
近日,百度正式发布 PaddleOCR-VL-1.6。作为文心衍生模型,PaddleOCR-VL-1.6 在 OmniDocBench v1.6 权威评测中准确率突破 96.3%,在 Real5-OmniDocBench、OmniDocBench v1.5 上也取得了最领先的分数,刷新业界 SOTA,在复杂文档理解和真实场景解析能力方面进一步突破。
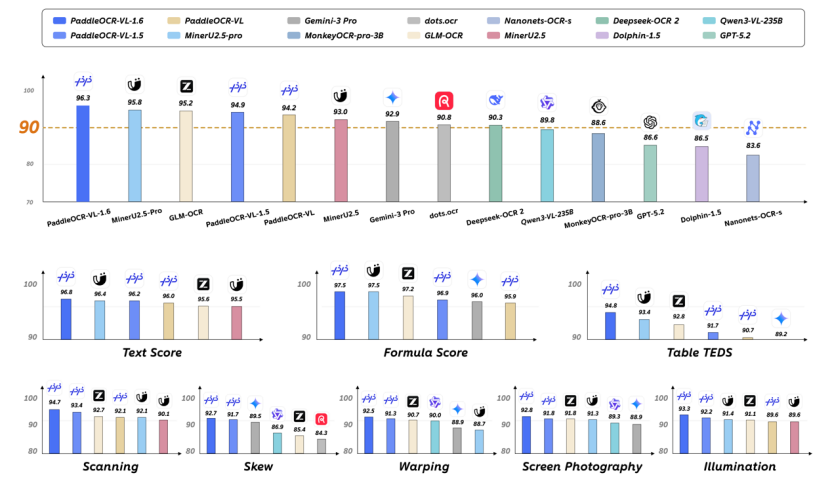
在 OmniDocBench v1.6 上,PaddleOCR-VL-1.6 在多项能力中实现 SOTA
官方结果显示,在权威评测集 OmniDocBench v1.6 上,PaddleOCR-VL-1.6 总指标达到 96.33%,超越 Gemini-3-Pro、GPT-5.2、MinerU-2.5-Pro、GLM-OCR 等,领跑全球通用大模型和专用 OCR 模型;在面向真实复杂场景构建的 Real5-OmniDocBench 评测中,PaddleOCR-VL-1.6 总指标达到 93.19%,较 Gemini-3-Pro 提升近 4 个百分点,在扫描件、弯折文档、屏幕拍照、光照变化及倾斜文档等五大真实场景下均保持领先表现。
测试结果显示,PaddleOCR-VL-1.6 在文本、公式、表格等核心识别能力上全面领先当前主流开源及闭源方案,在表格、古籍、生僻字识别等复杂场景能力显著提升,在印章、Spotting、图表识别等多项关键能力同步增强,可更好满足文档数字化的需求。

据了解,PaddleOCR 基于文心大模型训练而来,是文心大模型多模态能力的重要部分,支持超 100 种语言识别,用户覆盖 170 多个国家和地区。此次发布的 PaddleOCR-VL-1.6 在 PaddleOCR-VL-1.5 基础上进一步升级,通过模型驱动的数据构建机制和渐进式训练优化,在保持 0.9B 轻量化架构的情况下,模型准确率和复杂场景适应能力进一步提升。由于两代模型模型结构一致,开发者和企业用户无需进行额外适配,即可平滑迁移。
近年来,PaddleOCR 持续推进文档理解能力升级,先后推出 PaddleOCR-VL、PaddleOCR-VL-1.5 等多款模型。其中,PaddleOCR-VL-1.5 创新支持异形框定位,在真实文档场景中展现出较强解析能力。此前,PaddleOCR GitHub Star 数已突破 79.2K,超过谷歌开源 OCR 项目 Tesseract OCR,成为全球最受开发者欢迎的开源 OCR 项目之一。
目前,PaddleOCR-VL-1.6 已上线 PaddleOCR 官网,支持网页端和 API 调用。同时,模型代码及权重已同步开源至 GitHub 和 Hugging Face,面向全球开发者开放使用。
· PaddleOCR 官网:paddleocr.com
· Github:github.com/PaddlePaddle/PaddleOCR
· HuggingFace:huggingface.co/PaddlePaddle/PaddleOCR-VL-1.6




