术语定义
术语 英文 解释 哈希算法 hash algorithm 是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值。 哈希表 hash table 根据设定的哈希函数 H(key) 和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。 ## 线程不安全的 HashMap
因为多线程环境下,使用 HashMap 进行 put 操作会引起死循环,导致 CPU 利用率接近 100%,所以在并发情况下不能使用 HashMap,如以下代码
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
t.join();
效率低下的 HashTable 容器
HashTable 容器使用 synchronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为当一个线程访问 HashTable 的同步方法时,其他线程访问 HashTable 的同步方法时,可能会进入阻塞或轮询状态。如线程 1 使用 put 进行添加元素,线程 2 不但不能使用 put 方法添加元素,并且也不能使用 get 方法来获取元素,所以竞争越激烈效率越低。
锁分段技术
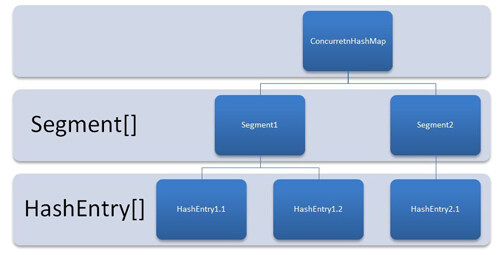
HashTable 容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问 HashTable 的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是 ConcurrentHashMap 所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap 的结构
我们通过 ConcurrentHashMap 的类图来分析 ConcurrentHashMap 的结构。
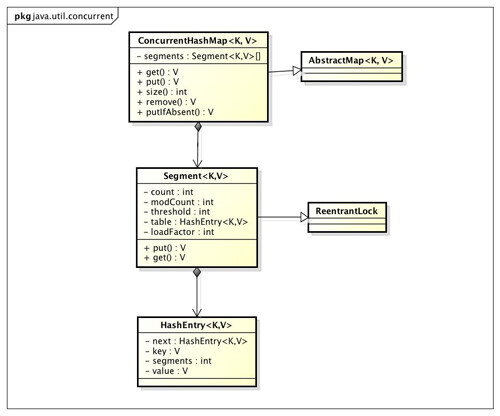
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 是一种可重入锁 ReentrantLock,在 ConcurrentHashMap 里扮演锁的角色,HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的结构和 HashMap 类似,是一种数组和链表结构, 一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素, 每个 Segment 守护者一个 HashEntry 数组里的元素, 当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
ConcurrentHashMap 的初始化
ConcurrentHashMap 初始化方法是通过 initialCapacity,loadFactor, concurrencyLevel 几个参数来初始化 segments 数组,段偏移量 segmentShift,段掩码 segmentMask 和每个 segment 里的 HashEntry 数组 。
初始化 segments 数组。让我们来看一下初始化 segmentShift,segmentMask 和 segments 数组的源代码。
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
由上面的代码可知 segments 数组的长度 ssize 通过 concurrencyLevel 计算得出。为了能通过按位与的哈希算法来定位 segments 数组的索引,必须保证 segments 数组的长度是 2 的 N 次方(power-of-two size),所以必须计算出一个是大于或等于 concurrencyLevel 的最小的 2 的 N 次方值来作为 segments 数组的长度。假如 concurrencyLevel 等于 14,15 或 16,ssize 都会等于 16,即容器里锁的个数也是 16。注意 concurrencyLevel 的最大大小是 65535,意味着 segments 数组的长度最大为 65536,对应的二进制是 16 位。
初始化 segmentShift 和 segmentMask。这两个全局变量在定位 segment 时的哈希算法里需要使用,sshift 等于 ssize 从 1 向左移位的次数,在默认情况下 concurrencyLevel 等于 16,1 需要向左移位移动 4 次,所以 sshift 等于 4。segmentShift 用于定位参与 hash 运算的位数,segmentShift 等于 32 减 sshift,所以等于 28,这里之所以用 32 是因为 ConcurrentHashMap 里的 hash() 方法输出的最大数是 32 位的,后面的测试中我们可以看到这点。segmentMask 是哈希运算的掩码,等于 ssize 减 1,即 15,掩码的二进制各个位的值都是 1。因为 ssize 的最大长度是 65536,所以 segmentShift 最大值是 16,segmentMask 最大值是 65535,对应的二进制是 16 位,每个位都是 1。
初始化每个 Segment。输入参数 initialCapacity 是 ConcurrentHashMap 的初始化容量,loadfactor 是每个 segment 的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个 segment。
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
上面代码中的变量 cap 就是 segment 里 HashEntry 数组的长度,它等于 initialCapacity 除以 ssize 的倍数 c,如果 c 大于 1,就会取大于等于 c 的 2 的 N 次方值,所以 cap 不是 1,就是 2 的 N 次方。segment 的容量 threshold=(int)cap*loadFactor,默认情况下 initialCapacity 等于 16,loadfactor 等于 0.75,通过运算 cap 等于 1,threshold 等于零。
定位 Segment
既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过哈希算法定位到 Segment。可以看到 ConcurrentHashMap 会首先使用 Wang/Jenkins hash 的变种算法对元素的 hashCode 进行一次再哈希。
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
之所以进行再哈希,其目的是为了减少哈希冲突,使元素能够均匀的分布在不同的 Segment 上,从而提高容器的存取效率。假如哈希的质量差到极点,那么所有的元素都在一个 Segment 中,不仅存取元素缓慢,分段锁也会失去意义。我做了一个测试,不通过再哈希而直接执行哈希计算。
System.out.println(Integer.parseInt("0001111", 2) & 15);
System.out.println(Integer.parseInt("0011111", 2) & 15);
System.out.println(Integer.parseInt("0111111", 2) & 15);
System.out.println(Integer.parseInt("1111111", 2) & 15);
计算后输出的哈希值全是 15,通过这个例子可以发现如果不进行再哈希,哈希冲突会非常严重,因为只要低位一样,无论高位是什么数,其哈希值总是一样。我们再把上面的二进制数据进行再哈希后结果如下,为了方便阅读,不足 32 位的高位补了 0,每隔四位用竖线分割下。
0100|0111|0110|0111|1101|1010|0100|1110
1111|0111|0100|0011|0000|0001|1011|1000
0111|0111|0110|1001|0100|0110|0011|1110
1000|0011|0000|0000|1100|1000|0001|1010
可以发现每一位的数据都散列开了,通过这种再哈希能让数字的每一位都能参加到哈希运算当中,从而减少哈希冲突。ConcurrentHashMap 通过以下哈希算法定位 segment。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
默认情况下 segmentShift 为 28,segmentMask 为 15,再哈希后的数最大是 32 位二进制数据,向右无符号移动 28 位,意思是让高 4 位参与到 hash 运算中, (hash >>> segmentShift) & segmentMask 的运算结果分别是 4,15,7 和 8,可以看到 hash 值没有发生冲突。
ConcurrentHashMap 的 get 操作
Segment 的 get 操作实现非常简单和高效。先经过一次再哈希,然后使用这个哈希值通过哈希运算定位到 segment,再通过哈希算法定位到元素,代码如下:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
get 操作的高效之处在于整个 get 过程不需要加锁,除非读到的值是空的才会加锁重读,我们知道 HashTable 容器的 get 方法是需要加锁的,那么 ConcurrentHashMap 的 get 操作是如何做到不加锁的呢?原因是它的 get 方法里将要使用的共享变量都定义成 volatile,如用于统计当前 Segement 大小的 count 字段和用于存储值的 HashEntry 的 value。定义成 volatile 的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在 get 操作里只需要读不需要写共享变量 count 和 value,所以可以不用加锁。之所以不会读到过期的值,是根据 java 内存模型的 happen before 原则,对 volatile 字段的写入操作先于读操作,即使两个线程同时修改和获取 volatile 变量,get 操作也能拿到最新的值,这是用 volatile 替换锁的经典应用场景。
transient volatile int count;
volatile V value;
在定位元素的代码里我们可以发现定位 HashEntry 和定位 Segment 的哈希算法虽然一样,都与数组的长度减去一相与,但是相与的值不一样,定位 Segment 使用的是元素的 hashcode 通过再哈希后得到的值的高位,而定位 HashEntry 直接使用的是再哈希后的值。其目的是避免两次哈希后的值一样,导致元素虽然在 Segment 里散列开了,但是却没有在 HashEntry 里散列开。
hash >>> segmentShift) & segmentMask// 定位 Segment 所使用的 hash 算法
int index = hash & (tab.length - 1);// 定位 HashEntry 所使用的 hash 算法
ConcurrentHashMap 的 Put 操作
由于 put 方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put 方法首先定位到 Segment,然后在 Segment 里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置然后放在 HashEntry 数组里。
是否需要扩容。在插入元素前会先判断 Segment 里的 HashEntry 数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment 的扩容判断比 HashMap 更恰当,因为 HashMap 是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时 HashMap 就进行了一次无效的扩容。
如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再 hash 后插入到新的数组里。为了高效 ConcurrentHashMap 不会对整个容器进行扩容,而只对某个 segment 进行扩容。
ConcurrentHashMap 的 size 操作
如果我们要统计整个 ConcurrentHashMap 里元素的大小,就必须统计所有 Segment 里元素的大小后求和。Segment 里的全局变量 count 是一个 volatile 变量,那么在多线程场景下,我们是不是直接把所有 Segment 的 count 相加就可以得到整个 ConcurrentHashMap 大小了呢?不是的,虽然相加时可以获取每个 Segment 的 count 的最新值,但是拿到之后可能累加前使用的 count 发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计 size 的时候把所有 Segment 的 put,remove 和 clean 方法全部锁住,但是这种做法显然非常低效。 因为在累加 count 操作过程中,之前累加过的 count 发生变化的几率非常小,所以 ConcurrentHashMap 的做法是先尝试 2 次通过不锁住 Segment 的方式来统计各个 Segment 大小,如果统计的过程中,容器的 count 发生了变化,则再采用加锁的方式来统计所有 Segment 的大小。
那么 ConcurrentHashMap 是如何判断在统计的时候容器是否发生了变化呢?使用 modCount 变量,在 put , remove 和 clean 方法里操作元素前都会将变量 modCount 进行加 1,那么在统计 size 前后比较 modCount 是否发生变化,从而得知容器的大小是否发生变化。
参考资料
- JDK1.6 源代码。
- 《Java 并发编程实践》。
- Java 并发编程之 ConcurrentHashMap 。
作者介绍
方腾飞,花名清英,淘宝资深开发工程师,关注并发编程,目前在广告技术部从事无线广告联盟的开发和设计工作。个人博客: http://ifeve.com 微博: http://weibo.com/kirals 欢迎通过我的微博进行技术交流。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




