
配置已经从静态的部署文件演变成了实时的控制平面,直接决定系统的行为。配置管理的演进揭示了为何错误配置会引发大规模的故障,以及超大规模云服务商如何通过分阶段发布、校验、影响范围限制和大规模自动回滚安全地部署变更。
配置管理是基础设施工程中历史最悠久的实践之一,但随着云原生架构规模与复杂度的提升,其重要性愈发凸显。即便企业采用临时负载、GitOps、声明式基础设施和平台工程,配置仍然是直接实时改变系统行为的机制。某个错误的配置项仍然能够(并且经常)破坏大规模的平台。
现代企业所运维的集群越来越不像传统的服务器,而更像分布式的控制系统。因此,配置不仅仅是运维的问题,它已经成为高级的可靠性工程学科,直接影响安全态势、合规性、可用性和韧性。
为什么配置仍然位于可靠性的核心位置
团队越来越依赖运行时配置来控制功能发布、流量调度、API 路由、授权决策,以及服务网格、代理和云控制平面的行为。这意味着:
配置变更通常比应用发布更快,并且一部分可能会绕过传统的 CI/CD 流水线。
某个配置更新如果触及共享的控制平面,那可能影响许多独立的系统。
配置由产品、平台、运维等多个领域的团队共同编写,形成了复杂的治理与归属边界。
即使使用基础设施即代码、GitOps 和不可变基础设施,许多最快(也最危险)的生产变更仍然来自配置的更新,而非应用程序的代码。
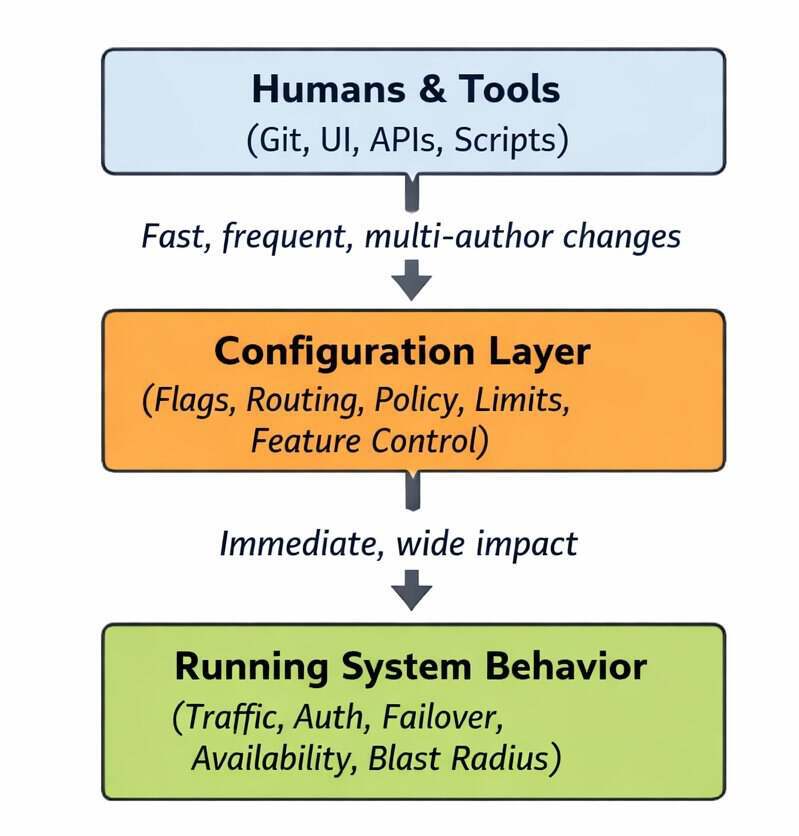
图 1:作为实时控制平面的配置,将人类的意图转化为生产环境的行为
简史:配置管理是如何演进的
奠基时代:Chef 和 Puppet
Chef、Puppet等工具确立了配置管理的许多核心理念,包括声明式期望状态、幂等资源、基于代理向已知配置收敛(convergence)等。这种模型在大规模长生命周期的服务器上表现很好,能长期提供强一致性、可重复性与可审计性。
但是,随着基础设施向弹性容量与短生命周期负载转变,其局限性愈发明显,比如,收敛活动通常由周期性的代理运行来驱动,而非事件驱动的协调(reconciliation),这可能会延迟变更的应用,延缓对故障或错误配置的响应。部署与维护重量级代理的运维开销也更加突出,而底层相对稳定、持久性主机的假设与高度动态的微服务环境不再匹配。
运维简化:Ansible、Salt 与 GitOps
Ansible和Salt通过强调无代理执行、更简单的运维模型、基于 YAML 的工作流,降低了配置管理的门槛,便于更多团队采用。与此同时,Argo CD、Flux等工具与更广泛的 GitOps 运动将 Git 重新定位为配置的权威数据源,控制器持续将运行时系统调整到版本控制中所声明的状态。
这些方法提升了入门效率,更易于管理临时的(ephemeral)基础设施,但也带来了新的权衡。在更偏重过程式的 playbook 模型中,配置会按照有序的步骤执行,而不是持续调整至期望的状态,复杂变更的执行顺序、局部性的执行失败以及重试都会导致难以分析和追踪。回滚行为通常依赖外部流程,而非内置的配置意图、依赖关系与运行时的健康感知。如果缺少严格的范围控制、校验与策略执行,提交到 Git 的单个配置变更仍可能在多个环境中广泛且不安全地传播。
这些模式改善了入门体验并简化了临时负载管理,但也带来权衡:
过程式 playbooks 存在执行顺序的问题
复杂变更内置的回滚能力有限
如果范围与策略管理薄弱的话,可能引发大范围不安全的变更
现代化平台与控制平面
企业越来越多地将基础设施即代码(IaC)与实时运行时编排系统结合,将配置从静态声明转变为主动强制执行的控制平面关注点。Terraform、OpenTofu等基础设施工具会管理资源的生命周期,Crossplane等平台通过声明式控制平面 API 暴露基础设施与服务。Open Policy Agent(OPA)等策略引擎在集群与云 API 之间实施约束与防护,确保配置变更在发布前与发布中符合组织与安全的要求。在运行时,服务网格与特性标记系统持续评估配置,以调度流量、控制韧性行为、管理渐进式发布。这些系统共同将配置视为持续调整的工作流,而非部署时应用的文件,直接影响生产系统行为。
这种向控制平面驱动配置的转变,在超大规模云服务商的全球配置设计与运维中体现得最为明显。

图 2:配置管理的演进
超大规模云服务商如何在全球范围内管理配置
超大规模运营商通过公开文档、演讲和故障事后分析深刻影响了行业的最佳实践。尽管实现各异,但共同的原则已经出现了,那就是隔离、分阶段发布、校验和自动回滚。
亚马逊云科技(AWS):可控、基于单元(Cell-Based)的传播
亚马逊云科技公开发布的架构强调:
严格审计的全局与区域控制平面
发布前的多层校验与模拟
从低影响单元或有限范围开始发布
基于 SLO 与错误信号的自动回滚
高风险变更的明确影响范围隔离
它的核心理念是,配置必须在受限环境中证明是安全的,才能影响到用户。
Meta:端到端配置治理
Meta 将配置视为覆盖后端、Web、移动端的一等制品。公开的工程材料与会议演讲展示了他们的如下实践,带强校验的模式化(schema-defined)配置存储、发布前的安全检查与差异分析、支持金丝雀和受控环境提升的分阶段发布、路由与认证等关键路径的策略执行。
Meta的MobileConfig系统将这些理念扩展到了移动端,强化了配置管理在大规模面向用户的行为中的核心作用。
谷歌:声明式安全与类型保证
谷歌的控制平面系统强调让配置正确性成为系统本身的属性,而不是仅仅依靠人工流程或 CI 流水线。公开的工程材料描述了使用强类型、模式校验的配置,结合声明式调和,控制平面会持续向期望状态收敛,并拒绝无效或不一致的更新。
系统使用依赖图推理变更的影响与顺序,理解哪些服务、资源或区域可能受到给定配置变更的影响。强制校验直接发生在控制平面内部,在配置被评估与应用的时刻,而不是仅在提交的时候。
它的目标是让不安全或不一致的配置难以(在某些情况下甚至不可能)表达或部署。
Netflix:通过配置实现韧性
Netflix 将配置变更视为韧性工程的一部分,而不是常规的运维更新。通过公开博客与开源项目,Netflix 描述了Archaius等动态配置系统如何在不重新部署服务的情况下改变运行时的行为。
这些机制支持区域隔离、可控的故障转移、特性标记驱动的渐进式发布,允许在真实流量下逐步引入并评估变更。配置路径也被纳入了混沌工程实验,确保在配置服务失效或返回异常值时系统安全运行。回滚与缓解措施与错误率和 SLO 信号绑定,强化了配置是验证与维持系统韧性的主动手段,而不仅仅是静态的输入。
一些配置出错的场景:造成广泛影响的故障
最近,涉及云、边缘、终端与电信系统的事故表明,配置安全已成为董事会级别的关注事项。
Azure Front Door 全球故障
去年 10 月,Azure Front Door 一次错误的配置变更引发了全球中断,影响了 Azure 工作负载与 Microsoft 365 等服务。公开分析显示,微软冻结配置变更、回滚到上一个已知的良好状态,并逐步恢复了服务。
这次事件的教训包括,边缘与路由配置需要多层保护(比如,staging、金丝雀和快速回滚),而不能仅依靠版本控制。
AWS US-EAST-1 DynamoDB DNS 事故与控制平面
2025 年 10 月,AWS US-EAST-1 区域发生重大故障,DynamoDB 自动化 DNS 管理系统中潜在的竞态条件生成了错误的空记录,导致该服务的 DNS 解析失败,并引发了多个依赖服务的级联故障。尽管 AWS 未将此次故障定义为简单的错误配置发布,但其根源位于大规模管理DNS与端点配置的控制平面。缓解措施包括限流、安全控制以及 DNS 自动化在压力下的行为调整。与此同时,AWS 还推出 Route 53 Accelerated Recovery,增加多区域控制平面的故障转移。
这次事件的教训包括,即使根本原因是微小的缺陷而非单次错误配置的推送,控制平面与自动化配置系统仍可能成为系统性的故障点,因此需要严格的影响范围限制、强安全控制与快速恢复路径。AWS re-invent的视频讲解了这次事件的教训,非常值得一看。
Cloudflare 配置故障
2025 年底,Cloudflare 发生了两起独立的配置相关的事故,体现了全球分布式控制平面中校验不足的风险。在一起事故中,错误的配置文件导致核心代理模块故障,引发客户流量大面积出现 HTTP 5xx 错误。另一起事故中,为缓解漏洞而部署的防火墙配置变更造成短暂但严重的流量影响。在这两起事故中,配置变更都在问题被检测到并回滚前得到了广泛扩散,放大了对 Cloudflare 边缘网络的影响。
这次事件的教训包括,位于全球互联网流量关键路径上的服务商必须将配置变更视为高风险的控制平面操作,纳入依赖感知校验、范围化发布、显式影响范围建模,避免局部错误被进一步的级联。
Google Cloud Pub/Sub 多区域故障
2025 年 1 月 8 日,Google Cloud Pub/Sub发生了多区域故障,导致客户超过一小时无法发布或订阅消息。故障还造成受影响区域中基于 Pub/Sub 的服务(比如,Cloud Logging、BigQuery Data Transfer)出现积压与延迟导出。
该故障的根本原因是错误的服务配置变更,意外地过度限制了 Pub/Sub 存储系统所用区域元数据数据库的权限,阻塞了发布与订阅操作所需的关键路径元数据的访问。该变更在短时间内被错误发布到多个区域,没有遵循标准的分阶段发布流程,并且因为环境间配置不匹配逃过了预生产测试,使单个配置错误演变为多区域事故。即使回滚后,数据库不可用仍暴露了有序传递元数据强制执行中的潜在缺陷,需要额外的修复工作才能恢复有序订阅子集的正常消息投递。
这次事件的教训包括,对共享控制平面数据存储的配置变更必须要严格实现范围化、分阶段、跨环境校验。单个错误配置可能同时破坏数据平面及其依赖的可观测性/协调机制。
其他对公司与客户产生重大影响的事故包括 CrowdStrike Falcon Sensor 事故与Optus紧急呼叫的路由故障。
现代化的安全模型:企业正在收敛的方向
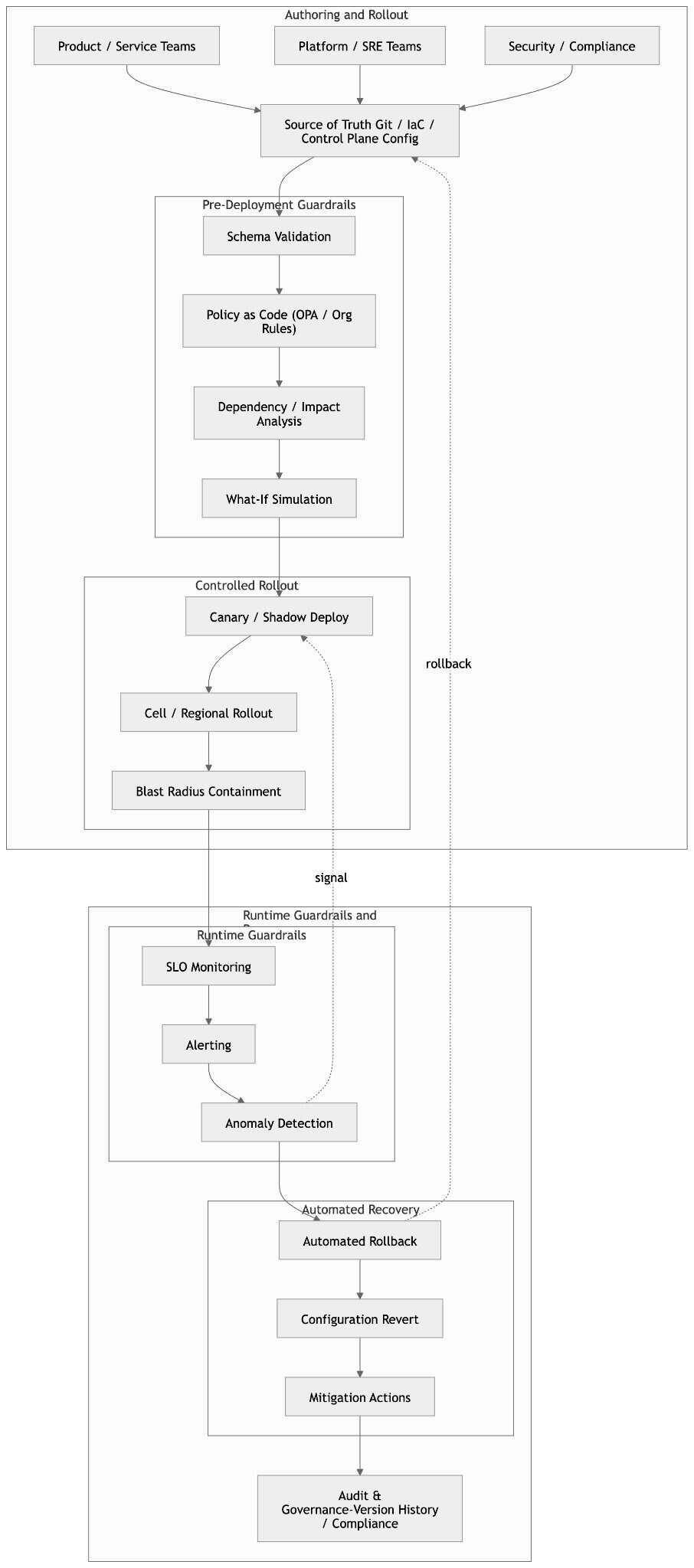
跨行业运维大型分布式系统的组织正在收敛到一套共同的配置安全模式。尽管实现不同,但是这些实践反映了如下的共识,那就是配置变更必须逐步引入、持续评估并且默认可回滚。
基础模式是分阶段、低影响范围的发布,配置变更应该首先应用于少量的流量、设备或区域,然后再广泛推广。通过在每个阶段监控 SLO 与错误信号,团队可以在检测到情况变糟时自动暂停或回滚,限制错误影响的范围。
与之相关的是影响范围的显式控制,在服务、单元或区域的边界限定配置的范围,避免可能造成灾难性失效的全局默认值。这些模式都承认故障难以避免,并专注于故障隔离。
另一个核心要素是发布前校验,将错误检测提前到生命周期更早的阶段。模式校验、策略即代码、静态或动态“假设”分析有助于防止错误或不安全配置进入生产环境。这些检查越来越多地辅以金丝雀与干跑(dry-run)模式,也就是配置在影子或双运行路径中进行评估,不立即影响用户的流量,使团队能在真实条件下观察它们的行为,并保留在执行前中止的选项。
最后,现代系统依靠运行时防护,能够关闭配置与观测行为之间的循环。自动回滚、SLO 感知阈值、与特定配置版本绑定的告警能够确保安全机制在发布期间与发布之后保持激活,而非仅在部署时。版本化、不可变配置等辅助实践能够支持快速回退与全集群的可审计性,便于故障恢复与根本原因定位。
这些模式共同构成了一种安全模型,配置被视为持续评估的控制平面,该控制平面在设计上会受到约束、实时监控,并在故障时具备快速隔离的能力。
For full size image click here
图 3:配置管理工作流与防护机制
重新定义配置管理的新兴技术
有些新的趋势正在重塑大规模配置系统的设计、运维与治理,推动配置从静态文件与临时脚本转向持续评估、策略感知的控制系统。
智能配置平台
新兴的配置平台将服务、依赖与配置视图制品建模为结构化的图,而非孤立的文件。通过纳入依赖关系与运维元数据,这些系统能揭示潜在的影响范围、突出高风险的变更,并提供语义化的差异描述,将注意力聚焦于行为影响而不是代码行级别的噪声。尽管方法各异并且各个工具仍在演进,但是它们的共同目标是帮助实践者在变更广泛扩散前在指定的上下文中理解配置变更。
无处不在的事件驱动调和器
源于 Kubernetes 等系统的调和器模式(reconciler pattern)正扩散到更广泛的基础设施与应用领域。在这些系统中,控制器会持续观测真实的状态,并向声明的期望状态收敛,响应事件而非依赖周期性的执行。该模型正越来越多地应用于容器之外的云基础设施、控制平面与边缘环境,因为它在部分故障下能够提供更强的偏差纠正、收敛与恢复保证。
AI 辅助的配置安全
有些前沿的组织已经在应用 AI 辅助技术增强配置的评审与发布,最常见的是识别异常差异、突出历史上与事故相关的变更、识别需要慢速发布或额外人工评审的更新。目前,行业的应用仍不均衡,实际上这些系统不会替代策略或校验,而是作为集成到现有防护中的决策支持层。这种采用水平反映了AI辅助运维与DevOps自动化的更广泛行业模式:机器学习技术用于关联运维信号、检测异常和辅助实现故障缓解。
配置知识图谱
基于知识图谱的方法正在涌现,它们能够将配置、运维拓扑与运行时信号统一建模为人类与机器均可查询的图。通过将配置值与服务、依赖、归属和实时信号关联,这些模型支持更丰富的发布前“假设”分析、策略评估与影响评估。尽管仍处于早期采用阶段,这一方向反映了将配置视为互联系统知识而非孤立参数的广泛趋势。
所有上述技术共同推动将配置从静态文件与临时脚本转向持续评估、策略感知、机器辅助的控制系统。
未来之路:AI 驱动和自主安全的配置
未来几年,配置系统可能会继续从重度防护的流水线演变为将安全、上下文与校验直接嵌入配置生命周期的控制平面。
带有内嵌理由与风险的差异变更
配置差异开始展示它的意图(也就是,将会引入的行为变更)、依赖感知影响评估与风险评分,这样能够帮助评审者专注于对可靠性与安全最重要的少量变更即可。
自适应、策略驱动的闸门
自主检查将基于策略、依赖分析与实时信号进行,将高风险变更的排除在外,要求在发布前进行更强的评审或额外的环境校验。低风险变更将更快地推进,在不牺牲安全的前提下减少冲突。
默认的持续校验
合成探测、影子/干跑执行路径、策略评估与异常检测将在发布期间与发布之后持续运行,将配置视为始终在线的反馈循环,而非一次性的部署制品。
跨领域统一配置 API
路由规则、IAM 策略、流量调度、特性标记与网格策略将越来越多地收敛到统一配置的 API 之后,简化治理与可观测性,并提供共享的安全机制(比如,类型化模式、策略即代码)。
调和器优先的控制平面
控制平面会更加青睐调和器驱动的模型,这使得在策略与类型系统之外应用临时的、过程式变更变得更加困难。非安全的配置不仅仅是不建议使用,而且在结构上都难以表达或部署。
长期来看,演进方向是更安全的配置:设计时约束、运行时校验与学习模型共同发挥作用,这能够许多错误配置在影响用户前就可以被阻止或自动失效。
结论
配置管理已经从运维方面的关注点演变为战略可靠性学科,在大规模场景下直接决定可用性、安全性与韧性。在现代分布式系统中,配置变更是控制平面的操作,应该与生产代码受到同等严格对待,也就是分阶段、基于真实运行时条件校验、端到端可观测并且要受到影响范围的显式限制。
最有效的组织通过模式校验、策略执行、调和器驱动收敛、与健康信号绑定的自动回滚,将安全直接嵌入到控制平面中。这些机制将配置从松散治理的制品转变为持续评估的控制平面。
随着配置越来越决定系统在压力与快速变更下的行为,真正的挑战不是更快,而是设计出让不安全的配置变更在结构上难以表达并且难以在不被发现的情况下进行部署的系统。
查看英文原文:Configuration as a Control Plane: Designing for Safety and Reliability at Scale





/filters:no_upscale()/articles/configuration-control-plane/en/resources/Figure-3-Configuration-management-workflow-and-guardrails-resized-1773664074979.jpg){kind=link}