
Meta 的工程团队最近介绍了 Meta 如何对一个数据摄取平台进行迁移,以提高可靠性和运营效率,该平台每天传输数 PB 量级的 MySQL 社交图谱数据。团队使用了反向影子和持续校验和监控等技术,确保在迁移过程中实现零停机。
Meta 运营着全球最大的 MySQL 集群之一,其数据摄取平台为数据分析、报表生成、机器学习和内部产品开发工作负载提供支撑。Meta 最近进行了架构重构,用集中式、自管理的数据仓库服务取代了由各个业务团队独立维护的数据流转管道。
通过这次迁移,Meta 用集中式托管系统替代了分散的、由各管道各自运维的基础设施,通过分阶段迁移、自动化验证、回滚控制和兼容层,在不中断下游分析和机器学习工作负载的情况下,完成了数千条数据摄取管道的迁移。
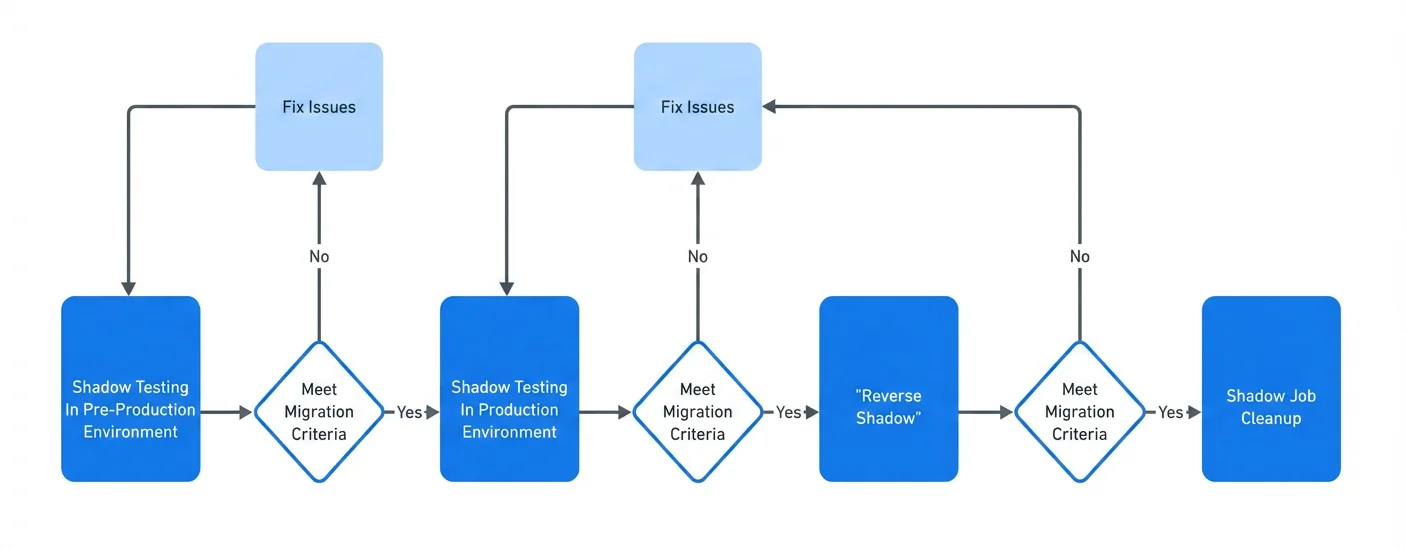
在超大规模分布式系统部署场景下,Meta 将数据摄取作业的迁移划分为三个阶段:影子阶段,使用生产数据对新系统进行验证;反向影子阶段,将生产权限切换至新系统并保留回滚能力;清理阶段,待一致性与性能检测通过后,下线原有数据管道。Meta 软件工程师 Zihao Tao 及其工程团队成员解释道:
我们持续监控生产作业与影子作业之间的行数及校验和异常。一旦出现数据不匹配,我们会快速排查原因,将修复方案部署至预生产环境,再验证问题是否已解决。与此同时,我们还会统计影子作业的计算与存储资源占用,确保生产环境在继续推进前资源充足。
来源:Meta 工程博客
在完成整个数据摄取工作负载的迁移并淘汰旧系统后,团队总结了这次大规模基础设施转型过程中遇到的挑战:
要实现无缝迁移,我们必须高效跟踪数千项作业的全迁移周期,并搭建可靠的发布与回滚机制,应对迁移过程中可能出现的各种问题。
每个迁移作业在上线前都必须经过严格的正确性和性能检查,比较新旧系统之间的行数和校验和,监控延迟和资源使用是否出现退化,并对依赖方使用的关键表增加额外的规范。团队解释道:
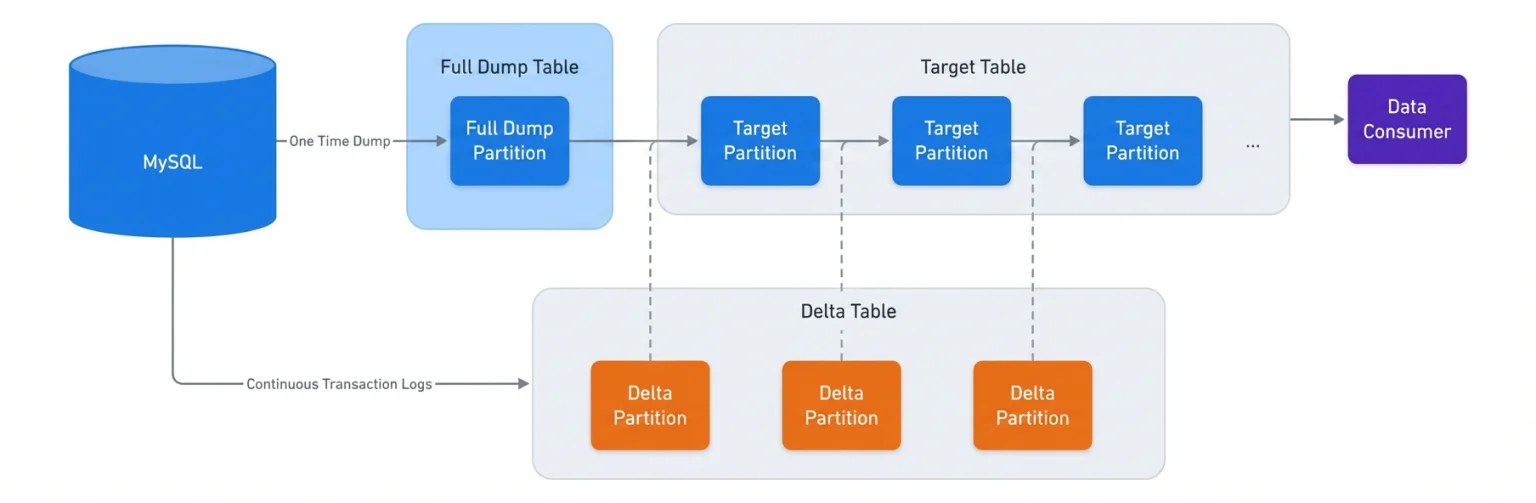
我们的旧系统和新数据摄取系统都使用变更数据捕获(CDC)来将增量数据摄取到目标表。每个数据摄取作业都有自己的内部表用于源数据库的全量转储,一张用于捕获源数据库变更的内部表和数据消费方使用的目标表。作业相关的所有实体信息,包括表名与表结构,都由集中管理服务统一存储和维护。
来源:Meta 工程博客
Syed Moeen Kazmi 评论道:
以 Meta 的业务体量来看,数据摄取迁移并非简单的系统升级,而是对核心业务进行的高难度改造。挑战不只在于数据迁移本身,更要保障数据一致性、实现零停机。
由于 CDC 架构需要依靠成本较高的全量快照完成初始加载与故障修复恢复,Meta 将非必要影子作业的创建延后至数据质量问题解决完毕。这避免了重复执行大规模全量转储,大幅提升了迁移效率。团队还在迁移初期复用旧系统的快照分区,以此降低基础设施的运行负载。
查看英文原文:https://www.infoq.com/news/2026/05/meta-cdc-migration/




