
生成式人工智能才刚刚起步,但是正在以指数级的速度发展着。自 OpenAI 第一次发布 GPT-3 和 DALL-E 之后,就开始在人工智能领域大放异彩。
2022 年是文本到内容的生成年(又称 AIGC)。在 2022 年 4 月,OpenAI 发布了 DALL-E 2,在关于 CLIP 和扩散模型的论文中有所描述。这是第一次从自然语言的文本描述中创建逼真的图像和艺术。
四个月之后,初创公司 StabilityAI 宣布发布 Stable Dispossion,这是一个开源的文本到图像生成器,它能在几秒钟内创造出令人惊叹的艺术。它可以在消费级 GPU 上运行,在速度和质量上都有突破性进展。它的热度如此之高,以至于在 2022 年 10 月 17 日的种子轮中成为了独角兽。
2022 年 9 月 29 日,谷歌发布了 DreamFusion,用于使用 2D 扩散实现文本到 3D 的生成。同一天,Meta 发布了 Make-A-Video,它不需要文本和视频的数据,就可以进行文本到视频的生成。
不到一周,谷歌似乎回应了 Meta 的 Make-A-Video,首次推出了 Imaged Video,用于文本到视频的生成。
在过去半年的这一激动人心的旅程中,Midjourney 和 CogVideo 的重要性不容忽视。Midjourney 是一家独立的研究实验室,提供 Midjourney Bot,从文本中生成图像。CogVideo 是第一个开源的、具有 94 亿个参数的大规模预训练文本到视频模型。
在本文中,我将描述他们如何为 Stable Dispossion、文本到 3D 和文本到视频工作。另外,让我们体验一下无需编码即可实现令人惊叹的文本到图像的功能,看看接下来会发生什么。
Stable Diffusion 与 Unstable Diffusion
Stable Diffusion 引入了条件潜在扩散模型(LDM),以实现图像修补和类条件图像合成的最新分数,并在各种任务(包括文本到图像合成、无条件图像生成和超分辨率)上具有高度竞争力的性能,同时与基于像素的潜在扩散模型相比,显著降低了计算需求。这种方法可以显着改善降低扩散模型的训练和采样效率,而不会降低质量。
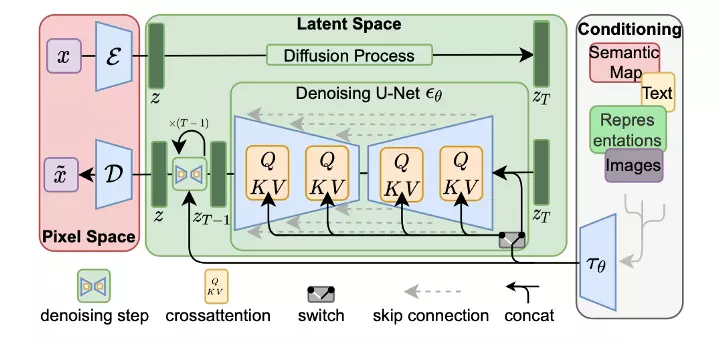
条件潜在扩散模型通过串联或更一般的交叉注意机制来解释(资料来源:潜在扩散模型)
在发布 Stable Diffusion 的同时,StabilityAI 开发了一个默认启用的基于人工智能的安全分类器。它在代中理解概念和其他因素,为用户删除不需要的输出。但它的参数可以随时调整,以实现强大的图像生成模型。
基于 Stable Diffusion,Mage 显示在浏览器中生成 NSFW 内容。它很简单,可以在没有 NSFW 过滤的情况下免费使用。
不要被混淆了。Unstable Diffusion 是一个支持使用 Stable Diffusion 的人工智能生成的 NSFW 内容的社区。毫无疑问,这些模型可以在 Patreon 和 Hugging Face 上找到。
用于文本到 3D 的 DreamFusion
谷歌和 UCB 共同推出了 DreamFusion,用于使用二维扩散的文本到 3D 的生成。
DreamFusion 的工作原理是通过新颖的 SDS(Score Distillation Sampling,得分蒸馏采样)方法和新颖的 NeRF(Neural Radiance Field,神经辐射场)类似的渲染引擎将可扩展的、高质量的 2D 图像扩散模型转移到 3D 域。DreamFusion 不需要 3D 或多视图训练数据,仅使用预训练 2D 扩散模型(仅在 2D 图像上训练)来进行 3D 合成。
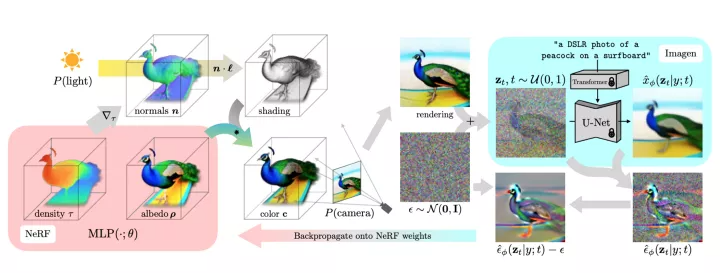
DreamFusion 演示如何从自然语言标题中生成 3D 对象(来源:DreamFusion)
如上图所示,一个场景由一个随机初始化的 NeRF 表示,并为每个标题从头开始训练。NeRF 用 MLP 对体积密度和反照率(颜色)进行参数化。DreamFusion 从一个随机的摄像头渲染 NeRF,使用从密度梯度计算出的法线,以随机的照明方向对场景进行着色。阴影揭示了从单一视角看是不明确的几何细节。为了计算参数更新,DreamFusion 对渲染进行了扩散,并用一个(冻结的)有条件的 Imagen 模型对其进行重建,以预测注入的噪声。
尽管 DreamFusion 产生了令人信服的结果,但它仍然处于文本到 3D 的早期阶段。SDS 在应用于图像采样时不是一个完美的损失函数。因此,在 NeRF 的环境下,它经常产生过度饱和和过度平滑的结果,并且缺乏多样性。此外,DreamFusion 使用 64×64 Imagen 模型来平衡质量和速度。
用于文本到视频的 Make-A-Video
Meta(又名 Facebook) 从来没有在人工智能的发展上落后过。在 DreamFusion 发布的当天,Meta 推出了 Make-A-Video,用于文本到视频的生成。
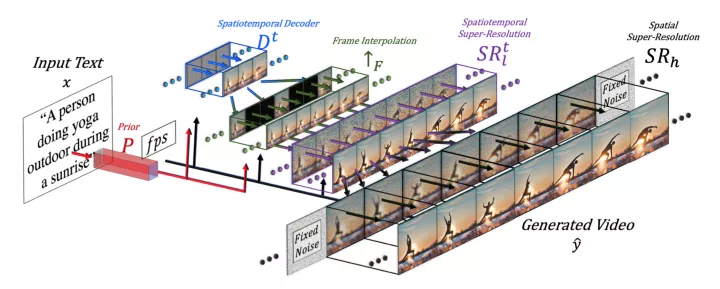
Meta Make-A-Video 高级架构(来源:Make-A-Video)
按照以上的高级架构,Make-A-Video 可以分为三个主要层:1) 一种基于文本 - 图像对的基本 T2I (文本到图像)模型;2) 时空卷积和注意力层,将网络的构建模块扩展到时间维度;3) 由时空层和 T2V 生成所需的另一个关键要素组成的时空网络ーー一种用于高帧速率生成的帧内插网络。
因此,Make-A-Video 是建立在 T2I 模型的基础上,具有新颖实用的时空模块。它加速了 T2V 模型的训练,而不需要从头学习可视化和多模态表示。它不需要成对的文本 - 视频数据。而生成的视频则继承了这种广阔性(美学上的多样性、奇异的描绘等等)。

谷歌的 Imaged Video
Google 的 Imagen Video 是一个基于视频扩散模型级联的文本条件视频生成系统。
给定一个文本提示,Imagen Video 使用基本视频生成模型和一系列交错的空间和时间视频超分辨率模型生成高清视频。
它由七个子模型组成,分别执行文本条件视频生成、空间超分辨率和时间超分辨率。整个级联生成 1280×768(宽×高)的高清视频,每秒 24 帧,持续 128 帧 (~5.3 秒),大约 1.26 亿像素。
Imagen Video 示例:“一束秋天的树叶落在平静的湖面上,形成文本‘Imagen Vide’。平滑。”生成的视频分辨率为 1280×768,持续时间为 5.3 秒,每秒 24 帧(来源:Imaged Video)
用于 Stable Diffusion 的无代码人工智能
如上所述,我们可以看到扩散模型是文本到图像、文本到 3D 和文本到视频的基础。让我们用 Stable Diffusion 来体验一下。
使用建议文本:亚马孙雨林中的高科技太阳朋克乌托邦

文本:动漫女机器人头上长满了鲜花

从空中近距离观察雷尼尔山

你可能等不及了,下面是许多无需任何代码就可以尝试的内容。
1.StabilityAI’s Stable Diffusion hosted on Hugging Face
2.Stable Diffusion Online
3.StabilityAI’s DreamStudio
4.Mage enabled with NSFW
5.Playground AI
6.Text-to-Image (Beta) on Canva)
7.Wombo Art
下一步是什么
生成式人工智能令人惊叹,并且正在快速地发展。虽然我们仍沉浸于文本到图像的真实感图像和艺术之中,但我们现在正在进入下一个前沿领域:文本到视频和文本到 3D。
但它还处于萌芽阶段,在相关性、高保真度、广泛性和效率等方面都面临着诸多挑战。
相关性:我们注意到,在相同的输入文本下,这些模型产生不同(甚至显著不同)的结果,以及一些不相关的结果。在创作艺术时,如何用自然语言描述输入似乎成了一门艺术。
高逼真度:DALL-E2 和 Stable Diffusion 中的许多逼真图像给我们留下了深刻的印象,但它们仍然有很大的高保真空间。
广泛性:广泛性是指美关于美学、奇幻描绘等方面的多样性。它可以为广泛的输入提供丰富的结果。
效率:生成图像需要几秒钟和几分钟的时间。对于 3D 和视频,需要更长的时间。例如,DreamFusion 使用较小的 64×64 Imagen 模型,通过牺牲质量来加快速度。
好消息是,它开辟了许多令人兴奋的机会。人工智能工程、基础模型和生成式人工智能应用。
人工智能工程:人工智能工程对于自动化 MLOps、提高数据质量、增强人工智能可观察性和自我生成应用内容至关重要。
基础模型:独立训练和操作许多大规模的模型是昂贵的,而且变得不现实。最终,它将统一或整合成几个基础模型。这些大规模模型在云端中运行,以服务于上述不同的领域和应用。
生成式人工智能应用:有了人工智能工程和基础模型,它是一个巨大的应用机会,包括元宇宙和 NFT 领域的数字内容。例如,创业公司 Rosebud 专注于多样化的照片生成。
到 2025 年,生成式人工智能模型将产生所有数据的 10%。我们可以预期,在未来几年中,随着人工智能生成进化的步伐,将会发生显著的变化。
作者简介:
Luhui Hu,@Aurorain 创始人,VC 投资者。曾供职于亚马逊、微软、Meta。在机器学习和数据云领域拥有 30 多项专利。
原文链接:




