
于子淇,小红书 资深技术专家
在人工智能技术的快速发展中,多模态大语言模型(MLLM)以其强大的图文理解、创作、知识推理及指令遵循能力,成为了推动数字化转型的重要力量。然而,如何使这些模型的输出更加贴近人类的风格、符合人类的偏好,甚至与人类价值观保持一致,成为了一个亟待解决的问题。为了应对这一挑战,基于人类反馈信号的强化学习方法(RLHF)应运而生,其中,PPO(Proximal Policy Optimization)算法作为 OpenAI 的核心技术,在 RLHF 阶段扮演着关键角色。
小红书大模型团队,在这个技术日新月异的时代,开始了他们自研 MLLM RLHF 训练框架的征程。他们深知,要构建一个高效、准确的 RLHF 训练系统,需要综合考虑算法优化、系统架构、训练调度以及推理引擎等多个方面。
在本次 QCon 上海 2024 大会上,小红书团队的资深技术专家于子淇展示了他们的在RLHF框架上的探索、设计和优化细节。同时,他也分享了未来的计划与实践中的痛点,如 RLHF PPO 算法的资源消耗复杂度过高、训练精度的敏感性等,这些问题既是挑战,也是他们持续优化的动力。
于子淇是小红书资深技术专家,也是 RLHF 自研框架负责人,主要从事 RLHF 系统从 0 到 1 的构建以及训推一体性能优化,帮助团队拿到端到端的模型效果收益,他曾担任阿里云高级开发工程师、卓越工程师、技术布道师,参与 AIACC( DawnBench 榜单第一)加速库开发,NCCL 通讯库优化等分布式训练的性能优化工作。
RLHF 背景与技术选择
InfoQ:您能介绍一下 RLHF(Reinforcement Learning from Human Feedback)在多模态大语言模型训练中的重要作用吗?当时研发这款框架的背景和初衷是怎样的?要解决小红书业务上的具体什么问题?
于子淇:RLHF 是大模型的重要一环,纯文本语言模型或者多模模型都是需要的,主要目的是通过人类反馈来优化模型,减少幻觉(所谓幻觉就比如,大模型回答了自己不知道的,不符合事实,或者不遵循原文的内容),提升模型的泛化能力。最初,我们开发自研框架是因为最早基于某些开源的版本调试不满足业务需求,我们尝试过 trlx 和OpenRLHF(前者模型规模大时性能不好,后者在我们的实际场景下训练不收敛),比如长文或者更大规模的模型不支持,有较大的性能瓶颈,所以进行了重新开发。RLHF 是 pretrain、sft 之后的一个环节,最终作为一个大模型进行输出的,可以这样理解,RLHF 可以针对性的解决某一类用户体验偏好的问题,从而实现按照产品期望的人类喜好进行学习。
InfoQ:小红书为什么选择 PPO(Proximal Policy Optimization)算法作为 RLHF 阶段的主要算法?它相较于其他 RL 算法有哪些优势?为什么它更加适配 RLHF 框架?
于子淇:PPO(Proximal Policy Optimization,近端策略优化)是在强化学习领域的经典算法,由 OpenAI 所提出,并应用于 LLM 大模型领域的一个算法,相当于已经被证明有效,大家都是站在巨人的肩膀上,所以 RLHF 基本都会使用 PPO,我们也是在最早技术选型的时候,选择并且坚持至今,并且目前也已经在业务场景下有了正向收益。PPO 可以在线生成数据,探索空间更大,算法效果好是一个算法被追捧的关键,当然 PPO 的缺点也比较明显,就是过于复杂,同时 4 个模型推理和 2 个模型训练,所以成为我们重点优化 RLHF 框架的对象。
InfoQ:在您的 RLHF 框架设计中,基于 actor/critic 的 offload 同构组网架构是如何提高训练效率的?
于子淇:同构组网是基于 actor、critic 两个模型结构类似的思路,通过 offload 的方式完成模型的切换,这样可以串行实现 2 个模型的训练,具体的,actor 训练完成后需要把当前的模型参数、梯度、ddp 的 bucket、优化器状态等迁移至内存,空余显存后给 critic 做训练,是一种以时间换空间的方式,但是 offload 这个操作只有秒级的开销,这个对于几十秒或分钟级别的训练来说可以忽略,但是可以降低一倍的显存消耗,相当于用一个模型所需要的集群即可完成 2 个模型训练的 PPO 流程;并且相比异构组网(actor、critic 分离于独立集群,需要同步 rollout 的 experience 数据,这部分随着数据量增大也是不可忽略的),没有 rollout 的额外同步。
InfoQ:您提到的“Pipeline 优化”具体是如何实现的?这对性能提升有哪些直接影响?
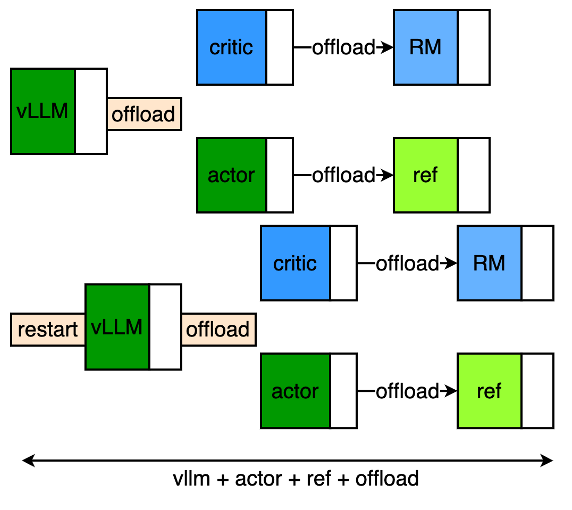
于子淇:Pipeline 流水线主要针对 make-experience 阶段进行优化,传统方式需要依次进行 vLLM 的 generate、actor/critc 的 forward,存在较大的性能缺陷,通过全量 offload 优化,可以把没个 workload 充分利用每个 GPU,但是也引入了 offload、vllm-restart 操作,即全部资源进行 vllm 后逐步进行 4 个模型的 forward,存在明显的空窗,通过 Pipeline 的方式可以将整个 rollout-batch-size 进行切分,按照推理的最佳 running-batch 进行流水线操作,这样可以在不降低 vllm 推理效率的情况下,overlap 掉 4 个模型的 forward 以及 offload 等上下文切换的开销,大幅提升性能。
InfoQ:精度对齐(RM 精度要求)在您的框架中是如何确保的?这对模型最终的表现有何影响?
于子淇:PPO 本身收敛稳定性一般,对超参敏感,实验表明,reward model 的打分精准度,会影响收敛效果,所以 RM 的精度有严格的要求。RM 精度对齐是通过训推一致的方式实现的,首先 RM 训练和推理用统一的框架是确保 bitwise 一致的必要条件,还有一些细节上的处理,比如 padding、组 batch、allreduce 替换为 allgather、等方式也需要对齐,所以我们废弃了早期的 RM-serving 走 api 的方式,而是在 rollout 阶段 offload critic-model 进行切换到 RM 的参数,从而进行准确的 reward-score 输出,保证了训练和推理的完全一致,RM score 的 accuracy 能够达到无损复现(不对齐 acc 会掉点)。
InfoQ:您在 QCon 的演讲内容中提到训推一致性在优化策略中占据有很重要的问题,它对于提高模型部署效率有何帮助?您能结合业务场景聊一下为什么训推一致性很重要吗?
于子淇:是的,训推一致性能够保证训练以及 serving 的鲁棒性,①RM 精度的对齐保证打分的准确性,否则 RM 准确性掉点会影响最终的走势;②训练阶段 rollout 过程使用了 vllm-serving,但模型训练走的是 megatron-core,vllm 推理引擎和 megatron-core 框架是无法完全对齐的,我们内部自研的推理引擎,是专门对齐过训练框架的,能够和 megatron-core 完全一致,因此最终训练完的 actor 模型上线部署时通过自研的推理引擎完成,保证推理风格、测评效果的准确性。
训推一致性重要性:计算机无法精确表示浮点数,有 rounding error,所以会出现“大数吃小数”的情况。LLM/VLM 中有大量的浮点数乘加运算,并行计算的算法乘加顺序有变化时,会导致结果不同,被大语言模型的几十层神经网络逐层放大之后,影响模型输出。训推一致可以严格体现训练时效果,在模型研发阶段有利于 bad case 追溯。
InfoQ:Medusa 在提升采样效率方面的具体机制是什么?这对训练时间和资源消耗有何影响?
于子淇:Medusa 算法上就是通过在大模型的最后隐藏层,增加多个解码头,来并行预测接下来的多个 token,而不只是一个 token,从而实现所谓的投机采样,一旦预测准确,就可以降低 decode 的 token 数量,提高总的解码效率;这个主要是针对 rollout 采样阶段,降低 actor 的推理耗时,在长文本下有 1.5 倍加速比,资源上只需要并行进行一个伴生训练进程,保证 Medusa 的 head 和主干模型参数的契合,提高接受率,保证加速比不衰减;Medusa 训练部分 frozen 了主干部分,所以只需要单机过一遍 rollout 的数据即可完成,并且伴生训练可以和 PPO 的训练 overlap,不会降低训练速度;
InfoQ:您提到收敛速度超越了 trlx 一倍,这是通过哪些关键技术或策略实现的?而训练速度超越 openrlhf 一倍,背后有哪些创新性的优化手段?
于子淇:收敛速度是有一些 trick,比如通过 advantage-whiten 在整个 rollout-batch 内部实现,可以提高激励的准确性;训练速度提升的技术很多,比如架构上的 pipeline 设计(保证了推理速度的同时,rollout 阶段的空窗最小),多模并行粒度的调优(降低多模的 vit 部分开销,性能提升到和语言模型一致),Medusa 训推伴生训练(进一步提升了 generate 生成速度),vllm-http-server 的方式替换 ray 做数据通信(规避 ray 序列化的性能开销),这些都是创新性的优化手段
InfoQ:能否分享多模态 LLM 在 RLHF 训练时遇到的挑战?
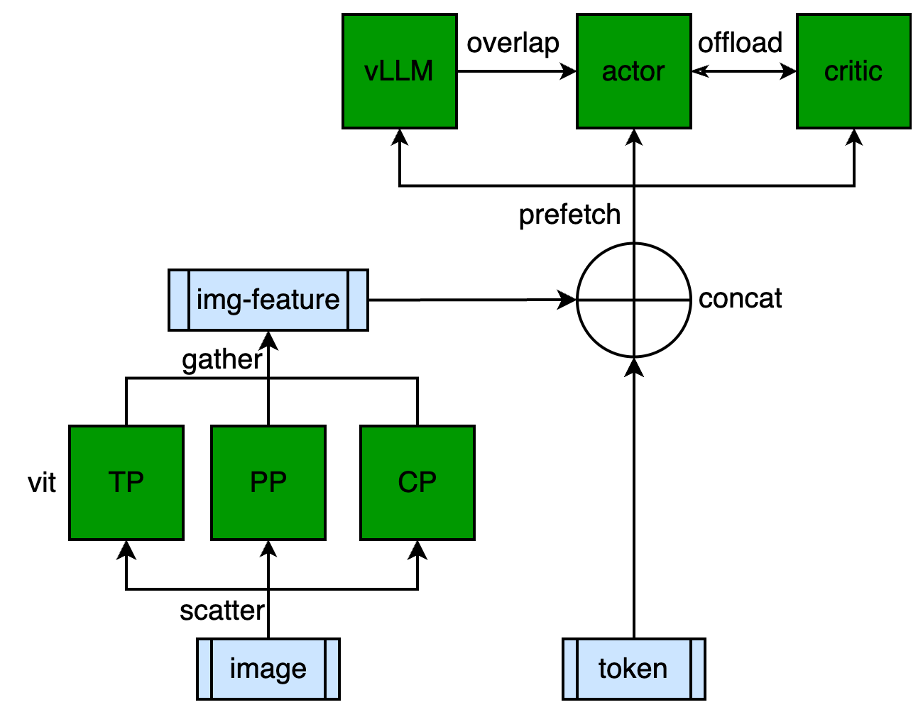
于子淇:多模态 LLM 对于 PPO 训练来讲有一定优化空间,视觉部分计算量大,但参数量较小,通过 TP/PP/CP/DP 的合并,把每个卡看做一个视觉部分的 DP,加速 TP*PP*CP 倍,另外,因为 RL 属于 sft 下游任务,多模 vlm 视觉部分一般不会进行参数更新,所以可以把该部分通过 prefetch 的方式看做数据预处理阶段,最终使得多模 MMLM 达到 LLM 文本模型的同等性能,性能相比原始实现提升 1 倍;
InfoQ:在效果评估阶段,团队采用了哪些指标来衡量 RLHF 训练的成功与否?
于子淇:RLHF 的主要指标包括 reward、value-loss、kl、response-len 等曲线,比如 reward 需要稳定上升,如果突变上升也是一个有问题的表现,可能进入到某一个 reward 的 hacking 状态;value-loss 需要下降到稳定区域,具备了一定的打分能力才能保证 reward 的健康上升;kl 是限制 actor 不要偏离初始 sft 太远的指标,所以如果学习健康应该是逐渐增加,到达稳定值可能就需要进一步提升 reward-model 的打分能力了;response-len 是一个重要指标,可能逐渐增加,此时即便 reward 上涨,也是不健康的表现,可能是进入到越长丰富性越好,打分越高的状态,但并非预期走势,得考虑加一定的规则惩罚或者增强 reward 的能力;
未来计划与技术展望
InfoQ:对于未来 RLHF 训练框架的迭代,您和团队有哪些规划或设想?
于子淇:我们对于 RLHF 训练框架的规划有两个大的方向,一个是训练速度优化,一个是算法探索;性能优化,还有一些可以突破的点,架构上对训练和推理深度流水线调度、降低不同 seq 的负载均衡;推理上结合内部自研的推理引擎,通过更强的投机采样算法,做进一步的 generate 优化;更长文本的支持等;算法探索上,随着大模型的发展,通过 CoT 打造更深层的推理提升模型,去探索 RL 的 scaling-law,去除 HF 人工部分,实现真正意义上的 RL
InfoQ:随着技术的不断演进,您认为 RLHF 在多模态大语言模型训练中还将面临哪些新的挑战?
于子淇:其实 RLHF 在架构实现上针对 PPO 训练已经是很高的复杂度了,比如为了安全角度增加 ptx-loss,就相当于在 ppo 训练的同时训练一个 sft 伴生训练;RM 部分打造更强的性能,也需要进行 step-reward 的计算,这些我们都支持了。
当然如果要有类似 o1 的 CoT 实现,可能会增加对训练的性能和效果挑战,比如长度上更长,训练和推理的性能平衡,流水线如何设计也是一大挑战;多模结构如果变更,也需要进行 RL 微调,那架构、并行粒度和性能上也需要重新调优;
InfoQ:您认为小红书大模型团队在 RLHF 训练框架上的探索和实践,将对公司在大模型方向上的探索和应用产生怎样的影响?
于子淇:我们团队自研的 RLHF 框架是业界领先的水平,也是得益于团队内部的合作、公司对我们的支持和认可,后续我们会打造更强的 AGI 大模型,赋能公司;我们观察近期行业进展,强化学习在 VLM/LLM 的 post train 阶段对效果有关键提升;内部业务使用上,我们也发现在人肉做一些 self-play 的工作去提升模型效果,所以我们相信后面基于 RL 的 self-play 是进一步迭代式提升模型效果的关键技术。我们还认为 RL 是 OpenAI 的 o1 的核心技术,能够有一套高效、可迭代的 RL 框架,并且有能力进一步迭代和优化,对公司未来继续在大模型上继续探索,有关键作用。




