
Datadog 推出了Monocle,这是一个用Rust编写的、新型的实时时间序列存储引擎。该系统统一了公司的度量指标存储基础设施,提供了更高的数据摄入吞吐量和更低的查询延迟,同时降低了运维复杂性。Monocle 取代了他们的历代存储后端,解决了随时间积累的并发挑战和扩展性限制。
Datadog 存储基础设施的早期设计将责任分散在多个系统之间。度量指标数据被写入实时数据库(Real-Time Database,RTDB),它存储了
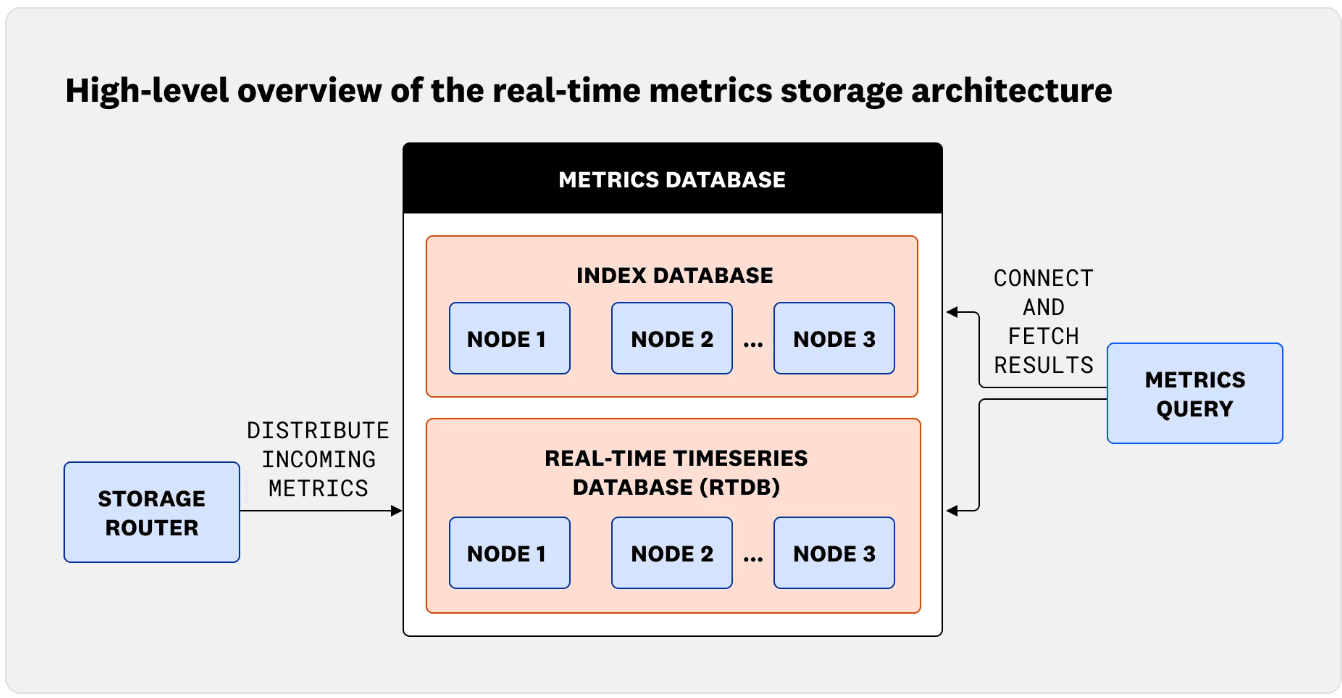
实时度量指标存储架构的高层概述(来源:Datadog工程博客)
RTDB 的这种架构经历了几次迭代。第一代依赖于Cassandra实现高写入吞吐,但是查询灵活性有限。随后是基于Redis的设计,这提高了响应性,但遇到了持久性和单线程执行的问题。MDBM是一个内存映射的键-值存储,提供了更好的操作系统缓存使用,但遇到了可扩展性的瓶颈。随后,基于 Go 的 B+树引擎采用了每个核心一个线程(thread-per-core)的模型,增加了并发性,但也增加了复杂性。后来,RocksDB 提供了持久性,并通过DDSketch支持分布式指标,不过在扩展方面仍然存在挑战。
Monocle 将这些先前的方法整合到了一个统一的基于Rust的引擎中。它采用了每个核心一个分片,每个分片一个工作者(shard-per-core,worker-per-shard)的模型,每个存储工作者管理自己的日志结构化合并树(LSM 树)实例,以摄入数据、提供查询服务和执行后台任务,如压缩。设计采用了早期的分片存储:通过其时间序列键标识每个数据单元,它们被分配到一个分片上,确保 CPU 核心之间的负载分布均匀。正如 Datadog 工程师所指出的,“这种每个核心一个分片,异步工作器模型是 RTDB 的基础。”设计消除了写入路径上的锁和原子操作,减少了争用,而 Rust 的内存保证了安全性和并发性。
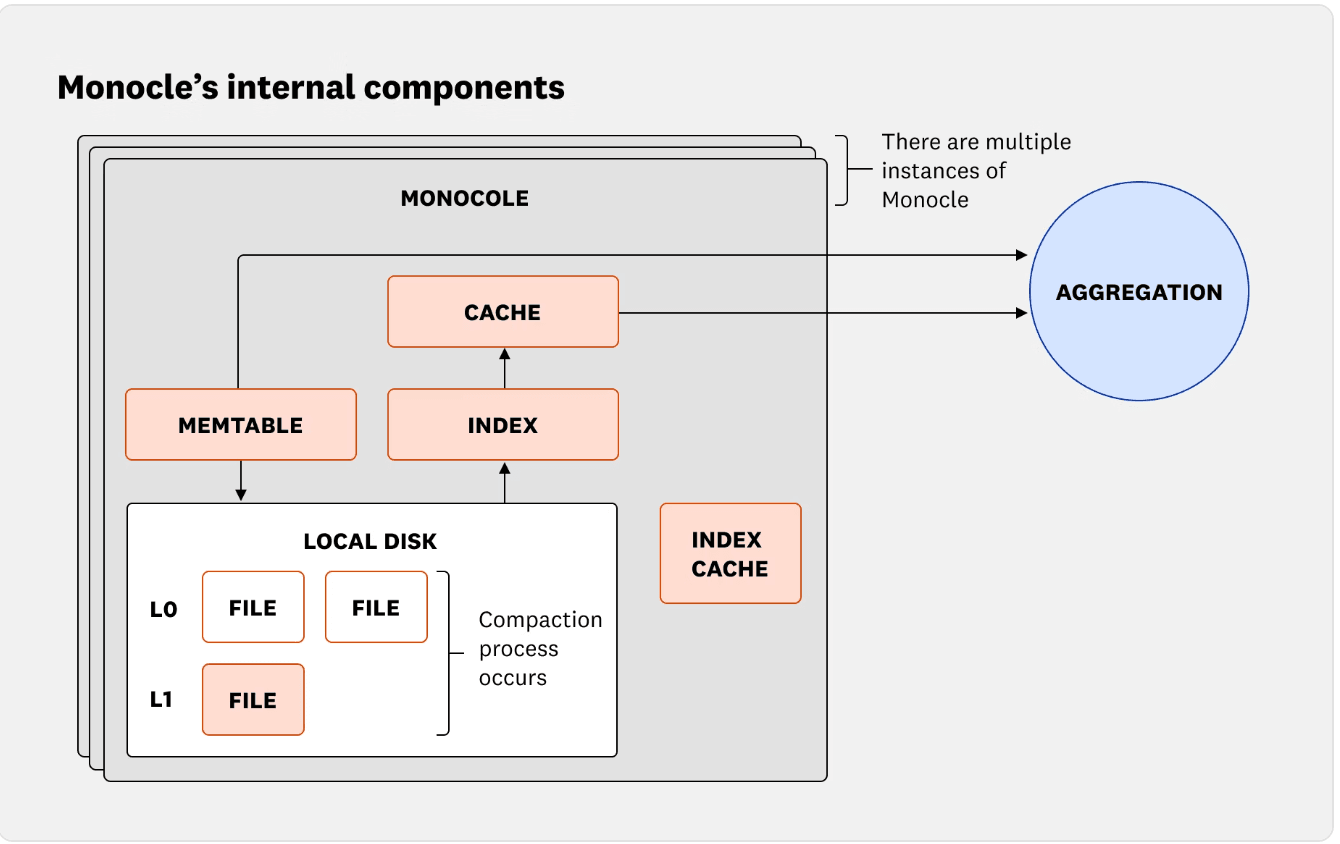
Monocle 的内部组件来源:Datadog工程博客)
该引擎将数据摄取、存储与查询处理整合于单一系统中。写入操作通过内存表缓冲,并采用受 LSM 树启发的压缩机制实现持久化。基数树缓冲区加速聚合操作,统一缓存则降低查询延迟。数据按时间分段存储,每段采用最近最少使用(LRU)策略,在保留最相关查询的同时驱逐过期查询,确保系统在高负载下仍保持数据新鲜度与响应能力。
Datadog 报告的性能基准测试显示了显著的收益。Monocle 实现了数据摄入吞吐量的 60 倍增加,高峰时查询延迟的 5 倍减少,与早期系统相比成本效率提高了一倍。这些改进归因于每个核心一个分片的并发模型、Rust 的效率以及在写入和查询路径上的优化。
Datadog 的工程师指出,Rust 重写和模块化设计的另一项关键优势在于:为 Monocle 开发的组件现正被复用到 Datadog 的其他系统中,这既提升了可维护性,又增强了平台范围的一致性。
原文链接:
Datadog Launches Monocle, a Unified Rust-Powered Real-Time Metrics Engine




