
作者 | 作业帮大数据团队(刘泽强、孙建业)
历史背景
作业帮实时计算主要基于 Flink 构建,共有 3000 多个任务,均采用 Per-Job 模式部署在 Yarn 集群,因 sla 要求差异不同部门间集群独立。历史 on Yarn 模式主要面对问题如下:
资源隔离粒度粗。Yarn 集群本质通过内存隔离,因业务线差异,流量类 Flink 任务处理大量字符串匹配消耗 cpu 多,导致同集群其他任务吞吐下降,出现延迟;
资源利用率低。无论采用多集群部署还是单集群 Node Label 方式,都需要预留资源防止机器故障、新增任务等情况,导致资源利用率偏低。同时各部门场景差异,集群资源使用特点不同,资源共池管理、任务间资源强隔离后可实现互补。例如流量类场景会做大量字符串匹配 cpu 消耗高,简单数据同步 cpu 消耗低等;
平台逻辑复杂。部分业务有高可用需求,我们部署两套 Yarn 集群作为主备,状态存储在对象存储,Flink 任务托管平台提供切换能力,单集群异常时自动切换。这种模式调度逻辑非常复杂,同时备用资源存在浪费。
选型思考
任务提交方式
目前行业中有多种提交方式。首先 Standalone 模式,这种模式资源静态分配,Flink 任务扩缩繁琐。其次是 Native 模式,Flink 原生支持,通过构造 Flink 命令提交任务,在平台层可根据多版本历史任务情况灵活适配。核心逻辑是 Flink 内置了 Kubernetes client,直接和 k8s api server 服务通讯,创建 JobManager 部署。Flink 的 ResourceManager 将与 k8s api server 服务器通信,动态按需分配和释放 TaskManager pod,与 Yarn 原理类似。
还有 Flink Operator 模式,更贴近 k8s 生态,通过构造 Flink CR 提交给 k8s api server,Operator Observer 通过 k8s api 检查 JM Deployment 状态、Flink Rest api 获取 job 指标等信息,Validate 根据预设规则检查用户提交 spec 是否合法,Reconciler 对比“观察到”的状态与“期望”的状态决定操作动作,Updater 将最终的执行结果和新的状态再次同步给 K8s API Server,Operator 托管了 Flink 任务完整生命周期。对平台而言复杂度大大降低,同时 Operator 模式还兼顾动态扩缩能力,为实时离线资源弹性提供基础。最终采用了 Flink K8s Operator 模式。
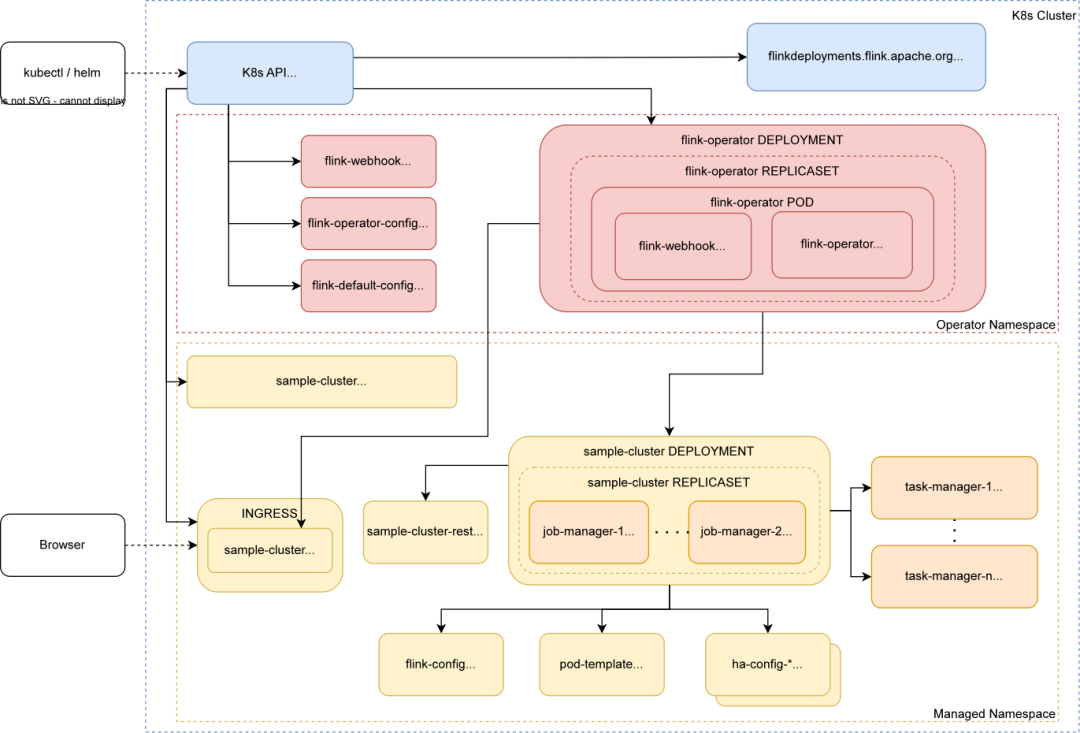
任务状态观测
Flink 任务可观测性主要分为如下几个方面:
Flink 运行态 WebUI:通过 Ingress Service 来代理实现;
Flink 历史日志查看:通过部署 LogAgent 收集 pod 日志到 kafka,然后落到对象存储中,通过 LogSearch 检索。LogAgent 和 LogSearch 复用了在线业务日志能力。
Flink Metrics 监控:在官方 PrometheusReporter 的基础上增加了 discovery 的功能。Container 的 HTTPServer 启动后,把对应的 ip:port 以临时节点的形式注册到 zk 上,然后利用 Prometheus 的 discover targets 监听 zk 节点的变化。由于是临时节点,Container 销毁时节点消失,Prometheus 感知后停止抓取。
K8S Events 信息:通过 k8s watch 机制订阅关键事件进行存储;
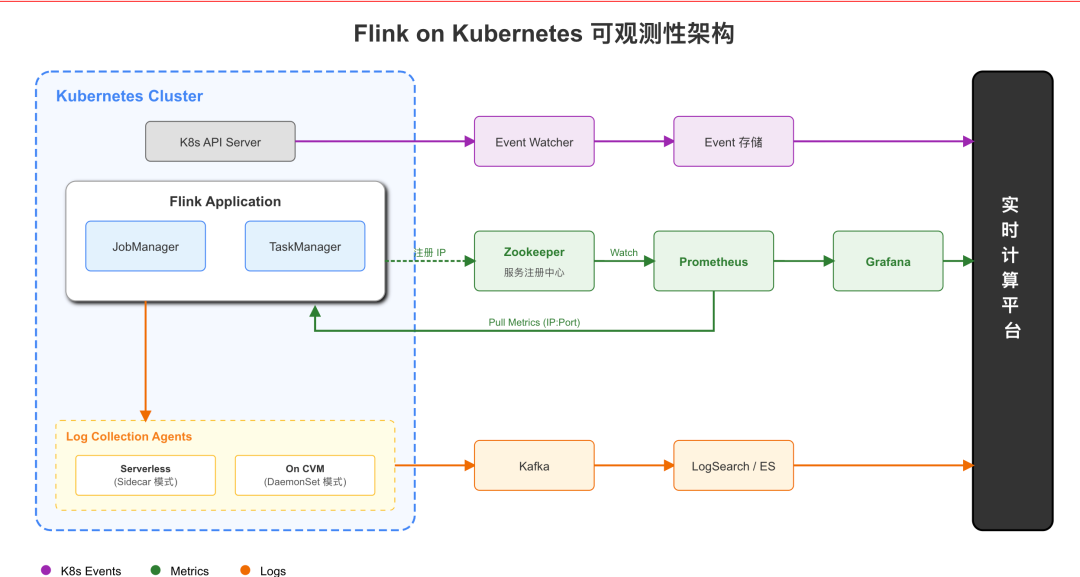
环境资源和成本
作业帮大数据是建立在多个公有云半托管 EMR 上的,Flink on yarn 模式转变为 k8s 时切换到了公有云的 k8s 产品。Flink 任务虽然是两阶段资源申请,但整体形态和在线业务场景很像,都是长时服务,在调度方面已有能力基本都能满足需求。Flink 整体资源规模万核左右,pod 个数大概 1.3 万,常规 k8s 集群调度效率百级每秒,全部任务 1min 左右拉起来,性能满足需求。
考虑降本效果,单云一个 K8s 集群,采用固定节点和公有云 serverless 兜底的方式最大化消除 buffer 资源。每个业务部门一个 Flink k8s Operator 和 namespace 来代替 Yarn 队列概念,通过 quota 控制资源使用上限。为保障单节点利用效率 request = 0.1*slot(1 slot 等于 1core), limit = request 超用系数。超用系数根据 Flink 任务特点、稳定性、节点负载等情况调节。业务成本分摊由按集群、队列方式转变为根据任务实际占用情况分摊,优化任务后降本效果立刻体现,避免了平台和业务的沟通、运维成本;
技术方案
平台整体架构
核心两个方面变化,一个是调度服务解除了 Flink 生命周期管理,并且服务本身无状态仅用于处理请求。修改 Operator 将任务状态主动上报调度服务。二是高可用保障利用 k8s 拉齐,不在依赖主备集群模式,低保障集群状态全部切换到对象存储。详细如下对比图:
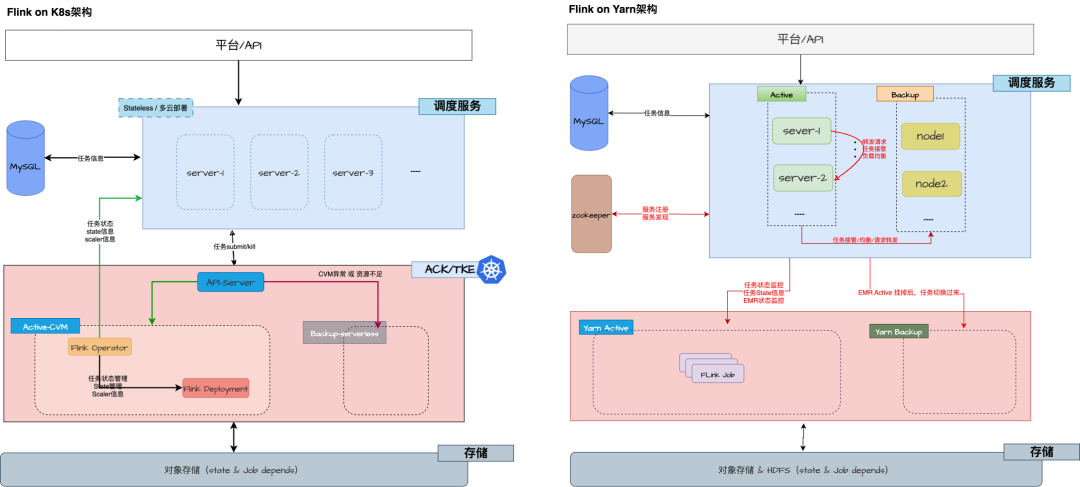
任务迁移方案
我们线上 Flink 任务版本比较杂 1.14.x、1.12.x 甚至还有 1.9.x,历史较低版本的 Flink 在能力和性能上还存在缺陷,我们做了一些适配和优化,当前绝大多数能力在最新版本基本都已解决。同时 Operator 模式对 Flink 最低版本有要求,所以在迁移时将 Flink 任务升级到最新稳定版。考虑整体变化比较多,最靠谱的方式双跑对数保障准确,根据已有监控关注延迟保障效率。
验数整体思想是将 Flink 无界流利用 source offset 转为有界流,工具化解析并替换为测试 source、sink,分别启动新老版本的测试任务,通过 sum(hash(fields)) 和 count(1) 方式验证数据准确性。详细内容如下图:
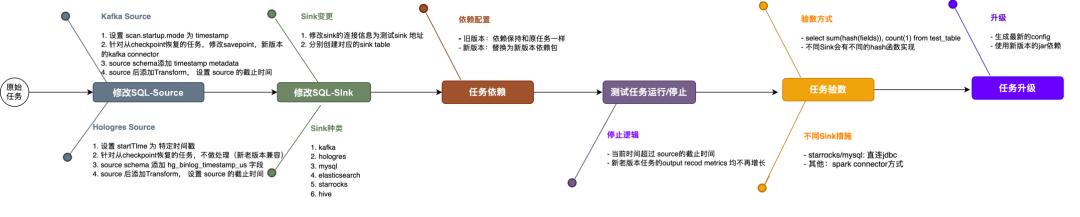
Jar 任务整体占比不足 10%,提供对数工具、解决方案等辅助方式配合业务迁移。
核心问题
Flink 版本兼容性问题
Flink 高、低版本 kafka state 不兼容问题
针对需要从 state 恢复的任务,我们需要在迁移任务的过程中,通过 state processor api 读取老的 state,然后适配为新的 state(state name, state 序列化类等),然后迁移任务;
Flink 高、低版本语法兼容性问题
高版本 cast 方法要求更严格,如果要达到和低版本 cast 一样的效果,需要使用 try_cast
不同类型数据隐士转换失败问题(比如 int -> string),高版本要求更严格,会直接报错失败,需要修改 flink ddl 对应数据类型
高版本 Flink udf 针对 nested 返回格式的函数要求更严格,需要显示在 udf 中设置相关的 DataTypeHint, 否则运行失败
高版本 kafka connector 和低版本 kafka connector 逻辑差异:低版本解析数据失败,try catch 打印错误; 高版本会直接让任务失败。在 sql 中设置 parse-fail.ignore 参数解决;
Flink 升级后,upsert sink 相关的任务的 state 一直变大,最终任务 oom 挂掉
高版本 Flink 针对 cdc 数据写入 Upsert Sink,会引入 SinkMaterializer 算子,保证乱序数据的准确性,会导致算子 state 一直扩大
原理:高版本 Flink 针对 cdc 数据写入 Upsert Sink,为了防止 change log 乱序造成的数据准确性的问题, 引入了 SinkUpsertMaterializer 算子,该算子会根据主键维护一个 keydState, 在主键比较多的情况下,会占用很大的 state。
解决:确保主键不乱序的情况下, 设置 table.exec.sink.upsert-materialize = None 或者 设置 state ttl
Flink OOM kill 问题
问题原因:pod oom-kill 基本都是 jvm 的堆外内存溢出导致的,经过内存分析,发现是 k8s 节点的透明大页开启导致(Yarn 节点默认关闭)。
核心原理:透明大页主要是 linux 为了解决大内存分配场景下,因为默认 page 较小导致 page table 过大,CPU 查找虚拟地址到物理地址映射(TLB, Translation Lookaside Buffer)的效率降低引入的。但是针对 Flink 应用等下内存场景下,却会导致内存过度分配等问题。
解决方案:因为我们的 Flink 场景下,pod 都是小内存,普遍 2G 左右,透明大页会造成内存浪费的问题。关闭透明大页后,堆外内存溢出的问题基本没再出现。
无资源压力情况下处理效率变低问题
问题原因:任务的 cpu 使用率没有超过 pod 的 limit 限制,机器的 cpu 使用率也比较低,但是任务却延迟严重。原因为 K8S CPU Throttling 导致的, 虽然没有超过 limit,但是已经触发了多次的 throtting
核心原理:Kubernetes 进行 cpu 资源隔离是通过 Linux CGroup 的(时间周期,默认 100ms=10000us)和(周期内的 CPU 时间上限)共同限制进程 CPU 使用,若进程在周期内用尽,内核会 throttle(暂停)其 CPU 使用,直到下一个周期开始。实际生产中,突发 / 波动流量会导致进程快速消耗完,进入 throttling 状态,从而造成进程无法继续用 CPU,引发业务延迟。
解决方案:全局配置 cpu burst 超用 或者 任务配置更大的 slot(cpu limit)缓解 throtting(我们线上采用这种方式)
资源文件依赖问题
Flink on k8s 支持了 remote artifact fetching 能力,但是不支持 zip 依赖、http 重定向报错、TM 无法引用等问题。对 HttpArtifactFetcher 进行了扩展。
支持递归提取 tgz、zip 等压缩包中的 jar 包,确保依赖资源的正确加载。
兼容 http 到 https 的协议重定向,解决了跨协议资源获取的问题。
在 TaskManager 启动时,将相关依赖加载到其 classpath 中,保证任务的正常运行。
ConfigMap 优化
默认 Flink 保留近三天的 checkpoint,个数比较多,configMap 中存储的元信息比较大,导致超过 etcd 1MB 大小限制同时当 configmap 较大、大量 Flink 作业访问 configmap 时,对 etcd 的网络 IO 和磁盘 IO、apiserver 的内存都有较大的压力。
我们的做法是:修改 Flink 源码,在写入 configmap 的时候,将 configmap 相关的信息先 gzip 压缩再存储,读取的时候先 gzip 解压再返回,以此降低存储大小保证管控面的稳定性。另外该能力通过参数的形式进行控制,这样也保留了原生 Flink ConfigMap 读写的能力
节点负载不均问题
产生节点负载不均的原因有多种场景,例如 Cpu 密集型 Flink 任务多个 TM 分配到相同节点导致 Cpu 覆盖高、新增任务时非资源使用高峰导致调度误判引起高峰期时负载不均、高峰期过渡驱逐导致预期外任务重启。解决方案多种逻辑配合进行,首先 Pod 反亲和,尽可能将单个 Flink Job pod 打散,避免单资源密集型任务 pod 过渡集中。其次高负载节点降压,以 Pod 实际占用资源和负载情况打分,逐步驱逐高分 Pod。还有负载调度,预选阶段根据负载指标阈值,排除高负载节点,优选阶段综合考虑节点负载、Pod 亲和性、Pod 数量、镜像本地性等因素进行打分,将任务调度到最优节点。
任务停止慢问题
任务暂停时,我们通过平台调度服务调用 k8s api server 直接将 flinkdeploymnet 给删掉,Operator 检测到删除 event 事件后进入 cleanup 流程,清理 metrics、autoscaler 等相关信息、删除 Job Manager Pod、Deployment、Ha 数据等。整体流程似乎没啥问题,但是耗时比较慢大概 1~2min,即便任务 pod 数量很少也是一样。
分析 Operator 日志发现,耗时主要发生在删除 jobmanager 阶段。老的 taskmanager 收到 SIGNAL 15: SIGTERM,然后 jobmanager 申请新的 taskmanager。分析 k8s 的审计日志,在删除 deployment 的时候出现了 taskmanager pod 新创建的情况,新增的 taskmanager pod 因为 flink configmap 被删除,导致 pod 无法 mount,然后 pending 1~2min。
综合分析,flinkdeployment finalizer 自身的删除逻辑和 k8s 资源删除逻辑同步执行,导致触发了 flink 任务的 failover 流程,从而出现新增 taskmanager pod 的情况出现;同时由于 flink configmap 也同步被删除,导致 creating pod 卡住,进一步导致 deployment 的删除卡住。解决方案在删除资源的时候,把 Propagation 从 Foreground 改为了默认的 Background,让 K8S 先走完 Operator 自身的删除流程,再走默认的资源清楚逻辑。
整体收益
目前整体已有 95% 的任务完成迁移,总体资源消耗降低 20%。集群数量减少,平台复杂度降低,运维成本减低。集群整体 sla 提高,向上拉齐。
未来探索
Flink 任务的弹性扩缩和资源调优(基于 Flink Kubernetes Operator)。目前高低峰明显,实际机器资源利用率差 60% 多;
现有业务实时、离线场景天然错峰,考虑基于 k8s 弹性混布。




