
研发效能,规模化已成
2026 财年对比 2025 财年,阿里云 CIO 线的产研效能呈现出一组清晰的跃升:前端人均有效代码量提升至 3 倍,后端提升至 2 倍;千行代码缺陷率,前端下降 30%,后端下降 55%。
数字背后,是在承接更多核心业务与 AI 创新、没有增加人力、最终落实到了业务价值 的多重前提下实现的。
在一个几乎所有团队都在谈论「AI 提效」的年份,这样的衡量指标和结果并不常见。
2026 年,「AI 提效」已经成为产研圈最急迫的词汇。它几乎被贴在所有季度汇报的第一页,却很少出现在真实的业务结果里。在笔者看来,背后有个结构性问题:大多数企业对 AI 的使用,停留在工具替换层面,而非流程重构层面。工具替换能产生局部加速,却无法带来系统性效能跃升。更隐蔽的危险是:当 AI 让代码生产的边际成本趋近于零,它同时也在加速放大流程中每一个错误决策的代价。
阿里云 CIO 蒋林泉及其团队这一年的实践结果,凸显在 AI 变革中的热情与理性。早在 2025 年 8 月,一次关于企业大模型落地的主题分享中,他就提出了一个判断:「技能通胀,品味通缩」。
八个字,浓缩了 AI 时代对组织和人才的价值迁移方向。
蒋林泉对「品味」有他独特的理解 —— 品味,是对业务价值的判断,对一件事情好与不好的最终验收;AI 只能做到 average,但有品味的人,能定义什么是「好」。
AI 时代,对「好」的判断力是稀缺的,相反,随着工具的普及,技能正在迅速失去稀缺性。Anthropic 的 Claude Code 的创建者 Boris Cherny 曾表示,软件工程师这一职位将在今年消失。企业正在从为传统的技能付费,转向为判断和结果付费。
肉眼可见,一年之后,蒋林泉的这一判断不再只是趋势预判,它在具体实践中逐渐被验证、被放大。围绕产研组织的能力结构与运作方式,其 CIO 团队完成了一轮系统性的重构。也因此,才有了这次他对 「AI 时代产研组织效能规模化提升实践」 主题的深度复盘 。
他把一年的成果与沉淀的方法称为“汇报”,成果的关键定焦在「规模化」, 毕竟个人的 AI 提效满天飞,组织效能的规模化提升,才是真难点。
两个流行误区,正在让大量团队越跑越偏
「AI 生码率」一路攀升,真实项目的 E2E 产研时间却没缩短
变革都需要数据的侧面支撑,选择对标什么数据,本身是一种战略判断。
在阿里云 CIO 的统计维度中,看到的是人均有效代码量和千行代码缺陷率,并没有看到一个行业极其流行的指标:AI 生码率。
从硅谷大厂到国内独角兽,大家普遍炫耀生码率从 20% 攀升到 50%。蒋林泉从一开始就将这个指标排除在考核体系之外,他的理由非常明确:AI 生码率是「过程指标」,组织一旦观测这种过程指标,AI 就特别容易产生毒害。
他的意思是,代码行数如果「不加权」是没有意义的,这让团队很容易陷入「灌水」的陷阱 —— AI 生码率看起来很高,但实际上对业务效能毫无帮助。相反,他坚持,代码最终要转化为真实的业务价值。 这也是最开始强调的产研效能数据提升的前提。
「AI 生码率」确实是个充满诱惑的陷阱。当我们重新审视这个指标时,发觉 AI 生码率的流行,折射的不是技术问题,是组织管理的认知困境:当一种新技术出现,最强烈的冲动是找一个可量化的指标来证明它有用。这种冲动本身无可厚非,但它产生了危险效应:用力「证明 AI 有用」,忽视了「业务效能提升」。
蒋林泉习惯用「业务价值 E2E 标准」,来看研发的实际效能,所以需要先正确度量项目 E2E 各环节耗时与代码复杂度加权耗时。
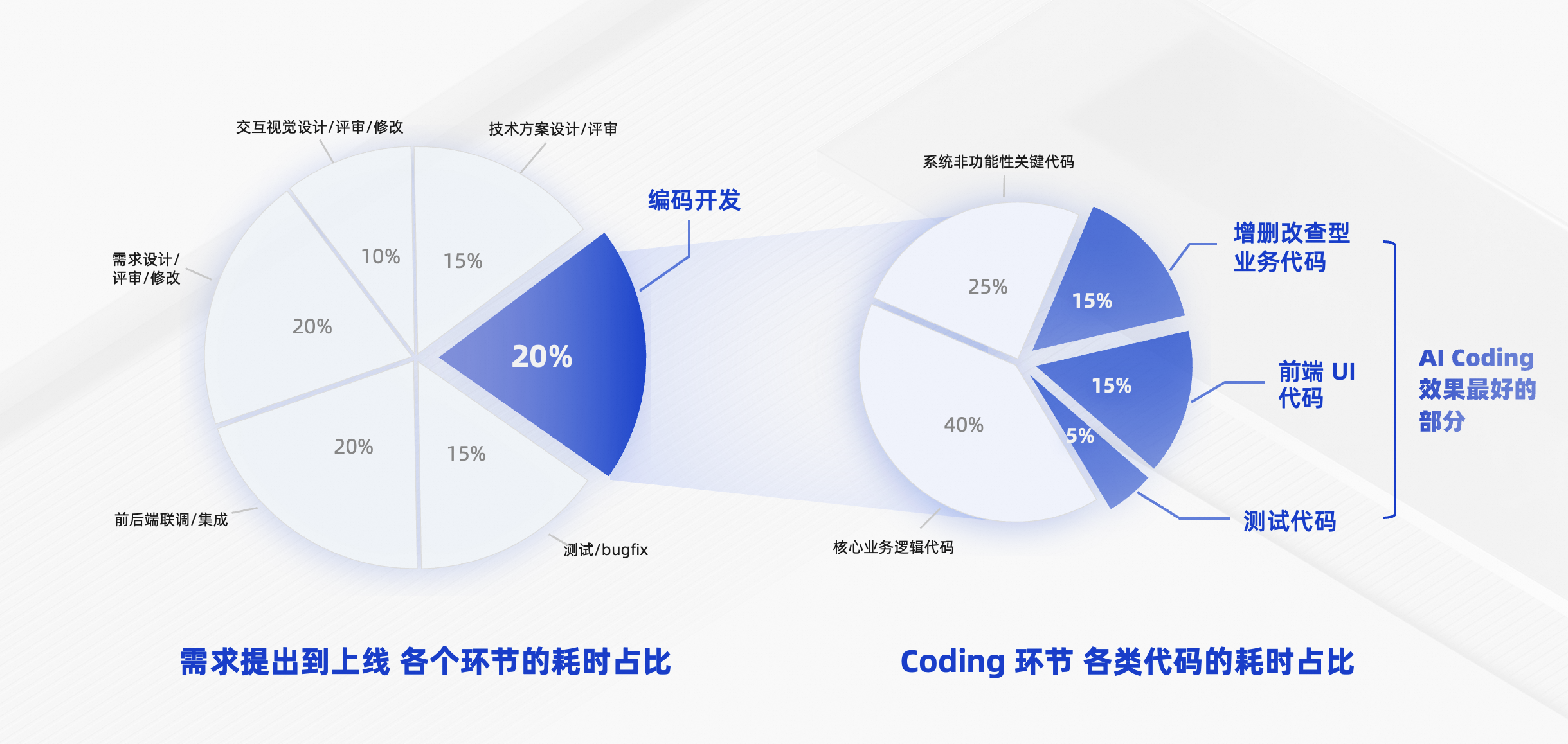
图 1: 正确度量 :项目 E2E 各环节耗时 与 代码复杂度加权耗时
从图中不难发现,在完整的软件工程生命周期中,开发人员实际编写代码的时间仅占 20%,大量时间消耗在需求对焦、PRD 编写与评审、跨团队沟通对齐、上下游联调及返工等环节。
即使在 AI 编码那 20% 的部分里,代码与代码之间的价值密度差异极大。 自动生成单元测试、补充注释、编写胶水代码——这些本身耗时有限。真正消耗精力的是核心概念、核心算法、核心逻辑及上下游联调的整体解决方案。那些代码量虽少,但精力投入度极高。
两个漏斗叠加:时间大部分不在编码上,即使把那些容易的代码做到了 70%、80% 的 AI 生码率,整体的端到端效能提升,依然可能非常有限。 这是蒋林泉想直观分享给大家的事实。
问题是什么?AI 生码率指标,它恰好在最容易被优化的地方,是整个软件交付链路里,价值密度最低、最易被 AI 替代的一段。如此,用最容易被替代的环节,来衡量整体效能,是第一个误区。
Vibe Coding 快速搭建新应用 VS 企业存量主力老系统中无法落地
与「AI 生码率」类似的另一个误区,是 Vibe Coding。
大家都非常兴奋于「用 Vibe Coding 搭个应用很快」,但放在企业系统,事情没这么简单。
蒋林泉认为,有两个区分至关重要:
做一个 Demo、个人应用,和做一个客户大规模生产系统之间,有巨大的差别;
做一个全新的应用,和在已有核心主力业务系统上叠加新需求,也有巨大不同。
“大部分公司不是一个创业公司,也并非在做公司的第一个应用。企业的核心应用都是存量系统,包括隔壁团队的系统也是存量系统。”这是实际。
他抛出这个直击本质的问题,让企业可以开始正视 Vibe Coding 的适用边界。
对于大多数企业来说,核心应用都是存量系统。业务复杂度极高,历史上积累了各种技术债务、不同人的编码风格;需要为生产稳定性负责,整个性能、可维护性都要关注。
但在这样的存量系统中,Vibe Coding 生成的代码无法直接大规模投入生产并承担质量责任。 对于需要为生产质量负责的场景,仍需投入大量工程精力。

图 2 : 正视 VibeCoding:适合与不适合的场景
因此,阿里云 CIO 团队的果断选择:不用「Vibe Coding 直接上生产」,采用「AI 辅助的软件工程」方式, 将 AI 作为提效工具融入规范化的工程流程中。
更深一层的思考,是蒋林泉在团队反复强调的一个逻辑:代码一旦生产出来,首先是负债。
这大概是技术圈细思甚恐的问题,被一语道破。如果生成的代码无法对业务客户产生正向价值,规模化地生产代码,本质上就是规模化地生产负债。毕竟,任何代码进入生产环境后,要即刻引入维护成本、增加系统复杂度,其与现有代码的依赖关系需要持续管理。代码能否转化为资产,即对业务客户产生正向价值,是不确定的。
他的经典逻辑是:增加的大量代码「可能」是资产,但「一定」是负债。
理解这一点,是后续全部 AI 工程实践的逻辑基础。
💬 同行之问:如果你也在被 AI 生码率困扰——
我们设计了一份「AI 同行人」交流意向,对于那些「看起来对、用起来不灵」的困惑,可以尝试对号入座、解决问题。
AI 破解「人月神话」与「左移」难题
很显然,流行的指标和工具,在企业的复杂系统里不灵,那效能的瓶颈该怎么解决?
从问题矛盾要走到解决方案,蒋林泉用实战经验给出的结论是:要回到最本质的产品规划和软件工程里,才能解决价值问题、可靠性问题和可用性问题。AI 终究是个手段,它放大了工程能力,但无法替代工程本身。
他的分析从《人月神话》开始。
书中那个经典命题:一个项目,假设原来需要 10 个人一年完成,能不能再加一倍的人,变成 20 个人半年时间交付?答案是做不到。
命题所揭示的核心悖论在于,增加人力并不能线性缩短项目周期,原因在于人际沟通复杂度呈几何级数增长,且新成员缺乏系统上下文、需要高成本的知识传递。
另一个他的高频词是「左移」。
以前大家一直说工程要左移 —— 在问题出现之前就解决它。但为什么以前没那么好贯彻?从多年的工程经验中,蒋林泉指出问题根本:左移的想法是对的,但投入太大、ROI 不够。左移本质上,就是「跨部门转移责任」。 也就是说,原来在右边承担责任的人,要把责任转移到左边,但左边的人接不接、认不认、有没有能力承担?这要付出巨大的软件工程能量,还有组织摩擦力。所以实际上,左移的难度非常大。
AI 时代的到来,改写了这两道经典难题。
关于人月神话:在组织里加人会有低效的沟通问题,但加 AI Agent 就不一样了—— Agent 可以无损地拿到上下文,能规模化地从已有代码里解析上下文,并不需要人与人之间低效的几何级数增长的沟通消耗。现在加 Agent 和原来加人是不一样的,原来的悖论在新时代的底层逻辑已不同。
关于左移:AI 时代里,原来那些上下文和知识资产,AI 可以从存量代码里抽取出来,再加上增量的 PRD、Spec 等上下文,业务复杂系统能够简化成一个大家可理解的上下文框架 —— 无论对新成员还是不同岗位之间,都能在一个业务链路里更低成本、更高效地对齐。

图 3:AI 时代,重新审视人月神话与工程左移
于是,有了如下四个显性改变。
左移「质量与测试」:测试覆盖从 20% 到接近 100%
过去,左移一直是「难而正确」的事,难点在投入。
以质量测试为例,要实现高覆盖率,第一步并不是写 Test Case,是先梳理业务链路、关键路径与场景覆盖度;第二步才是补齐测试用例。过去,这两件事都极其消耗人力。
AI 的介入,显著提升了这件事的 ROI。它可以辅助定义覆盖范围、识别异常路径与边界条件,也能快速生成大量 Test Case。阿里云 CIO 团队近期在有新成员加入的情况下,借助 AI 将测试覆盖度从 20% 提升到加权接近 100%。
这验证了一个判断:质量左移之所以多年落地不足,本质不是方向不对,是成本太高、过程太重。AI 让覆盖度梳理变轻,让测试编写变快,也让质量左移从“正确但昂贵”,变成真正可执行的工程实践。
左移「知识工程 + Spec」:存量系统的知识解冻还原
第二个关键变化,发生在知识工程与 Spec Driven Development。
在 AI 辅助下,团队开始有机会从既有老代码中,还原存量系统的核心 Spec;对于新增需求,也可以在更“靠左”的位置,通过规约化方式提前定义清楚。AI 让沉淀在代码、文档和历史实现中的存量知识,有机会被重新抽取、结构化,并还原成一套相对完备的 Spec。
阿里云 CIO 团队为此投入大量精力,从存量代码、前后端代码、内部文档到客户使用文档中,挖掘系统 API、数据结构和业务流程,再按照规约模板,引导 AI 生成结构化的 Spec 知识库。
这相当于让存量系统重新拥有了清晰的上下文骨架。 它既解决了历史上下文难以传播的问题,也成为 AI 理解系统、参与编码最快的入口。
当然,会有人提出担心,Spec 会腐化、维护成本会成为新负担?蒋林泉给出他的一个观察:AI 生成的代码更规整,用规范化的代码还原 Spec,准确度越来越高,上下文一致性越来越好,于是,维护 Spec 的成本反而在下降,「文档与现实脱节」的老问题会随时间慢慢消失。
规约跨职能界面:API First 终结不良「代偿」
健身的人常谈 「代偿」,指的是运动中,目标肌肉未能充分发力,导致其他非目标肌肉(如协同肌)被迫过度参与动作。显然,企业的系统同样存在这样的代偿。
比如,产品经理 PRD- 前端代码与设计稿 - 后端实现的这个链路里,当交付压力到来,系统会出现一种常见现象:“谁最急,谁就去补偿。” 蒋林泉认为,这很像健身中的「代偿」,很多系统问题,正是长期不正确的职责补偿沉淀下来的「结构性债务」。
这会导致什么?看起来是职能分工很清楚,实则不清楚——该分工的地方,在现实世界里是耦合的。 同一个业务逻辑有可能分散在前端、业务编排层和底层数据库中,三者叠加才能勾勒出完整的业务全貌。这是为什么,API First 被讨论多年,但一直很难落地。
AI 带来了关键转变:辅助团队规模化排查系统中不合理的职责分布,并解读存量 API: 哪些 API 职责重复、边界不清、语义混乱?哪些业务逻辑被错误地分散在不同系统中?
阿里云 CIO 团队为此将现有后端 API ,全部还原成一张完整的 API 注册表。只有先把存量 API 整理清楚,增量前端系统和集成系统,才有可能基于清晰的 API 语义进行客户端编排。
Vibe Coding 左移确认:需求澄清大幅「前置」
还有一个变化,发生在需求澄清环节。
前面谈到,Vibe Coding 未必适合直接进入存量系统的生产环境,但在新增需求、新增应用中,它能找到了更有价值的切入点:让需求澄清大幅前置。
过去,业务方常常只抛出一句「我要这个」,产品经理在多轮沟通中反复澄清,最后仍可能形成一份模糊的 PRD。等到上线后,业务方一句「这不是我想要的」,就只能返工或勉强接受,消耗巨大。
新的解法是:既然 AI 可以快速生成原型,虽然不能直接上生产,可以把原型作为直观载体,用 Live Demo 与业务方对焦。
「所见即所得」的需求确认,把原本上线后才发生的验收,前置到需求最左侧。业务方不再只是阅读文字描述,是直面一个可交互的原型,判断这是不是自己真正想要的。Vibe Coding 让需求确认大幅提效,从源头减少理解偏差、需求返工与系统性浪费。
💬 同行之问:质量左移、知识工程、API First、需求前置——这几个方向,你的团队在突破哪个?
最大的卡点在哪? 还有哪些想与技术管理者「闭门碰撞的话题」,可以参与「AI 同行人」交流意向。
灵魂 x 骨架,定义问题,就已解决问题的 90+%
蒋林泉一直强调 AI 对“左移”的推动,还有更根本的维度:一切终究为了业务价值。
他用一套比喻,来定义有效的产品和业务价值:「灵魂 × 骨架」。
「灵魂」指向业务价值。如果做了一个软件,上线后有没有在端到端的业务闭环中产生业务价值,是关键。如果没有,那 AI 做得再多再快,也不过是在批量生产没有闭环的东西。
「骨架」引申为核心概念与 API 建模。可以理解为,从核心的原子模型出发,厘清数据结构、状态机,以及操纵它们的 API 动作。
一个是灵魂,一个是骨架,两者要加在一起。
“我心目中,一个软件的长期价值,灵魂和骨架可能要占到 90%,剩下加起来才是那 10%。只要在「最左侧」是对的,后面的交付就会越来越容易。这是正确地定义问题。”
如果再上升一个维度,是:Effectiveness × Efficiency。 一个是全切面的加速器,包括测试、运维、编码、存量系统梳理等等,这视为 Efficiency;一个是强调「做对的事」,避免 AI 生产债务,确保形成闭环的价值,解决业务问题,这视为 Effectiveness。源于此,他常对团队讲,要忘掉岗位和位置,去看任务和目标。

图 4:最左侧: 用「灵魂 X 骨架」定义有效产品
有意思的事正在发生。业界开始流传:已经不是「写软件」,叫「跑软件」。
按照刚才所谈的逻辑,把需求和数据结构在左侧定义清楚,抛给 Agent,让它跑上两天,出来的也许就是一个可以「上生产」的软件。
Anthropic 年初发布的 2026 Agentic Coding Trends Report 将这一演变数据化,开发者当前有约 60% 的工作环节已使用 AI,但能完全委托给 Agent 的任务比例仅在 0%-20% 之间。「跑软件」并非甩手不管,是聚焦左端做好 Agent 编排与把关。
大趋势下,蒋林泉把「技能通胀,品味通缩」这个判断,推向更极端的版本:在 AI 时代,定义清楚一个问题,这个问题可能就解决了 95%。
他甚至给出更大的可能性,按照当下 AI 的能力和进化速度,我们定义问题的这一「最左边」的权重,可能会从 95% 进一步逼近 99%,甚至无限趋向 100%,这也许就发生在下一个财年到来之前。他鼓励团队要“坐稳,扶好 ”,速度的画面感扑面而来。
放弃全栈,用「Half-Stack」重构岗位
新生产关系:PDFE 与 ABE
当生产力变了,一个组织的紧迫课题是新生产关系。
近来,「一人公司」、「AI Native」型组织兴起,全栈工程师的概念再次流行。蒋林泉对这股热潮做了一番理性观察:大部分硅谷的一人公司,要么是价值链极短的,(比如自媒体创业),非复杂的业务链路;要么是做全新应用,非规模化的存量生产系统。
业务高度复杂的企业系统,做不到极少数人;规模化的生产系统,也做不到极少数人。
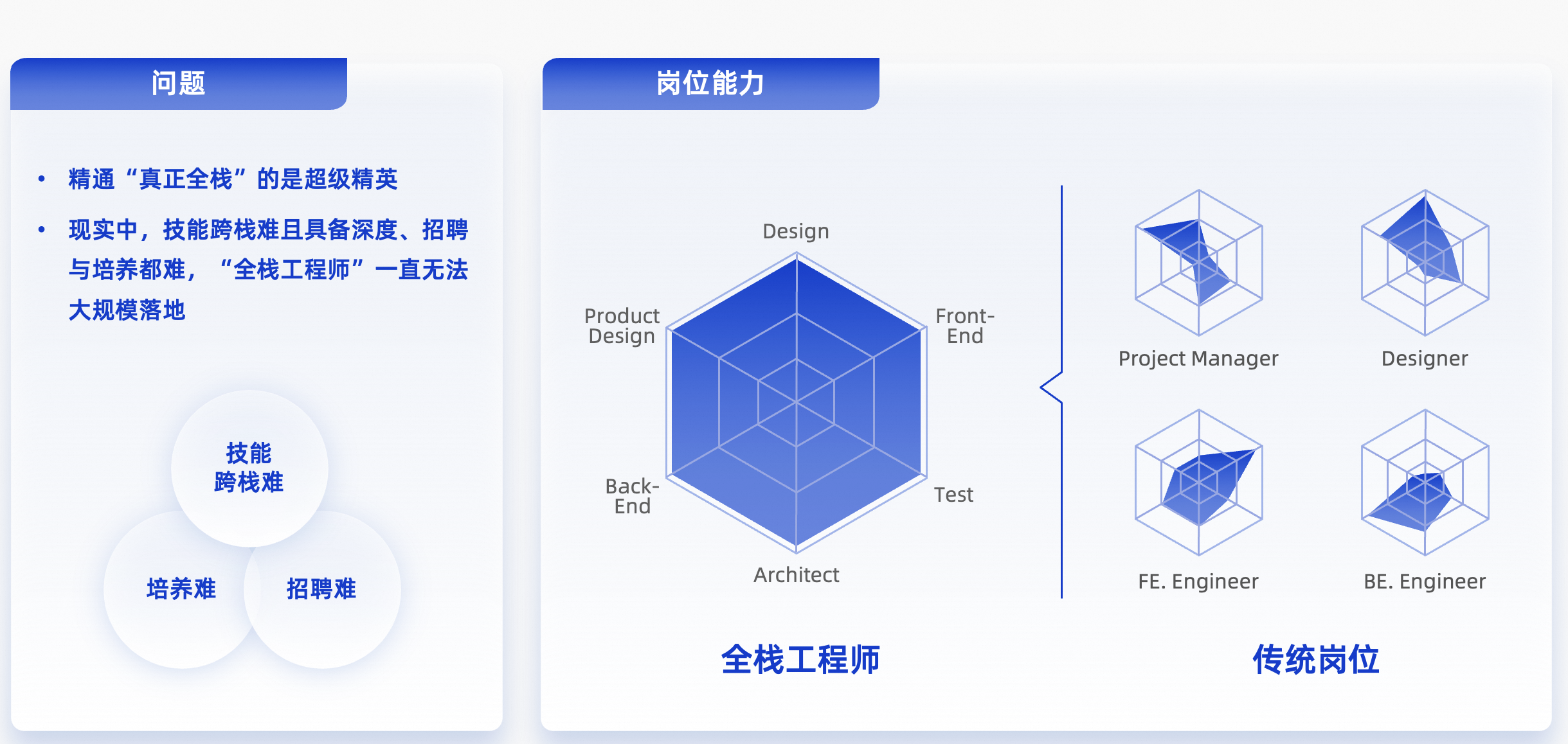
图 5:AI 时代,反思「全栈工程师」
这又回归到,对全栈工程师的追逐。全栈概念每隔几年就会重新流行一次,这次借 AI 东风,声势更大。但蒋林泉和众多企业 CXO 交流下来,大家的答案一致:这种高手,企业招不到。背后原因不难理解,全栈型人才天然是极少数,对其而言,比起加入一家普通的规模化公司,创业是他更好的选项。
所谓一人公司和全栈工程师,对人有要求,对业务有要求。寻找全栈人才,注定是例外,非解法。
蒋林泉给出的解法是:不去妄想全栈,最大限度利用 AI 降低跨域门槛,重构新阶段的「Half-Stack」岗位。 基于此,阿里云 CIO 团队将核心岗位收拢为两个:PDFE(AI 产品设计前端工程师) 和 ABE(AI 架构与后端工程师)。
两个岗位名称清晰直接,透露出岗位该有的能力域:
PDFE 的前身是原来的产品经理、交互设计师和前端工程师三合一。这个角色负责从业务沟通到 Demo 确认,再到 API 对齐和前端开发。这一变革带来的是效率的质变,比如,原来至少需要两周的对焦迭代周期,变成半天的协同确认。
ABE 则是把架构设计、后端开发和 AI Agent 开发融合在一个角色。本质上,它们都在解决数据结构、状态机、API、高可用和高可靠的问题。这里,ABE 强调后端不仅仅是写代码,还要解决架构的有效性和稳定性。
PDFE 和 ABE,表面上看是「岗位合并」,但底层逻辑是对组织设计的重新思考:过往技能深度是划分职能的主要依据——前端守前端,后端守后端,设计守设计,每个人在自身的技能领域里求极致。但这个逻辑在 AI 追平技能的情况下,开始松动。看得出来,PDFE 把握的是从业务意图到用户界面,ABE 守护的是从数据结构到系统稳定性。两者之间的接口,是 API 契约。
最终,「Half-Stack」带来最直接的变化是,协同链被巨幅压缩——职能压缩、技能岗位压缩,沟通链路几何级数下降。 蒋林泉也坦言,“这样的组织分工,结合 AI 的辅助,才是我们效率提升最主要的来源。”
💬 同行之问:Half-Stack 模式,你的公司能复制吗?
岗位合并背后,哪些是真阻力、哪些是认知误区?我们在收集同规模企业的实战反馈,并会匹配相近处境的同行展开闭门交流,可以参与「AI 同行人」交流意向。
三位一体:沉淀下来的组织变革过程
这套 AI 时代产研组织效能规模化提升实践,最后被总结为一个完整框架:产品价值牵引 × 工程效率 × 组织变革。
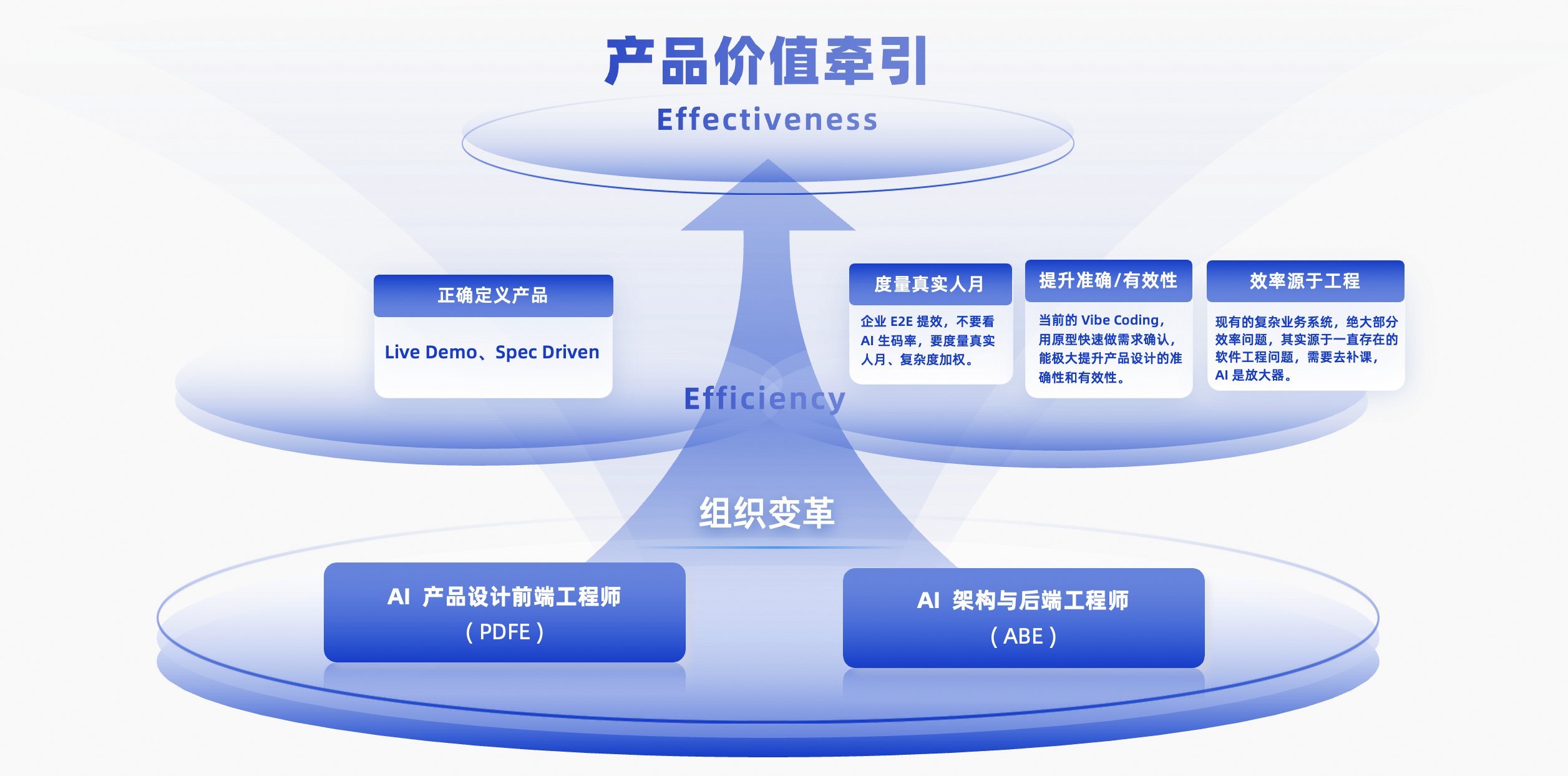
图 6:AI 时代产研组织效能规模化提升框架
可以这样理解:武器越厉害,越需要看清什么时候用它、什么时候不用。
AI 就是这样,如果没有价值,等于在错误的方向上狂奔,AI 生产再多也只是视同垃圾。就像代码一旦生产出来就是负债,其价值是不确定的。所以,首要是把更多精力放在价值确认,避免规模化的生产负债。用蒋林泉的话,“落到结果上,比代码倍增更重要的,一定是业务价值的倍增。”
在价值牵引下,AI 辅助提效工程——通过存量系统上下文还原、Live Demo 辅助、质量左移等手段;进一步,基于上层的价值牵引和 AI 辅助,使组织变革成为可能,自然就会形成最符合生产力发展的生产关系 —— 收拢在 PDFE 和 ABE 这两类职能。
这样,价值 - 工程 - 组织,形成三位一体。大家看到这个「三位一体」的框架,只是一张平面照片,但在阿里云 CIO 看来,这是一个视频,一个复杂的过程。
未竟之问:AI 时代的工具、组织与人
这场 AI 变局里,从 AI 工程热潮到 AI 理性回归商业价值,再到产研组织的 AI 转型自救,波及到每个人、每个组织。最后,文章以番外的形式,分享阿里云 CIO 关于人和组织的一些独特见解,尝试为同行人拨开一些 AI 时代的迷思。
工具:Agent 做出来容易,为何产生价值难 ?
当下,很多企业陷入「Agent 囤积症」 —— AI 工具供给急剧过剩、但价值产出严重不足。
人人都觉得 AI 工具“应该有用”,但有企业高管坦言,真实情况是,从上往下推不动、从下往上也走不通,AI 在「能行」和「怎么行」之间,始终缺一条路径。
封装一个 Skill 只要 5 分钟,但让它产生真实业务价值是个问号。这背后,Skill 的本质是什么?它是把完备的数据、API 和 Prompt 的封装门槛下降了。但是,封装门槛下降了,封装垃圾也容易了。因为「对的东西」终究是少的 。所以,价值从来不在人人都可以包装 Skill 和 Agent 调用的能力上—— 价值在背后的数据是 Ready、工具是否成熟、写 Prompt 的头脑是否清醒。
组织:个体提效与组织提效,有何不同 ?
AI 工具正在疯狂赋能个体,但个体与组织提效却是冰火两重天。个人生产力可以轻松扩张 50 倍,但企业的规模化提效隐晦不明。
事实上,个体与组织提效是两个不同的赛道。
个体提效一般有两种管理路径:一种是任务量不变,效率红利转化为员工幸福感;一种是追加任务量,转化为更多产出。但后者的问题在于——个体产出的质量和业务贡献,很难在线实时度量,也很难形成可复制的闭环。个人可以快,但不等于「对组织有效」。
对比看,组织提效,属于整个企业端到端的业务大闭环,需要把这两个赛道分开来看——不能单独依靠个体提效,需要解决真正的组织瓶颈。
人:AI 世界,真正稀缺的能力 ?
无论组织还是个体,人的能力是驱动 AI 世界的核心变量。
基础回归:语文 × 数学 = 超强理解和无损抽象
一个具启发性的观点是:AI 时代工程师的底层能力,正在回归最基础的「语文」与「数学」。
这是基于大语言模型的逻辑:语文能力,代表着精准的阅读理解与表达——既能准确地将意图传递给 AI,又能敏锐地理解 AI 的输出,这与 LLM 的输入输出逻辑如出一辙。数学能力,则代表着“无损压缩”的抽象能力——如何将复杂的业务意图压缩为精确、可执行的结构,在极度精简信息的同时保留其内核。
品味至上:定义问题 X 驾驭 Agent
基础逻辑之上,更高一层是对 Agent 的驾驭。分两部分:第一,驾驭 Agent 团队——开源社区和业界高手持续推高 Agent 工具的能力天花板,普通团队直接借力就能获得很高的水平;第二,定义最左侧——左移定义问题的能力,也就是定义需求、数据结构,把需求精准抽象表达出来,以及如何验证结果。
用蒋林泉给「品味」下的定义:“本质上,品味是人类对复杂世界的经验、抽象能力和责任感的结晶。AI 可以提升下限,但上限,永远靠人来定义。” 值得共勉。
最后:致同行人
文章到最后,值得回答一个起点问题:当所有团队都在谈「AI 提效」,为什么鲜有能够真正跑出「规模化」结果?
作为阿里云 CIO,蒋林泉带领团队实战 AI 几年,从 AI 业务转型的 RIDE 方法论沉淀,到组织研发效能规模化提效的实战思考,反复踩坑,反复总结,反复进化。
本篇“浓缩式”的《AI 时代产研组织效能规模化提升实践》思考分享,是他在过去一年中,用真实的业务数据换来的复盘真相。
AI 生码率是表象,E2E 交付效率是真相;Vibe Coding 是入口,Spec Driven Development 是主线;个体提效是起点,组织协同链压缩是关键。
当然,每家企业的业务形态、历史债务、组织惯性不尽相同。在 AI 时代的剧烈变革下,迷茫是常态,坦诚面对是同行的起点。
如果您的团队也在面对这些矛盾与问题,或希望了解「规模化提效」在真实环境中的落地细节,欢迎扫描下方海报二维码或点击链接「AI 同行人」交流意向,参与话题定焦,有机会与更多同行人展开深度交流的闭门会。





