
在 2025 年,对 GitHub 来说,更像是一场“回归之后的再出发”。
一方面,它不再是一家独立运作的公司,而是更深地回到了微软体系之中,与 CoreAI 绑定;另一方面,一位新加入的负责人,开始在这个节点上,为已经走到一半的变革给出自己的理解与方向——他就是刚从 Vercel 离职、以 V0 等产品闻名业界的 Jared Palmer。
在他走马上任的同一时间点上,GitHub 正在对外释放两条同样重要的信号:
第一条,是在 Universe 2025 上正式发布的 Agent HQ——把 Anthropic 的 Claude Code、OpenAI 的 Codex、Google 的 Jules、Cognition、xAI 以及自家的 Copilot 等第三方编码代理,统统拉进同一个“任务控制台”;
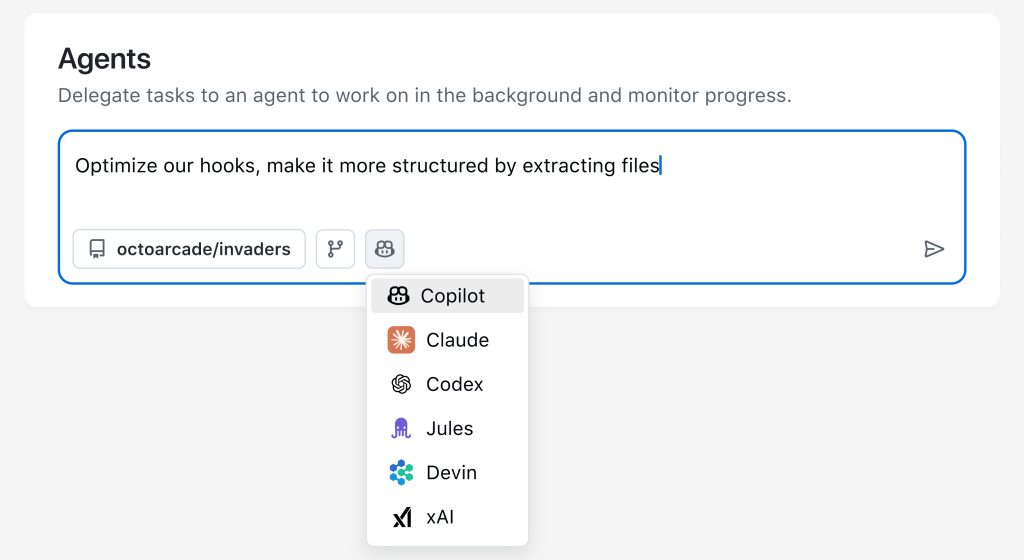
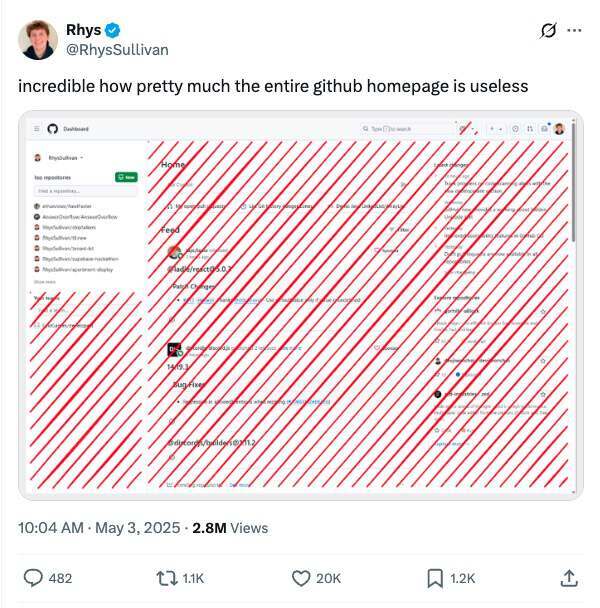
第二条,则源自一条颇具杀伤力的吐槽推文:“整个 GitHub 首页几乎完全没用”。
这条由开发者 Rhys 发出的帖子,在 X 上收获了 280 万次浏览、约 2 万点赞、1100 多次转推、近 500 条回复和超 1200 次收藏,直接把 GitHub 首页推上了“公审台”。围绕这条吐槽,GitHub 随后完成了首页重构:让首页不再是“大家随手点掉的一页”,而是承接任务、PR 与最近活动的真实工作起点。
表面上看,这只是两个互不相干的产品更新:一个是多代理管理,一个是入口体验优化。但结合 Jared 在这场采访中的讲述来看,这两件事其实共同透露出一个非常明确的方向——
GitHub 正在重新定位自己在 AI 时代中的角色:从代码托管平台,走向开发者与智能体共同工作的统一中枢。
简单来说,首页改的是入口,Agent HQ 改的是底座。两者共同构成了 GitHub 在 AI 世代的下一条主线:让开发者与智能体在同一个统一环境中协同工作。为了更好理解 GitHub 在这一轮演进中的思路,以及 Jared Palmer 如何从 V0 的实践走向 Agent HQ 和 GitHub 的平台化愿景,我们翻译并整理了他最近的一次公开采访。
以下是采访翻译:
Swyx:说起来,您提到过想要重新设计 GitHub 主页,能具体说说吗?
Jared Palmer:我们团队有认真审视,根据反馈做了改进,让新版主页得以落地。
现在的版本,在页面最上方增加了一个“任务区”,会集中展示你当前要处理的事项——最近的 PR、待你跟进的工作,同时也保留了很多人已经习惯的“最近访问仓库”等信息。整体的信息结构做了比较大的重构,不再只是一个“装饰性首页”,而是一个你每天点开 GitHub 时,真的会用、会依赖的起点。
老实说,我觉得还有不少可以继续打磨的地方,但这次的改版已经让人眼前一亮了,我自己也为团队感到非常自豪。当然,产品永远没有“完成”的那一天。接下来我们也希望能和社区一起,不断迭代这个首页。
Swyx:目前您同时担任 GitHub 高级副总裁与微软 CoreAI 副总裁,身兼两职会不会让您有别扭的感觉?
Jared Palmer:我才上任十几天,还处于适应阶段,不过目前来讲算是一切顺利。
Swyx:在加入 GitHub 之前,您曾经创立 Vercel 并打造 AI SDK,并担任 v0.dev AI 副总裁。能不能聊聊这段经历?
Jared Palmer:没问题。整个 AI 项目发展理念的基本脉络,就是从早期的单一编程智能体到如今为所有编程智能体建设活动空间。我觉得这也基本概括了 Agent HQ 的核心理念。
过去这两年,我专注于构建 Vercel、v0 和 AI SDK,并在今年夏季休息一阵之后加入了 GitHub,前段时间又推出了 Agent HQ 等项目。
我们希望 Agent HQ 不单成为智能体的活动空间,更成为开发者的聚集地,成为我们构建的全新协作环境的运转中枢。
用 v0 的经历打造 GitHub?
Swyx:在 GitHub,您能实现哪些原本 v0 做不到的事情?
Jared Palmer:GitHub 这个平台体量可观,坐拥 1.83 亿用户,其中有开发者近 1800 万。而 v0 不仅关注单一语言,更是聚焦特定框架与问题域,通过内置渲染器为特定场景服务。有些朋友可能还不了解 v0,这是一款由 Vercel 开发,类似于 Lavable 的氛围编程工具,但主要面向 Next.js 应用的生成。这种聚焦度让团队获得了更大的自由空间,如激光般直捣希望实际的核心目标。而在 GitHub,我们开始为所有语言、框架和开发者构建活动空间,因此视野也更为广阔。这种指向性的差异就是最大的区别。
Swyx:您几乎涉足了编程智能体的整个发展过程,那您自己在其间的成长轨迹又是怎样的?
Jared Palmer:我在很多场合下都不止一次回答过这个问题,而每次回忆好像都会解锁大脑中不同的记忆片段——所以咱们不妨就从记忆检索机制聊起。
智能体的记忆机制就很奇妙,类似于闲逛时偶尔会发现新路径的感觉。总之大概的过程是这样:当初 ChatGPT 甫一问世,就给从业者们带来了巨大震撼,堪称是改变世界且增长迅猛的革命性产品。
回顾自己的履历,我意识到自己其实很早就开始在 Vercel 涉足 AI 领域,但最早的时候公司根本没有 AI 部门或者团队,我担任的是所有框架的工程技术总监,并通过 Turborepo 等内部开发工具协助 Next.js 团队进行内部测试,验证服务器操作的初始实现。
那会就有人提议:与其开发待办事项应用,为什么不打造一套实验平台?我立马觉得这事可办,于是侧重出了 AI 实验平台,也就是如今 AI SDK 的组成部分。通过对各家模型提供商和组合方案的研究,我为 AI SDK 找到了这样的定位:专注于我们擅长的用户界面领域,同时不干扰用户的其他操作。于是我们先发布演示平台,随后正式推出 AI SDK。到 2023 年夏天,整个原型开发由此进入快车道,公司内部也达成了全面转向 AI 领域的共识。
记得当时代码执行功能刚刚上线——名叫 Inter Code Interpreter,也就是代码沙箱解释器。我看到这项功能后,立刻萌生出一种雄心勃勃的构想,意识到如果能以某种工具调用机制在 4000 个 token 的上下文窗口内实现以下功能:根据提示词直接进行代码解释、渲染 UI 界面、生成文档或者直接在聊天框内生成内容,那么开发体验绝对会进入全新的时代。比如生成不同类型的交互界面,或许还能串联输出,比如把代码解析的输入作为下一条提示词中的一部分之类。这个想法虽然疯狂,但本质上跟工具调用并无区别。
随着技术发展逐渐明朗,我们开始内部商议,到底该不该向代码解释功能开放数据抓取能力。虽然现在大家觉得无所谓,但当时为它提供网络访问权限确实有点可怕。最终我们决定放弃代码解释功能,只保留最酷炫的 UI 生成方案。这种直接用提示词就能输出界面的能力,堪称是 v0 项目的顿悟时刻。
最早的 v0 记得是在 2023 年 9 月发布的,而且观感上更类似于 Midjourney。时间快进到产品上市九个月,我们的小团队用了三个季度才达成百万级别的 ARR(年度经常收入)。随着模型持续迭代,我们也先后尝试过更多新模型,但不知道为什么,GPT-4 Turbo 始终没法成功接入。在转用其他前沿模型之后,我们最终开始自研模型。
继续快进十个月左右,我们重新回归聊天功能,终于让模型能够处理聊天任务。到这个阶段,我们意识到重构的最佳时机已经到来,v0 也由此迎来新版。这时候项目的营收开始猛增,短短 14 天 ARR 就增加了百万,又过 14 天再度增加百万。
我们不断精进优化,更重要的是期间我们始终专注单一技术栈和框架。那时候其他团队都在尝试通用编程智能体,而我们坚持只关注 Next.js 前端与 Shadcn,这也让团队得以聚焦核心。
公平地讲,Next.js 的统治地位让这种定位获得了强大的吸引力。而我们对包括 UI 库和组件在内的各种细节进行专注打磨,也带来了巨大优势。我们还开始与各大前沿模型实验室合作,确保他们的模型获得愈发强大的 Next.js 生成能力。而我们也把自己开发的后训练框架与其他模型实验室共享,并对所有数据进行严格处理,确保处于最优状态。
Swyx:那你们有没有讨论过在 v0 当中融合不同模型的优势特性?
Jared Palmer:那肯定是有的,包括到底该提取各种模型的最佳特性并集于 v0 一身,还是提供模型选择器以帮助客户自由切换。我们确实反复讨论过这些方案,最终发现这两种方式各有优劣。打造自研模型或者说复合模型的优势,在于可以自由组合这些元素。另外值得一提的是,搜索模型和生成模型完全不同,二者本质上属于两个独立的子系统。搜索模型可以完全独立于生成模型运行。
所以我们现在的解决方案是,不提供模型选择器,而是通过自研复合模型实现不同优势的结合。我认为这应该是更好的方式,一方面是可以把成果作为产品进行品牌化推广,另外也能把我们的业务跟前沿实验室的发布剥离开。
再说说模型品牌化,这么做的优势是我们可以跟模型提供商合作发布,把很多工作交给他们。但相应的问题是,我们能够提出的计费上限也就是零售价了,没办法进一步营造溢价空间。
Swyx:就是说我们很难通过高质量的客服等方式扩大服务收费。这就是理想与现实之间的两难——我们既需要建立可持续的业务模式,摆脱对模型实验室的依赖;同时还要切实保证效益提升,并想办法把二者整合起来。
Jared Palmer:是的。好在如今我们已经转向 GitHub,专注走上了模型选择的道路。我们手头能用的不光有 Copilot,还有第三方 Claude Code、Codex 和 Cognition,包括现在的 Agent HQ,可以说是鱼与熊掌兼得了。这种形式的效果非常好,也符合用户的最终需求。
没错,我认为已经不适合在模型层上做切换了,虽然当初我们的 AI SDK 就是这么起家的。
现如今,模型与智能体必须紧密绑定,达到高度平衡的状态。一旦使用泛型接口松散绑定,所有模型就会快速退化成最小公约数的水平。接触过智能体的朋友应该明白我说的意思,智能体对于抽象概念的处理远远超过聊天场景,其对应的是包含计算运行时和文件系统的循环系统。
这里再谈谈我对 AI 智能体的理解。这事我跟很多同行争论过,在我看来智能体本质上就是用?加上 for 循环编排的 API 请求。只是如今的编程智能体已经涵盖更多功能,比如 SDK、沙箱环境、文件系统、工具调用等等,这已经构建起了独特的智能体生态圈,我个人称之为编程智能体领域。甚至我认为 Claude Excel 智能体在本质上也是基于 Claude Code——我不太清楚具体的底层实现,但若真是如此也在意料之中。
再就是 Skills 模块,本质上属于 MCP 的捆绑版本。它同样高度依赖大语言模型,比如读取用户提供的 Markdown 文件,参考文件目录内容再自由发挥。这其实就是一种文件系统,对吧?
掌控 Agent HQ 后,会设置怎么样的发展路径?
Swyx:是的,这种新形态的文件系统真的很酷。最近两年编程智能体一路发展,您也亲历了整个过程。那从您掌控的 Agent HQ 入手,您希望这个项目未来如何发展、又从各种智能体中观察到了怎样的趋势?
Jared Palmer:这是个好问题。我认为 Agent HQ 和 GitHub 需要协同进化。
微软的一大优势,就是善于把同类成果更紧密地结合起来,比如新成立的 CoreAI 部门。再就是把 Visual Studio Code、GitHub 和部分 Azure 服务整合为一体。对我而言,Agent HQ 最酷的功能之一,也在于实现工作流的无缝衔接与流畅体验。从演示中可以看到,当在 Agent HQ 中发起任务创建 PR 时,只需单击即可在 VS Code 中直接打开该 PR,这种体验太棒了。
关于 GitHub 的未来发展,我希望能借此探索在哪些触点上更自然地引入 AI——比如如何解决合并冲突、能否自动弹出操作界面等等。这就是我对 AGI 的理解——深度融合。一旦操作出现错误,我们总会遭遇本地环境无法正常运行、工具却一切正常的窘境。所以每次执行推送时,我都希望能直接添加评论或者启动任务来解决这类问题。
我设想的是一种无缝衔接的工作流,让开发者无论是在移动端、Web 端、GitHub.com 还是全局编辑器中都能保持专注状态。这也是我接下来半年左右的主要研究方向。
Swyx:那 Dev Containers 呢,你觉得这项技术会不会成为行业标准?我不确定 Dev Containers 是微软还是 GitHub 搞出来的,我把它的本质理解为一种沙箱环境,也是 Docker 容器的轻量版本。VS Code 对它支持得很好,但在 VS Code 之外好像还不太普及。那你们自己会用吗?
Jared Palmer:其实我们自己就是用一些 K8s pod。这个问题属于对运行时的选择啦,微软内部在这方面标准上还在进行讨论。
目前有几个竞争方案,我们应该会在下个周期内找到答案。但你说得没错,Dev Containers 确实提供不少酷炫的功能:预装 VS Code,带文件系统,支持沙箱机制,兼容安全协议,还能直接对接 GitHub Enterprise,且支持随时打包部署。这些优势确实都很令人心动。在我看来,Cognition 和 Codex 等服务的首要痛点就是仓库配置——这恰恰是 Dev Containers 和 Dockerfile 擅长解决的问题。先运行这个、再运行那个,之后配置这个,最终执行那个……这也太麻烦了。
我猜迟迟解决不了的难点,在于无法预知仓库内容——比如开发者是否打包了 ffmpeg 库之类。如果只是 Next.js 库,那直接执行 pm install 就行。当然,这些都有办法做特殊处理,但通用容器本身仍然是个挑战。
话虽如此,我觉得自动检测和预判之类的工作还是有空间的。很早的时候我就想开发一款开源框架自动检测工具,可惜这个想法始终没能在公司里成为共识。我当时一直觉得,这样的工具不就该开源吗?自动检测本就是人人都需要的基础功能。但话说回来,好像大家各自开发也不太好,把默认偏好技术栈统一起来才是正道。
Swyx:好的。那您还有其他比较关注的协议或者标准吗?比如 MCP 今年的表现就很亮眼,还有其他像 A2A、ACP 这类有趣的项目。
Jared Palmer:MCP 系统规模确实庞大,特别是在数字化转型领域,正在成为许多企业客户的核心解决方案,并借此实现上下文扩展。
我们前阵子还发布了智能体定制化功能,用户可以在 Agent HQ 中通过提示词等方式针对不同任务定制智能体,再让这些智能体集成多任务处理器等组件。从平台角度看,这里的可扩展空间非常大,也让我倍感振奋。
Swyx:咱们继续讨论 AI 的话题。在计算机视觉应用方面,起步阶段大家都很兴奋,后来却发现速度慢还不够准确,占用的计算量也很大。好在改进的速度也是肉眼可见的。
Jared Palmer:没错,目前的开源视觉模型对极端案例的支持还不够好,似乎还有深入探索的空间。
Swyx:那在代码生成领域,许多人正思考如何从开发者协同到代理程度更高的演进路径——类似于 Claude Code 环境那种。就目前的情况看,下一步该迈向哪里?
Jared Palmer:简单讲,就是要做得更好。魔鬼藏在细节里,成功率从 90%提升到 95%、98%乃至 99%,难度会呈指数级增长。要完成这波转变还有很多工作要做。98%和 99%的准确率其实差距很大,大到每位用户都能感知到。
而且很多做 AI 产品的开发者可能没意识到,大部分参与者其实活在幻想中,对自家 AI 产品的糟糕表现浑然不觉。他们不会去认真测量无错误会话数量、请求丢失率、响应速率这些指标。Vercel 就一直非常重视且持续关注这方面指标,我们会每三个小时汇总关键指标和数据,其中无错误会话指标尤其重要,也决定着智能客服这类多轮交互应用的生死。
我记得 2024 年时曾经发过条推文:智能体技术的真正成熟不仅要依赖更智能的模型,更要依赖基础设施供应商的可靠性升级。这类服务跟数据库更新这类持续性服务不同,各厂商之间性能也存在差异,不同运行时长就是造成不同网关产品成功的原因,因此 OpenRouter 这类产品才能大获成功。毕竟可靠性问题迫使我们不得不经常切换供应商,借此回避停机。简而言之,我们当时的情况有点像玩游戏:所有数据实时涌入系统,我们只能根据数据波动调整工作状态,猜测第二天会不会突然就崩了。
这种模式帮了我们不少,我觉得其他团队也该把数据驱动方法用起来。
但令人惊讶的是,数据分析类工具仍然相对匮乏——至今我还没见到那种既能轻松生成精准分析结果,又能像添加 Slack bot 那样轻松使用的解决方案。
整个分析领域似乎仍停留在 BI 时代,这真的很奇怪。这个领域到现在还没被充分开发,所以我一直在关注转变到底何时到来。
Swyx:我还有个好奇的点,编程智能体能否应用于非编程领域?您有没有亲自实践过,具体做的是什么?
Jared Palmer:今年夏天,我帮我爸设计了一套工作自动处理流程。他手头有一堆 Excel 表格,就是财会那个方面的东西。我试着把 Claude Code 套用上去,结果它用 Python 生成了几个脚本,虽然有点小问题,但连我爸都觉得效果相当不错,整个流程跑起来也相当顺畅。
另外还有带智能体的浏览器,也很有破圈的潜质。
Swyx:那您用过哪些 AI 代理浏览器?
Jared Palmer:我目前主要用 Atlas,但还是更喜欢 Arc 浏览器的垂直标签布局。专业用户需要面对多种业务场景,所以需要频繁切换上下文。我自己就经常会打开上百个标签页,为此还专门开发了开源工具 Chrome Dump。它能把所有打开的标签页导出为汇总,把内容整理成 Markdown 再批量关闭。我一直觉得关闭标签页应该像写 Markdown 一样简单,但 Chrome 在性能方面还是有问题。我还尝试过用 Tori 框架开发,但 Tori 明确限制开发浏览器功能,就挺遗憾的。
Swyx:最后一个问题,您提到过 StackTips。这到底是什么功能,开发难度为什么那么大?
Jared Palmer:这个得慢慢解释。跟 Facebook 打过交道的朋友应该都听说过 Fabricator 这款工具。我们都很熟悉 PR 这个概念,编写代码、提交记录、发起 PR,合并后继续工作。但当组织规模扩大之后,我们会发现有些人对 Git 操作方式有着近乎信仰般的执着——比如总在强调 rebase 和 merge 的区别。有些人觉得重写提交历史实现线性整合更重要,也有些人认为该先创建合并提交保留分支结构。总之我虽然没在 Facebook 工作过,但之前曾经认真研究过构建系统。
Facebook 不仅自研过 Buck 构建工具,还开发过韧性的文件系统——对,他们不用 Git,而是采用自己的 Mercurial。如今这些系统已经高度定制化,形成了一个紧密耦合的整体。
Facebook 也不采用 PR 机制,他们有自己的开发哲学。最贴切的比喻是:想象每个 PR 都只包含单次提交。这样不仅可以对提交做拆分处理,而且还能重新进行堆叠。在后续修改时,可以将变更置于 stack 的早期位置,而这些 stack 的本质就是提交差异。在堆叠之后,可以随意合并最新提交或者其中的任意提交,提供更优雅的工作流程。这对单体仓库或者超大规模代码库来说简直是绝佳方案。
更进一步思考,我们甚至可以左右 stack 中的哪些差异需要 CI 测试——当然,这需要配合更复杂的配置。比如根据提交信息筛选,或者直接跳过某些分支。这最终会形成分组形式的代码 stack,对于代码审查非常友好,也能更从容地更新 stack 中的不同部分,简直太懂开发者的心思了。
目前市面上已经有几款工具支持这种模式,其中之一叫 Graphite。
整个 GitHub 社区一直翘首期盼这样一项功能,所以我也在加入 GitHub 之后把它当成了头等大事。而在回顾调查之后,我发现 GitHub 内部早就做过多次尝试,最早一次是在 2020 年,2022 年的那次尝试已经有了颇为成熟的方案。当时大家尝试把所有工作都在客户端完成,并在 GitHub PR 之外引入“stack”这一全新概念,只是因为风险稍高而放弃了。当时的内部讨论觉得这样的变革幅度太大,不适合推出。
目前我们已经召开过几次内部会议,努力将其纳入规划路线图,也期待跟大家分享更多进展。总之像 GitHub 这样体量的平台,要想支持全新功能绝非易事——既要考虑平台体量,也涉及 Git 的实现机制。但我们确实在积极探索。




