Elasticsearch 快 2-6 倍。此外,ClickHouse 存储 OpenTelemetry 日志数据集的效率也远高于 Elasticsearch。
完整的基准测试是端到端可复现的:源数据、Schema、查询、数据摄入脚本和测量结果均已发布在我们的 公共 GitHub 仓库中(https://github.com/ClickHouse/TextBench/tree/main) 。
接下来,我们将阐述基准测试的设置和方法,然后探讨这两个系统如何在磁盘上存储 OpenTelemetry 日志,最后比较它们的存储占用和查询执行时间。
基准测试设置
在揭晓结果之前,以下是完整的基准测试设置:数据集、查询、硬件和系统配置。
如果您更关注结果,可以直接跳转至存储占用和查询执行时间部分。
Dataset
该基准测试采用由我们的 OpenTelemetry 演示应用程序生成的真实 OpenTelemetry 日志数据集,该数据集产生的结构化服务日志与现代可观测性管道中常见的日志类似。
为确保基准测试完全可重现,所有源数据均以 Parquet 文件的形式发布在一个公共 Amazon S3 存储桶中。
区域:eu-west-3 (欧洲 — 巴黎);
公共存储桶:s3://public-pme/text_bench;
直接 URL:https://public-pme.s3.eu-west-3.amazonaws.com/text_bench/part_{000..009}.parquet;
文件结构:每个 Parquet 文件包含 10 亿条日志记录,并按时间戳排序;
提示:建议在 eu-west-3 区域运行 EC2 基准测试实例,以避免跨区域数据摄取延迟和出口费用。
基于这些源数据,我们以三种不同的规模,将相同的基准数据集加载到 ClickHouse 和 Elasticsearch 中:
通过这种方式,我们能够评估这两个系统从十亿行级别的部署到应对大规模生产可观测性工作负载时的表现。
查询
为了评估实际的全文分析搜索性能,我们使用了一套包含九个 OpenTelemetry 日志查询的集合。每个查询均基于单词或多词的全文搜索构建,并常常伴随过滤、计数、分组、排序或基于时间的聚合操作。
这些查询均使用各系统原生的查询语言实现(ClickHouse 使用 SQL;Elasticsearch 使用 Query DSL 和 ES|QL)。
这套查询旨在反映 Kibana 等工具中典型的日志分析工作流程,即用户搜索错误消息后,立即对其进行过滤、计数、分组、排序或随时间进行分析。
查询组合涵盖了四种常见的调查模式:
Q1–Q3:事件深入分析与日志检索
定位匹配给定术语的日志行,应用过滤器,并查看相关事件。
Q4–Q5:总体错误和匹配计数
计算匹配记录,或比较各子集之间的匹配量。
Q6–Q7:服务级别细分
根据服务名称、主机或严重性等维度对匹配日志进行分组,以识别问题集中之处。
Q8–Q9: 基于时间的趋势分析
将匹配项按时间段聚合,以揭示峰值、回落或重复模式。
综合来看,这些查询全面模拟了日志分析中的典型任务,涵盖从选择性日志检索到大规模分析搜索。
硬件和系统版本
两个系统都在相同且独立的单节点环境中进行了基准测试,以确保进行公平的同类比较。每个引擎都在其各自的专用 EC2 实例上运行,并采用相同的 CPU、内存和存储配置。

系统配置
ClickHouse
ClickHouse 使用了一个标准的 MergeTree 表,其 OpenTelemetry 日志 模式 包含了时间戳、数值、字符串和映射的原生数据类型。该表按以下方式 排序:
(ServiceName, Timestamp)此排序键提高了针对按服务和时间范围过滤的常见日志分析查询的数据局部性,同时还改进了压缩。
在 Body 列上 创建了一个 全文索引。
Elasticsearch
Elasticsearch 使用了一个等效的 索引映射,具有相同的逻辑模式和匹配的 物理排序顺序:
index.sort = (ServiceName ASC, Timestamp ASC)主要映射选择:
Body 映射为 text 类型并使用标准分析器(支持全文搜索);
结构化字符串维度映射为 keyword 类型;
类 Map 的属性字段映射为 flattened 类型;
TraceFlags 和 SeverityNumber 映射为 byte 类型;
启用 codec: best_compression 以最小化磁盘占用。
在 Elasticsearch 允许的最大范围内,此配置尽可能地复刻了 ClickHouse 的语义,同时遵循了存储最佳实践。
为了确保稳定的单节点性能,我们使用了这些 JVM 和 OS 设置:
堆内存固定为 30 GiB (-Xms30g -Xmx30g) 以保留 CompressedOops;
bootstrap.memory_lock: true;
vm.max_map_count=262144。
分片布局
该基准测试使用了单节点存储优化布局,两个系统中均无副本。
针对每个数据集,ClickHouse 使用了单个分片(即单表),而 Elasticsearch 则采用了多个分片,这遵循了实现最佳分片大小的行业最佳实践(每个分片 50GB)。
在测量之前,所有 Elasticsearch 分片都依照最佳实践被强制合并,使每个分片只包含一个段。这不仅提升了存储效率,也不会阻碍并行搜索的执行,因为 Lucene 在查询时仍能逻辑上对单个段进行分区。
数据加载
ClickHouse 通过其原生的 Parquet 摄入能力直接加载了 Parquet 文件。
Elasticsearch 不原生支持读取 Parquet 文件,因此数据需要从 Parquet 文件中进行流式传输,转换为 NDJSON 格式,然后通过 Bulk API 摄入。
关于数据摄入的简要说明: 本文侧重于分析性日志搜索性能,因此我们没有进行全面、系统的摄入基准测试。然而,在数据集准备阶段,将 50B OTel 日志记录加载到单节点 ClickHouse 实例中,开箱即用不到 4 小时。对于类似的单节点 Elasticsearch 配置,我们需要调整摄入管道和相关设置才能达到可接受的吞吐量,即便如此,完成同样的数据加载也耗费了数天(大约 5 天)。
数据摄入吞吐量是可观测性系统在生产环境中需要重点关注的关键问题,因此我们可能会在专门的后续基准测试中,针对 OTel 日志摄入方面进行深入探讨。
在数据成功加载到两个系统后,接下来,我们将介绍用于公平比较查询性能的方法。
方法论
为真实反映可观测性工作流的场景,我们对两个系统分别在冷启动和热启动两种条件下进行了基准测试。
冷启动运行 (Cold runs) 模拟对以前从未查询过的时间范围进行的首次查询,此时所需的日志数据必须从磁盘加载。
热启动运行 (Hot runs) 模拟当相同数据已被缓存后进行的重复执行。
本基准测试中考虑的缓存层级
有三个缓存层可能影响查询延迟:
以下是您的翻译内容:
Linux 页缓存。这是操作系统的文件缓存,旨在避免从磁盘重复读取数据。
过滤器评估缓存。这些是引擎级别的缓存,用于记住先前的条件或过滤器结果,以加速重复的筛选工作。
ClickHouse: 查询条件缓存(https://clickhouse.com/docs/operations/query-condition-cache);
Elasticsearch: 节点查询缓存(https://www.elastic.co/docs/reference/elasticsearch/configuration-reference/node-query-cache-settings);
全查询结果缓存。这些缓存用于存储针对相同重复查询的完整响应。
ClickHouse: 查询缓存(https://clickhouse.com/docs/operations/query-cache);
Elasticsearch: 分片请求缓存(https://www.elastic.co/docs/reference/elasticsearch/rest-apis/shard-request-cache)。
为了专注于核心执行性能,我们在基准测试期间禁用了全查询结果缓存。否则,我们测量的将主要是重复的内存结果查找速度,这在此并非我们关注的重点。然而,我们保持过滤器评估缓存处于启用状态,因为它们是引擎正常执行路径的一部分。
测量冷运行
对于冷运行,我们首先完全关闭两个系统,清空 Linux 页缓存,然后重启服务器,在此之后才执行查询。
这意味着:
没有数据页被缓存在内存中;
引擎必须从磁盘加载所需数据;
运行时反映了存储效率、剪枝能力以及原始执行速度。
OTel 日志查询套件中的每个查询都在这些冷启动条件下执行,而报告的冷运行总计则是所有单个查询运行时间的总和。
测量热运行
在热运行测试中,系统在各次执行之间保持运行状态,并且没有清空 Linux 页缓存。
对于每个查询:
相同的查询会连续执行三次;
全查询结果缓存保持禁用状态;
过滤器评估缓存保持启用状态;
三次运行中最快的一次被记录为热运行结果。
这种方式可以隔离重复查询的性能,同时又不允许完整的查询结果重用。
OTel 日志查询套件中的每个查询都在这些条件下进行测量,而报告的热运行总计则是所有单个查询运行时间的总和。
Elasticsearch Query DSL 与 ES|QL
主要图表中的 Elasticsearch 结果均采用 Query DSL。我们还在 ES|QL 中实现了所有功能,但在测试中发现在其运行时间持续较慢,因此在整个主要基准测试中,Query DSL 被用作更可靠的 Elasticsearch 基线。
公共基准测试仓库中包含了 Query DSL 与 ES|QL 对应的冷启动和热启动的查询性能对比图。
在确定了基准测试方法后,我们将深入探讨这两个系统如何在磁盘上存储 OTel 日志。这种磁盘布局是理解后续结果的关键背景信息。
OTel 日志在磁盘上的存储方式
为了更好地理解下一节中的存储占用空间结果,我们首先审视 Elasticsearch 和 ClickHouse 如何在磁盘上存储和压缩已摄入的 OTel 日志。以下图表提供了一个简化示意图。
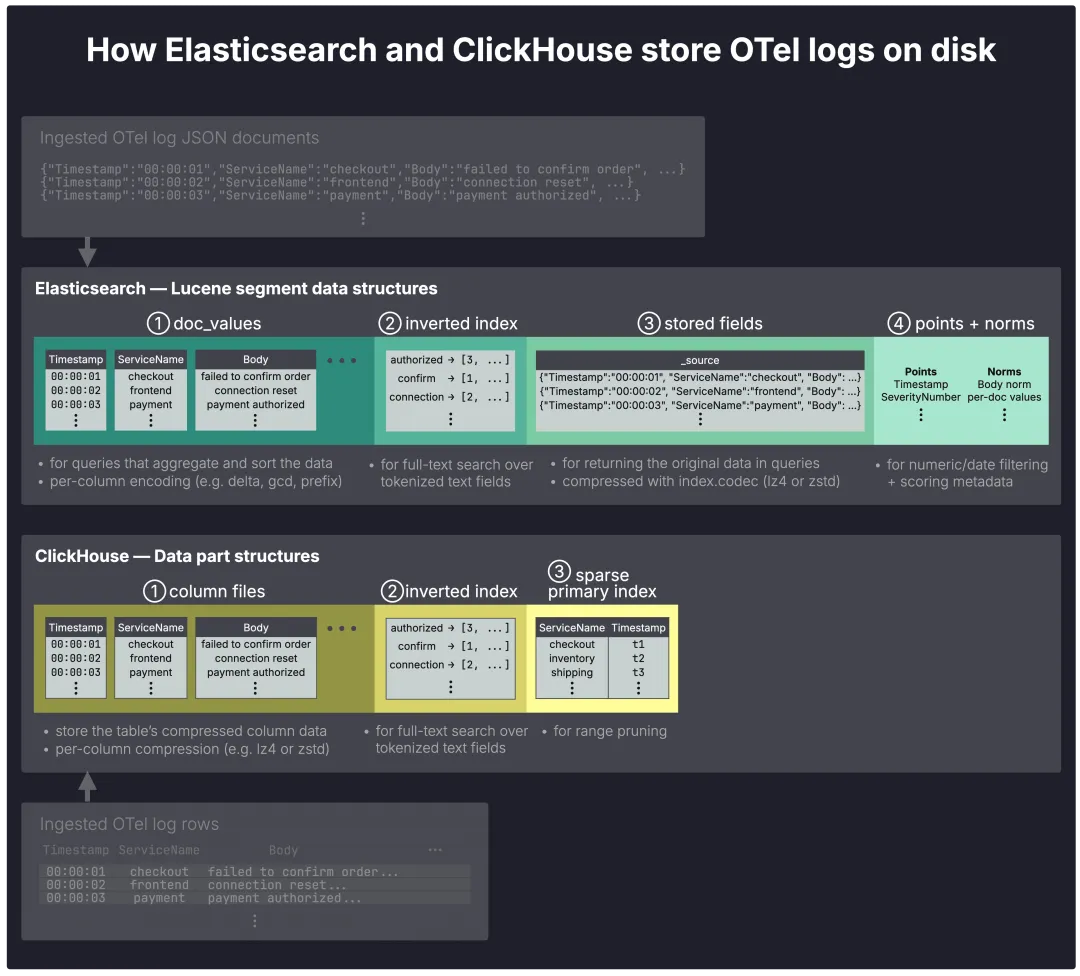
在这两个系统中,已摄入的 OTel 日志数据最终都会被写入不可变的磁盘存储单元:
Elasticsearch 中的 Lucene segments;
ClickHouse 中的 data parts。
这些单元在逻辑上属于分片(图中未显示),并在后台持续合并成更大的存储单元。通常,Segments 会增长到大约 5 GB,parts 则增长到大约 150 GB,尽管这两个系统都支持更大规模的强制合并。
在 Elasticsearch 中,分片进而组成了索引,详细信息可参见此处(https://github.com/ClickHouse/examples/tree/main/blog-examples/clickhouse-vs-elasticsearch/on-disk-format-and-insert-processing#elasticsearch);ClickHouse 分片的描述可参见此处(https://github.com/ClickHouse/examples/tree/main/blog-examples/clickhouse-vs-elasticsearch/on-disk-format-and-insert-processing#clickhouse)。
在这些磁盘存储单元内部,两个系统都将数据组织成专门的数据结构,主要用于实现四项功能:快速聚合、全文搜索、返回原始文档,以及在查询执行期间剪除不相关数据。
用于快速聚合的列式存储
两个系统都使用列式存储 (columnar storage):聚合查询仅读取所引用的列,由于每列均经过压缩,因此扫描的字节数更少,并能在连续数据上执行向量化 (SIMD) 操作。在 Elasticsearch 的 doc_values(https://www.elastic.co/docs/reference/elasticsearch/mapping-reference/doc-values) 中,每列都会根据其数据类型和基数,自动使用 delta 和 gcd 等专用编解码器进行单独编码。然而,它并未应用 lz4 或 zstd 等通用压缩算法。
在 ClickHouse 中,压缩编解码器也会应用于每个 列文件。ClickHouse 支持通用 (general-purpose) (例如 lz4 和 zstd)、专用 (specialized)(例如 delta 和 gcd) 和加密 (encryption) 编解码器 (例如 AES_128),并且这些编解码器可以按列进行链式组合 (chained) 使用。
全文搜索的倒排索引
两个系统都使用倒排索引 (inverted index) 作为全文搜索的基本数据结构。
存储字段和 _source
在 Elasticsearch 中,存储字段 (stored fields)用作文档存储,用于在查询响应中返回原始字段值。默认情况下,它们还会存储 _source,其中包含原始摄入的 JSON 文档。存储字段的压缩算法由 index.codec 设置定义:默认情况下为 lz4,若追求更高的压缩率,也可选用 zstd,但其性能会相对较慢。
为什么日志数据需要 _source
对于日志分析而言,返回原始摄入文档通常至关重要。在 Elasticsearch OSS 中,这使得在实践中很难避免使用 _source;而企业版则可以使用 合成 _source (synthetic _source)(https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-source-field.html#synthetic-source)。
在 ClickHouse 中,没有独立的等效结构:原始行直接从存储在列文件中的值重建。
稀疏索引用于剪枝 (Pruning)
ClickHouse 使用稀疏索引:由于 OTel 日志记录在磁盘上以排序顺序存储,引擎可以将它们分组到块中,并在 ③ 稀疏主索引 (sparse primary index)中记录每个块的值范围,从而跳过完全超出请求范围的块。
Lucene 具有针对排序数据的相关稀疏索引能力,但 Elasticsearch 在用于本次比较的 _disk_usage 输出中,并未将其作为单独的存储类别暴露出来。
还需要注意的是,在 Elasticsearch 中,倒排索引 (inverted index) 不仅用于全文搜索 (full-text search)。对于除 Body 之外的所有字符串字段,我们使用了 keyword 类型,而 Timestamp 使用 date 类型,数字字段则使用 numeric 类型。所有这些类型默认情况下也会为精确匹配过滤 (exact-match filtering) 填充倒排索引,其值按原样索引且不进行分析 (analysis)。这意味着对这些字段的过滤可以通过倒排索引高效地解决,使其成为本次比较中与 ClickHouse 稀疏主索引最接近的对应物。
用于过滤和评分的点 (Points) 和范数 (norms)
在 Elasticsearch 中,④ 点 (points) 支持对数字和日期字段进行高效过滤和范围查询,而 范数 (norms) 则存储每个文档的评分因子以衡量文本相关性。
ClickHouse 不使用独立的评分结构:数值和日期过滤通过列式扫描,结合稀疏主索引和跳跃索引进行处理。ClickHouse 目前也不对全文搜索结果进行评分,这与我们当前的日志分析用例无关。
既然存储的基础组件已经明确,接下来我们将探讨它们对磁盘使用量的综合影响。
OTel 日志存储占用
上述存储结构解释了数据字节的存储方式。为了公平地比较整体占用空间,我们首先统一了最主要影响磁盘使用量的几个变量:
相同的磁盘排序顺序:数据在磁盘上按相同的键进行排序——在 ClickHouse 中通过排序键按 (ServiceName, Timestamp) 排序,在 Elasticsearch 中则通过在相同字段上的索引排序实现;
相同的压缩算法:存储原始日志内容的核心结构使用相同的压缩算法。具体来说,ClickHouse 列文件和 Elasticsearch 存储字段均采用 ZSTD;
相同的全文倒排索引范围:两个系统都仅在 Body 字段上构建全文倒排索引。在 Elasticsearch 中,所有其他字符串字段都被映射为 keyword 类型,这意味着它们支持精确匹配过滤,但不进行全文搜索分析。
最后,正如之前(https://clickhouse.com/blog/elasticsearch-log-analytics-clickhouse#shard-layout)所述,本次比较采用了存储优化的单节点配置:两个系统中均无副本;ClickHouse 使用一个分片,而 Elasticsearch 则采用多个分片,同时遵循最佳实践以实现最优分片大小(每个分片 50GB),并且强制合并为每个分片一个段。
考虑到以上因素,下方的图表展示了两个系统在存储 10 亿、100 亿和 500 亿条 OTel 日志记录时的存储占用情况。
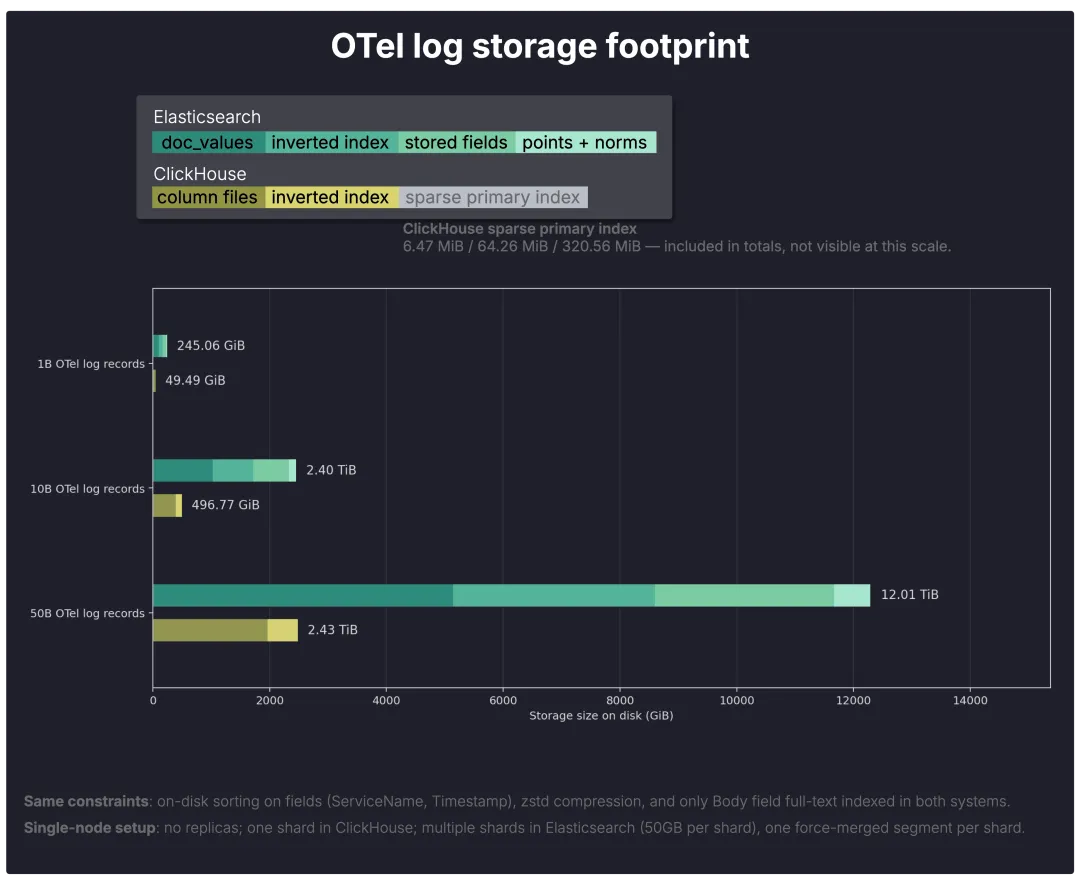
为了便于解读总体数据,图表将这些数据细分为上一节介绍的各个磁盘上的数据结构。图例将每个彩色区域映射到其在 Elasticsearch 和 ClickHouse 中对应的结构,而这些底层数据的大小则分别取自 Elasticsearch 的 _disk_usage API 和 ClickHouse 的 parts system table。
注:ClickHouse 的稀疏主索引 (sparse primary index) 已计入总数,但在此规模下并不明显 (6.47 MiB / 64.26 MiB/ 320.56 MiB。
总体存储空间占用
总体而言,ClickHouse 存储相同 OTel 日志数据所需的空间约为 Elasticsearch 的五分之一。
这一结论在所有这三个规模下均保持一致。
1B: ClickHouse 49.49 GiB 对比 Elasticsearch 245.06 GiB → ClickHouse 空间占用约为 Elasticsearch 的 1/4.95;
10B: ClickHouse 496.84 GiB 对比 Elasticsearch 2.40 TiB → ClickHouse 空间占用约为 Elasticsearch 的 1/4.95;
50B: ClickHouse 2.43 TiB 对比 Elasticsearch 12.01 TiB→ ClickHouse 空间占用约为 Elasticsearch 的 1/4.95。
列式存储空间占用
主要列式存储结构本身就存在巨大差异。仅 Elasticsearch 的 doc_values 所占用的空间就远超 ClickHouse 的列文件。
1B: ClickHouse 39.33 GiB 对比 Elasticsearch 102.49 GiB → ClickHouse 存储空间仅为 Elasticsearch 的 1/2.61;
10B: ClickHouse 393.54 GiB 对比 Elasticsearch 1.00 TiB → ClickHouse 存储空间仅为 Elasticsearch 的 1/2.61;
50B: ClickHouse 1.92 TiB 对比 Elasticsearch 5.02 TiB → ClickHouse 存储空间仅为 Elasticsearch 的 1/2.61。
值得一提的是,ClickHouse 在其列文件中包含了所有的 OTel 日志字段,而数据集中最大的字段 Body 则被排除在 Elasticsearch 的 doc_values 之外。这是因为 Body 被映射为 text 类型,因此仅存储在倒排索引中。
ClickHouse 的压缩效率
这已经揭示了整体存储差距的主要原因:ClickHouse 对其列文件进行了极致高效的压缩。
1B: 未压缩 642.42 GiB → 已压缩 39.33 GiB→ 16.33 倍压缩比;
10B: 未压缩 6.26 TiB → 已压缩 393.54 GiB→ 16.29 倍压缩比;
50B: 未压缩 31.31 TiB → 已压缩 1.92 TiB→ 16.29 倍压缩比。
请注意,当专门针对压缩优化数据类型和数据在磁盘上的存储顺序时,可以实现更高的压缩比。例如,在一个 Nginx 日志案例中,ClickHouse 实现了高达 178 倍的压缩比。
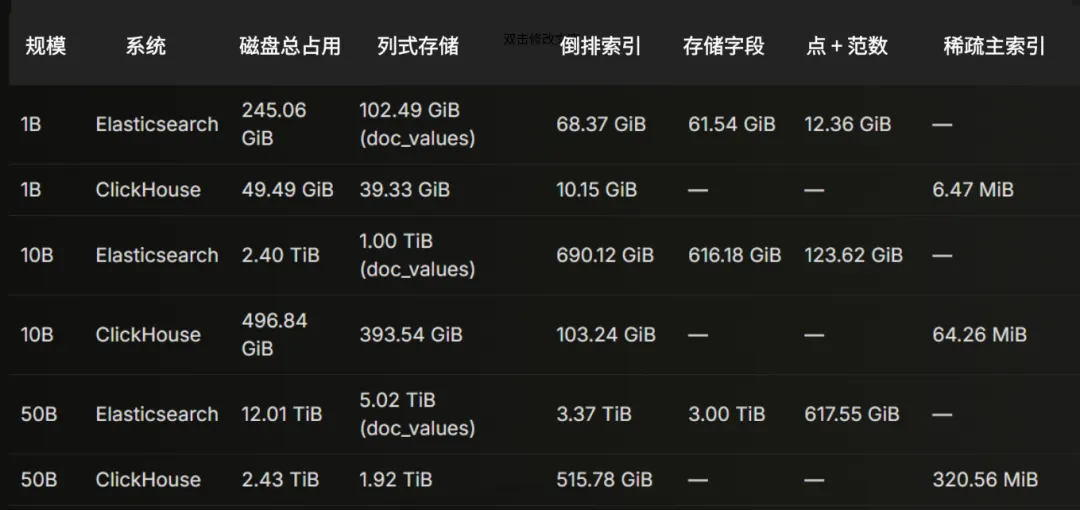
存储结构细分
下表汇总了在两种系统及全部三种规模下,不同数据结构在磁盘上的占用空间。
为什么 Elasticsearch 的存储占用更大
Elasticsearch 索引体积更大,部分原因在于它支持更广泛的搜索功能,例如短语查询、模糊匹配、通配符搜索以及与排名相关的元数据。而本基准测试中的典型 OTel 日志分析查询通常不依赖这些功能。
为了测试这对存储消耗的影响程度,我们还运行了功能精简版的 Elasticsearch。
一个 中等程度的配置变体,通过禁用 norms (norms 参数设为 false) 并将主 Body 文本字段的 index_options 配置为仅文档级别的 postings (index_options set to docs),仅将总存储占用空间降低了 约 2%。
为了实现更大的存储空间缩减(磁盘占用减少约 20%,但仍比 ClickHouse 大 4 倍),需要在额外字段上更 激进地禁用索引功能 (index 参数设为 false)。然而,由此生成的配置不再代表典型的 Elasticsearch 日志部署场景(例如,除了我们的查询套件引用的一小部分字段外,在大多数 OTel 字段上执行过滤操作都会变得慢得多)。
在这两种情况下,总查询运行时长仅发生了 微小变化。关于 Query DSL 和 ESQL 在热/冷两种情况下的运行时长,更多图表可在我们的 GitHub 仓库 [此处]查看。
存储之外的更多优势
更精简的占用空间使 ClickHouse 在大规模日志分析方面相比 Elasticsearch 具有多项优势:
更低的存储成本。 以更小的存储空间存储相同的 OTel 日志数据,直接降低了在线保存海量日志数据的成本;
更低的查询 I/O。 磁盘上更少的数据量意味着在扫描、过滤和聚合过程中需要读取的数据更少,这部分解释了下一节中展示的运行时性能提升;
更大的数据摄入能力。 更小的磁盘数据结构减轻了存储子系统的压力,为现代可观测性管道中典型的持续写入吞吐量提供了更大的余量。这与上文提到的数据摄入案例相符,在 ClickHouse 中,500 亿行数据的加载远快于预期。
此外,ClickHouse OSS 开箱即用地支持其原生 MergeTree 引擎的 S3 后端存储,这进一步增强了上述效果,使得在线保存海量原始日志数据的成本效益显著提升。
OTel 日志查询运行时
我们首先分析冷启动的总运行时间,然后深入研究每个查询的详细数据以进行解释。最后,我们考察热运行阶段,以了解数据被缓存后性能如何变化。
总冷启动运行时间
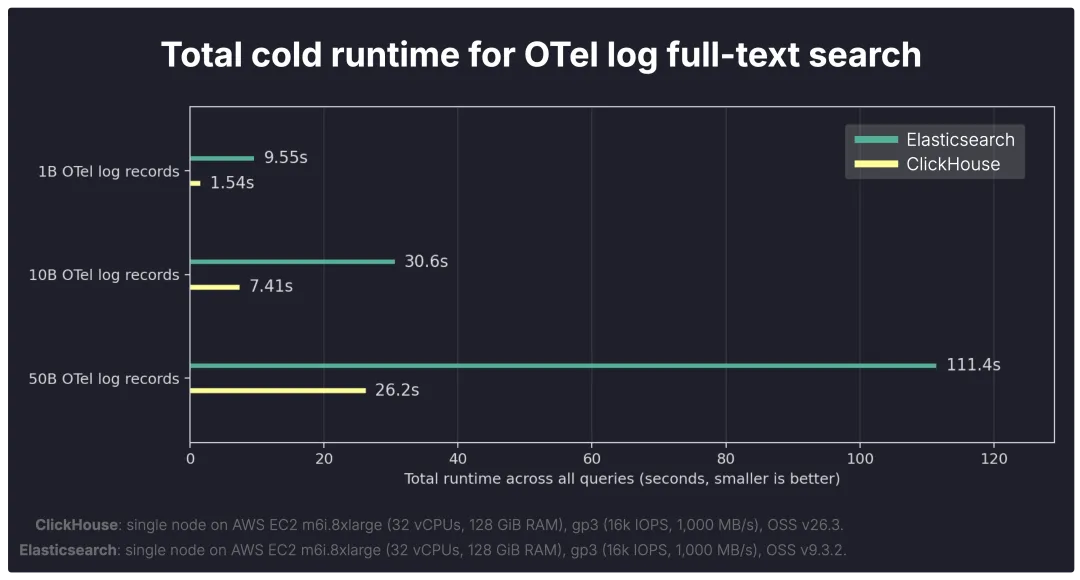
下面的图表展示了在包含 10 亿、100 亿和 500 亿条存储记录的数据集上,完整的 OTel 日志查询套件的总冷启动运行时间。
值得注意的是,该测试套件反映了 Kibana 或 ClickStack 等工具中典型的日志分析工作负载,它将全文搜索与聚合和过滤结合起来,用于调查事件、错误和趋势。
如前所述,在冷运行测试中,我们会先完全关闭两个系统,清空 Linux 页缓存,然后重新启动系统,最后再执行查询。这样测得的是没有任何数据缓存时的执行耗时,也就是查询引擎必须从磁盘加载所需数据时的表现。
OTel 日志查询集合中的每个查询都会在这种冷启动条件下执行,上图汇总了所有查询各自的执行耗时。
冷查询在可观测性中并非罕见。
工程师经常需要调查新出现的事件、查看此前从未涉足的时间范围,或者检索较早的留存日志。在这些场景下,我们无法指望存在热缓存。
总体而言,在所有三个规模上,ClickHouse 完成完整的冷查询测试都比 Elasticsearch 快得多。
10 亿条数据 (1B): ClickHouse 1.54s vs Elasticsearch 9.55s→ ClickHouse 快 6.20 倍;
100 亿条数据 (10B): ClickHouse 7.41s vs Elasticsearch 30.6s→ ClickHouse 快 4.13 倍;
500 亿条数据 (50B): ClickHouse 26.2s vs Elasticsearch 111.4s→ ClickHouse 快 4.25 倍。
那么,这种领先优势究竟源自何处?接下来,我们将按查询类型细分总体的运行时数据。
按查询类型划分的冷查询运行时:ClickHouse 优势最明显之处
从逐个查询的细分结果来看,ClickHouse 在冷查询场景下的最大性能提升,体现在那些将全文过滤 (full-text filtering) 与更繁重的后续聚合操作相结合的查询上。
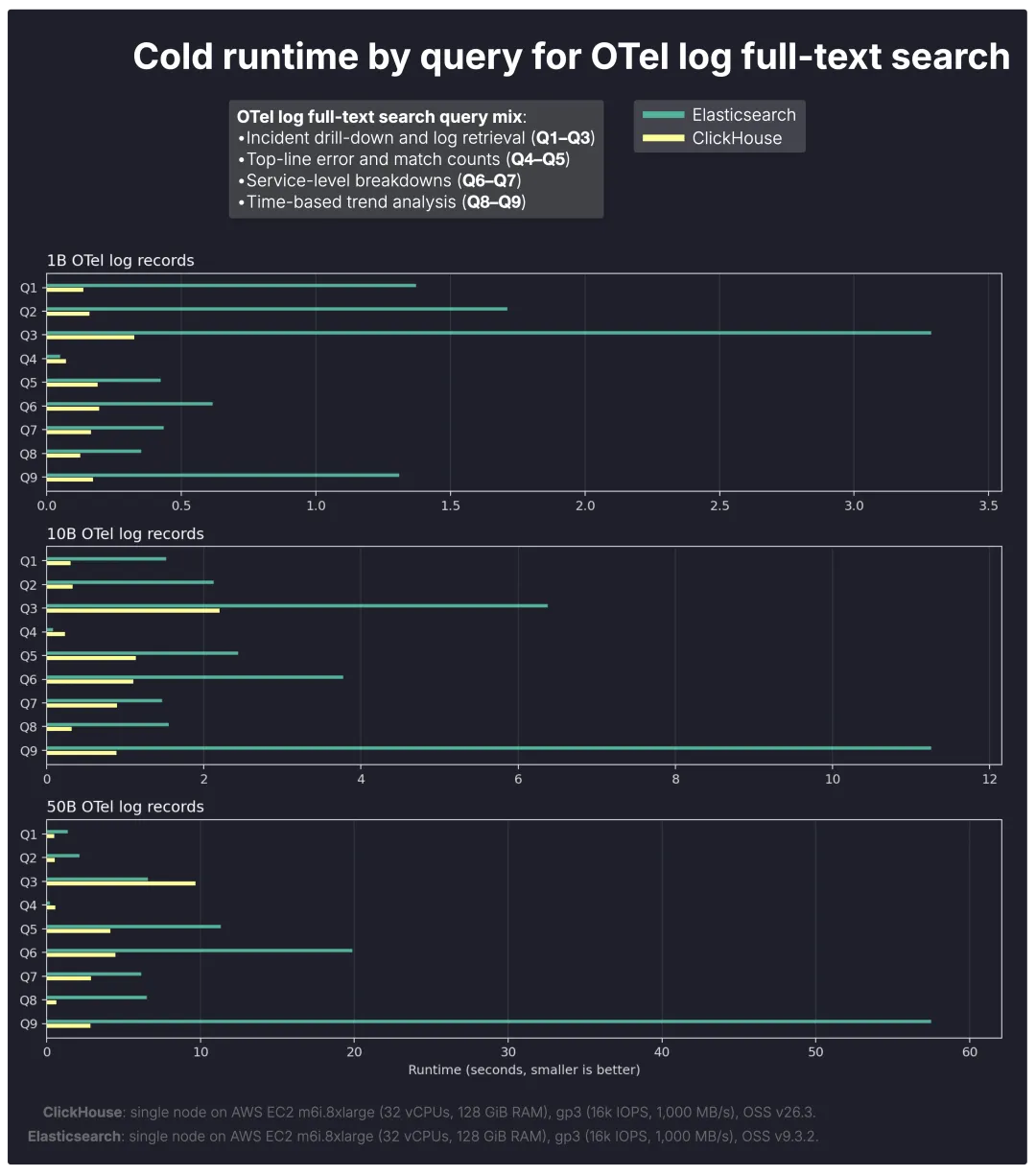
总体来看,工作负载越是从纯粹的数据检索转向搜索加分析(这在典型的日志分析查询中尤为常见),ClickHouse 的优势就越发明显。
Q8–Q9 趋势分析查询 在较大规模下展现出最大的性能差距,这类查询需要将大量匹配行按时间段分组并计数;
Q6–Q7 服务分解查询 的差距也随着规模的增长而显著扩大,这反映了对大型结果集执行多组聚合操作的需求;
Q1–Q3 事件下钻查询 的性能表现相对接近,因为它们更侧重于数据检索,并且涉及较少的过滤后聚合操作。
这与我们早前进行的基准测试结果保持一致(这些基准测试针对 聚合操作和 JSON 分析),ClickHouse 在大规模 GROUP BY 和计数工作负载上显著优于 Elasticsearch。在此次测试中,一旦文本匹配完成,ClickHouse 在聚合方面的这些优势依然显著。
冷启动测试旨在衡量存储效率和纯粹的执行速度。然而,可观测性工作负载通常涉及对热数据的重复查询,因此我们接下来将比较系统的热运行表现。
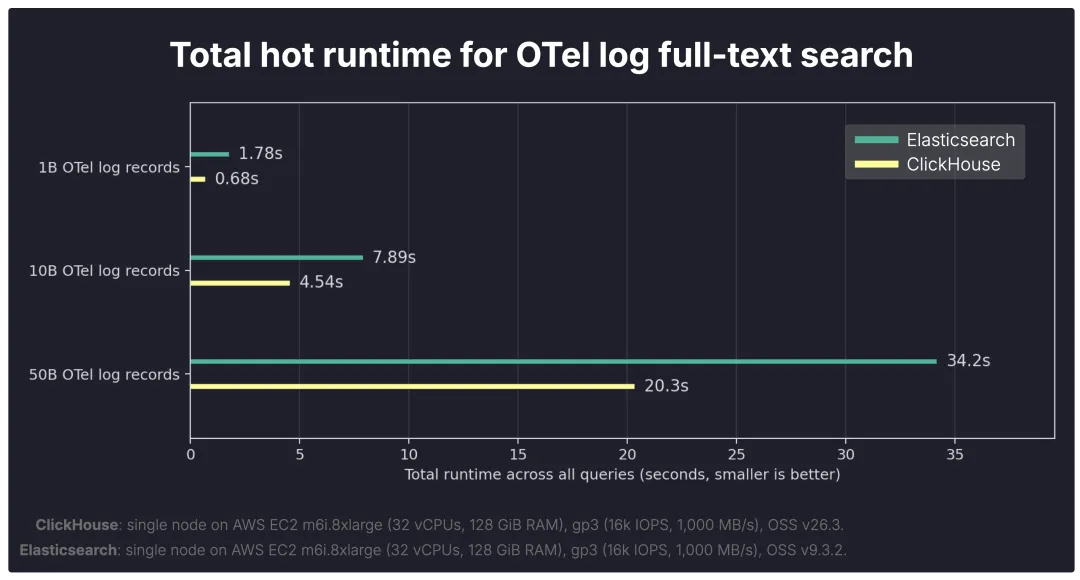
总热运行时间
下图展示了在包含 10 亿、100 亿和 500 亿条存储记录的数据集上,运行 完整 OTel 日志查询套件 所需的总热运行时间。
需要注意的是,与之前的冷启动测试不同,热启动测试是指在多次执行之间系统保持运行状态,因此 Linux 页缓存持续可用。对于每个查询,我们连续执行三次相同的查询。在此过程中,两个系统的 查询结果缓存都被禁用,但其对应的 过滤器评估缓存保持启用。最终,我们取三次运行中最快的一次作为热启动结果。
OTel 日志查询套件中的每个查询都在这些条件下进行了测量,上图汇总了由此产生的每个查询的运行时间总和。
热查询在可观测性领域同样至关重要。
仪表盘会自动刷新,故障排查会重新应用相似的过滤器,并且交互式下钻操作也常常会重复访问相同的数据集。
在暖缓存条件下,两者之间的差距有所缩小,但 ClickHouse 在所有规模下完成整个查询套件的速度依然快于 Elasticsearch。
1B: ClickHouse 0.68s vs Elasticsearch 1.78s→ ClickHouse 快 2.62 倍;
10B: ClickHouse 4.54s vs Elasticsearch 7.89s→ ClickHouse 快 1.74 倍;
50B: ClickHouse 20.3s vs Elasticsearch 34.2s→ ClickHouse 快 1.69 倍。
为理解其原因,我们再次按查询类型对结果进行细分。
查询热运行时表现:缓存缩小了差距,但效果并非统一
在缓存预热后,部分查询性能差距显著缩小,但按查询类型细分结果显示,缓存并未完全消除两个系统之间潜在的执行模型差异。
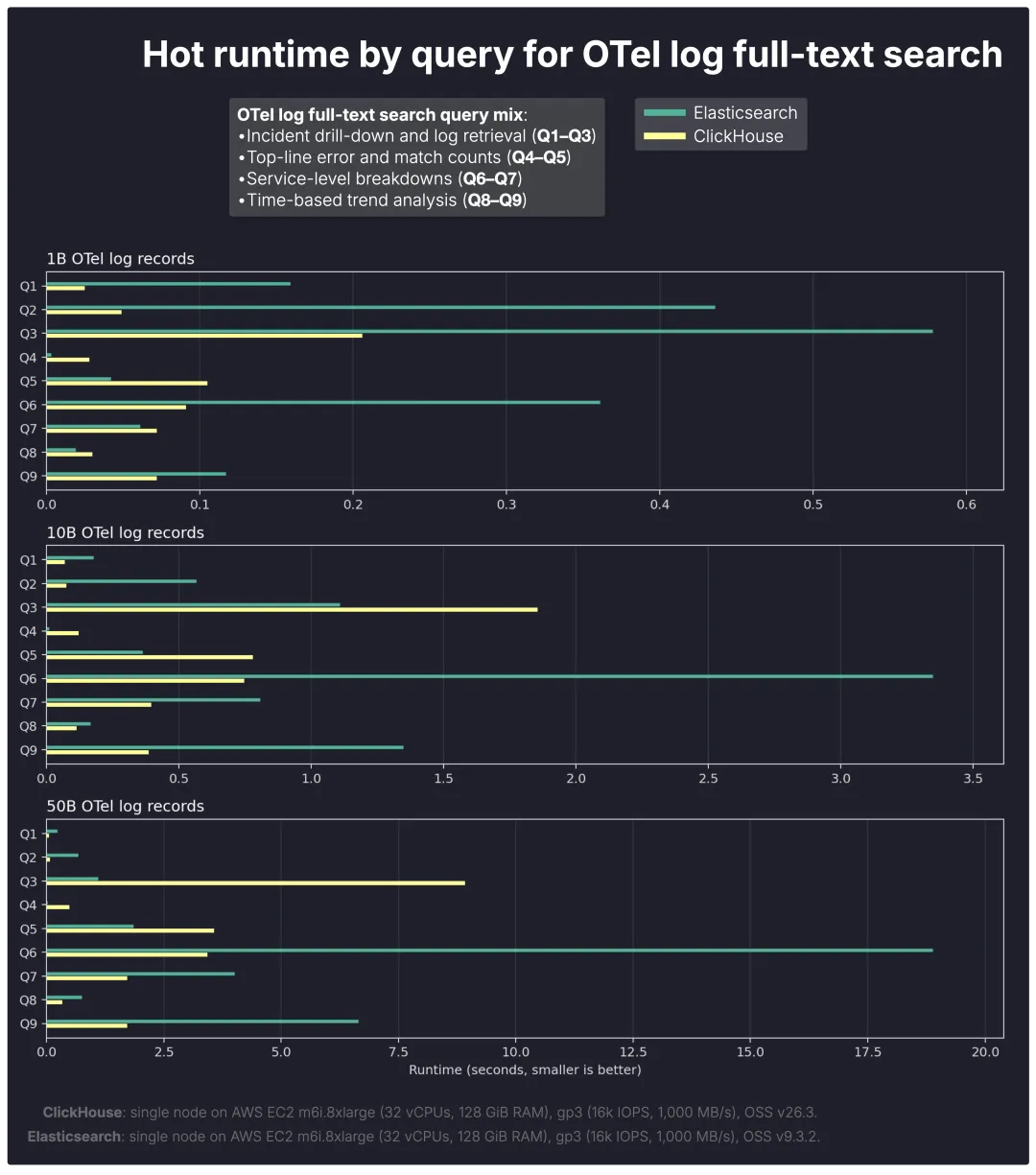
总体而言,缓存缩小了检索密集型查询的性能差距,但对搜索与分析工作负载则不然,在这类场景中,下游聚合操作仍然占据主导地位。
Q1–Q3 事件钻取查询 在热执行条件下表现更为接近,这与两个系统均受益于缓存谓词(predicate)评估的特点相符。
尽管如此,等效缓存在粒度上并非完全相同:Elasticsearch 缓存的是哪些文档此前匹配了过滤器,而 ClickHouse 则在 granules(行块)级别缓存过滤结果。因此,ClickHouse 可以快速跳过整个 granules,但仍需在剩余的 granules 中识别具体的匹配行。
Q6–Q9 服务分解和趋势分析查询 仍然展现出 ClickHouse 的明显优势,尤其是在大规模场景下,因为这些查询在识别出匹配行后,仍然需要在下游聚合操作中耗费大量时间。
在更大的规模下,Elasticsearch 细粒度过滤缓存带来的热运行性能优势似乎也会减弱。一个合理的解释是缓存压力增加:随着数据量和不同工作集的增多,文档级过滤结果的缓存保留效率可能降低,从而削弱了细粒度缓存的实际效益。
开源(OSS)比较已完成。接下来,我们快速了解 ClickHouse Cloud 如何简化相同工作负载的扩展。
额外内容:在 ClickHouse Cloud 中扩展相同工作负载
在许多分析工作负载中,物化视图 (materialized views)等技术可以预先聚合数据,从而减少查询需要扫描的数据量。
日志分析则有所不同。
在事件响应期间,工程师通常需要原始日志事件:搜索错误消息、检查相关日志、定位受影响的主机、按服务细分结果,并根据新的过滤条件反复进行透视分析。这使得激进的预聚合策略在传统 BI (Business Intelligence) 工作负载中的效用大打折扣。
当原始数据仍需被查询时,提升查询速度的实用方法很简单:增加更多计算资源。
在 ClickHouse Cloud 中,计算与存储是分离的,因此新增的副本节点(复制的是计算能力,而非数据)无需预先重排数据即可即时加入。所有节点都从相同的共享对象存储中读取数据。
并行副本 (Parallel replicas)通过将数据读取分布到副本节点集群中,使得查询执行能够实现 横向扩展 (scale horizontally)。
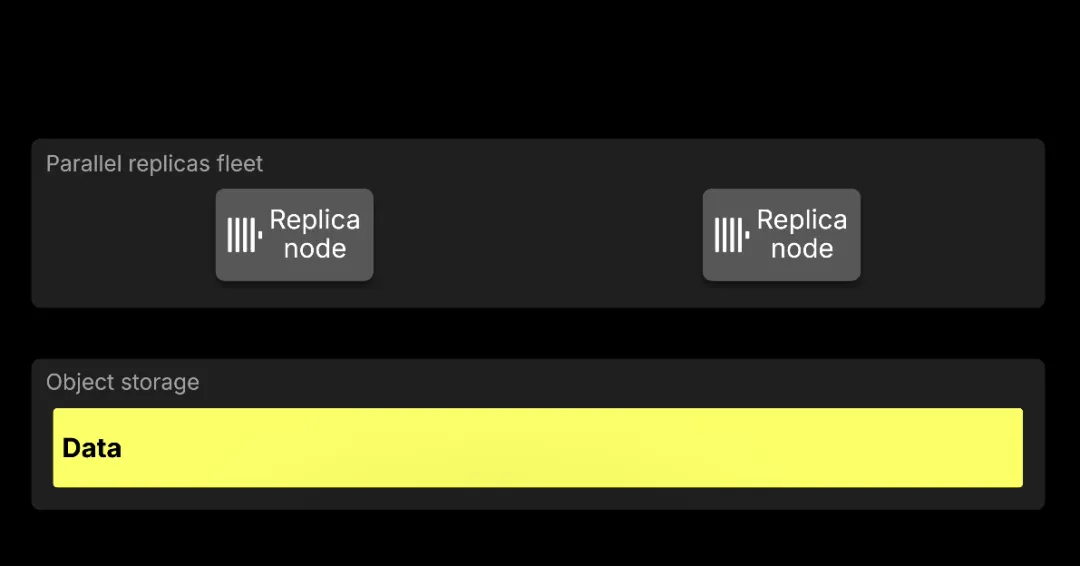
随着更多节点参与,相同的查询可以在更多机器上并行执行,从而缩短运行时间。下图展示了这对 500 亿行查询套件的影响。
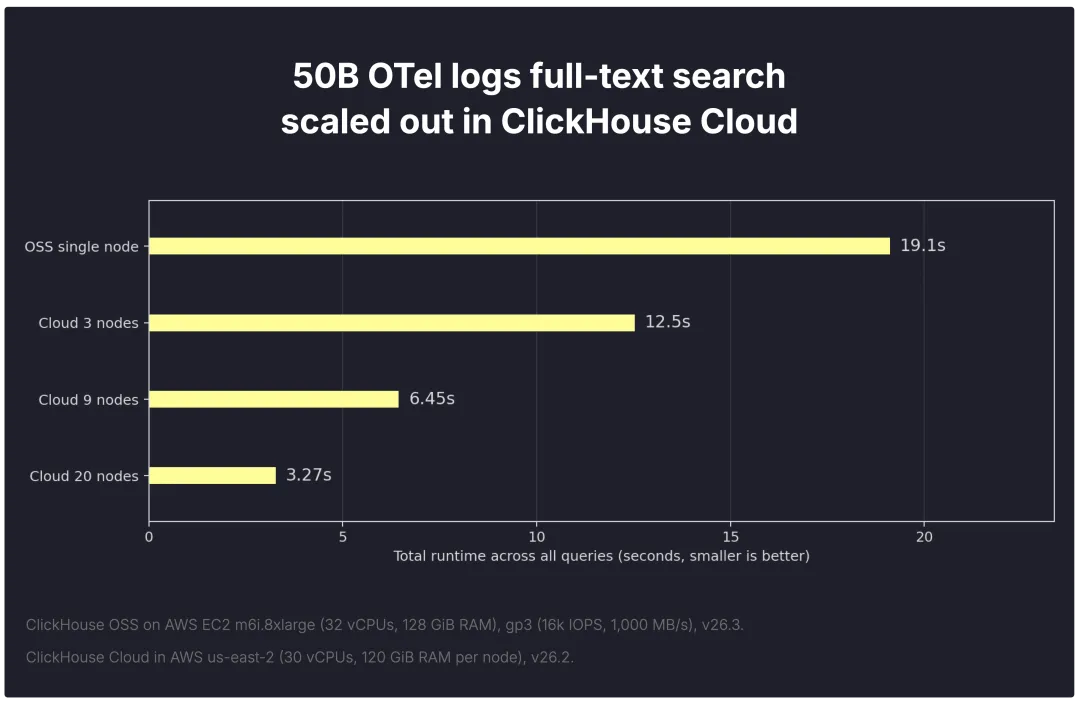
相比于 OSS 单节点基准线 (19.1s),相同的工作负载在 3 个节点上可降至 12.5s,在 9 个节点上降至 6.45s,在 20 个节点上降至 3.27s。实际效果是,无论是人工探索 ClickStack 仪表板,还是代理循环查询日志,日志搜索和分析都感觉更具交互性。
引入 索引分片 (index sharding) 后,这一优势将更加显著。正如存储部分所展示的,针对 50 亿行 OTel 数据集的全文索引已达到约 0.5 TiB (515.78 GiB)。索引分片将该索引的分析任务分散到整个副本集群 (replica fleet) 中,其方式与并行副本 (parallel replicas) 分散数据读取的方式如出一辙。
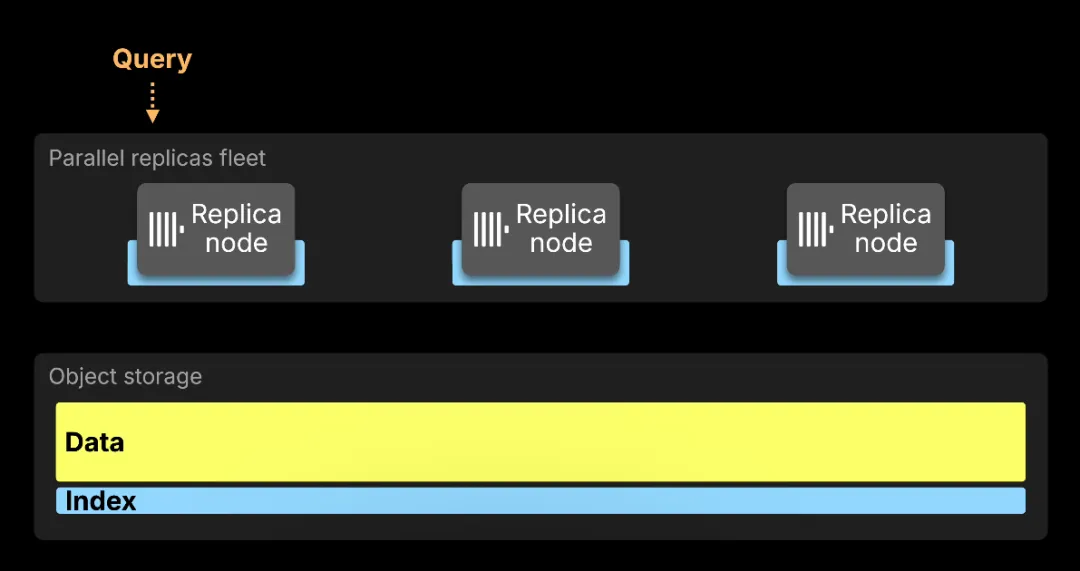
对于一个 50 亿行的数据表,ClickHouse 经 测定,全文索引分析获得了 5.8 倍的加速。
云端横向扩展 (Cloud scale-out) 是一个额外优势。即便没有它,单节点 OSS 基准测试也已清楚地说明了问题。
全貌
这次基准测试完善了全貌:首先,ClickHouse 在聚合 (aggregations) 方面击败了 Elasticsearch;接着,在 JSON 分析方面也取得了胜利;现在,它又在全文分析搜索方面表现出色。
ClickHouse 现在不仅支持搜索功能,而且依然保持其世界级的聚合引擎。
ClickHouse 全文搜索功能专为分析和可观测性 (observability) 而设计,支持对数十亿乃至数万亿行数据进行快速的多令牌搜索和聚合 (aggregations)。
这项基准测试证实:在高达 500 亿行 的真实 OpenTelemetry 日志工作负载中,ClickHouse 始终展现出更优异的整体表现。
存储占用大幅减少 — 磁盘空间减少约 5 倍,这意味着更低的存储成本、更低的查询 I/O,并为持续数据摄入提供更大空间;
冷查询速度显著提升 — 当数据需要从磁盘读取时,速度提升 4 到 6 倍。这一点至关重要,鉴于冷查询在可观测性 (Observability) 领域是常态;
热查询速度更快 — 在缓存预热的情况下,速度仍快约 1.7 到 2.6 倍,确保仪表板、向下钻取 (drill-down) 和重复分析保持响应。
性能差距最大的情况出现在那些结合了文本搜索、分组、计数和时间序列分析的工作负载中。
在可观测性 (Observability) 领域,搜索通常并非查询的最终目的。
/END/
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。






