
Netflix介绍了他们内部的一个自动化平台。该平台将近 400 个生产集群的 Amazon RDS for PostgreSQL 数据库迁移到 Amazon Aurora PostgreSQL,降低了操作风险和停机时间。该系统使服务团队能够通过自助工作流启动迁移,并强制执行复制验证、受控切换、变更数据捕获协调和回滚保护措施。
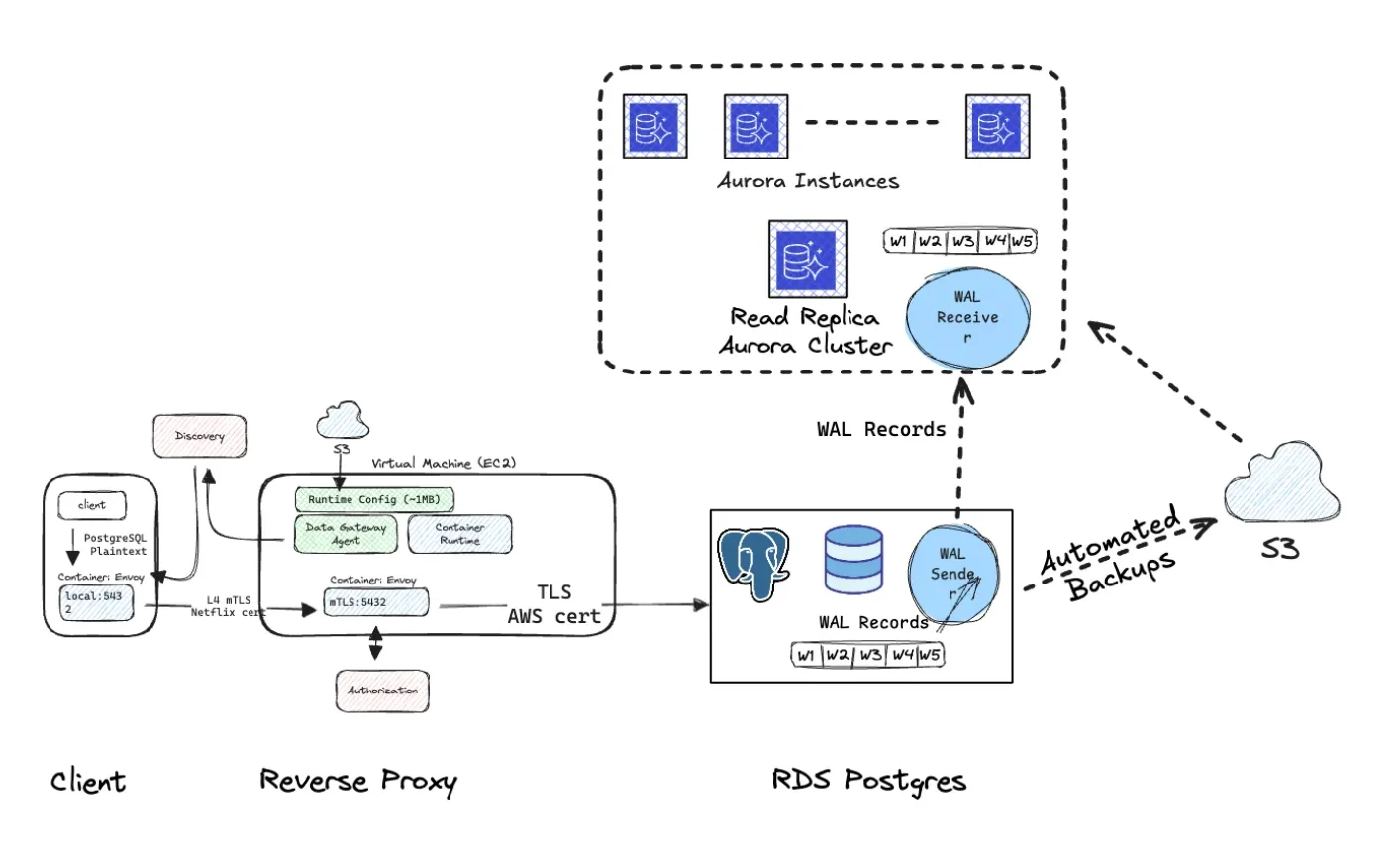
Netflix 通过一个基于 Envoy 构建的平台管理数据访问层路由数据库访问,这可以标准化mutual TLS并从应用程序代码中抽象出数据库端点。由于服务不直接管理凭据或连接字符串,所以迁移必须在该层之下透明地进行。因此,自动化机制完全在基础设施层面上协调复制、验证、切换、CDC 处理及回滚等操作。
Netflix 工程师强调:
我们的目标是使 RDS 到 Aurora 的迁移过程可重复且低干预,同时为事务型工作负载和 CDC 管道提供正确性保证。
首先,工作流借助Amazon Web Services的能力创建一个 Aurora PostgreSQL 集群,作为源 RDS PostgreSQL 实例的物理只读副本。副本从存储快照初始化,并持续重放从源流式传输过来的预写日志记录。在这个阶段,系统验证复制槽健康状况、WAL 生成速率、参数兼容性、扩展一致性以及生产流量下的持续复制延迟,确保副本在切换前能够承受峰值写入吞吐量。
RDS 到 Aurora PostgreSQL 的迁移工作流(图片来源:Netflix博文)
对于使用变更数据捕获的工作负载(包括逻辑复制槽或下游流处理器),自动化机制会在静默前协调槽状态。CDC 消费者将被暂停,以防 WAL 过度保留,同时槽位将被记录,以便提升后可以在 Aurora 上以正确的日志序列重建等效的复制槽。这既能保持下游一致性,又可以避免 WAL 堆积导致复制延迟增加。
Netflix Enablement Applications 团队是该平台的早期采用者之一,他们迁移了支持设备认证和合作伙伴计费工作流的数据库。在复制过程中,工程师发现,由于一个非活动逻辑复制槽保留了 WAL 分段而导致复制延迟增加,使得OldestReplicationSlotLag值升高。移除故障槽位后,复制过程趋于收敛,迁移成功完成,且切换后的指标与迁移前的基准值保持了一致。
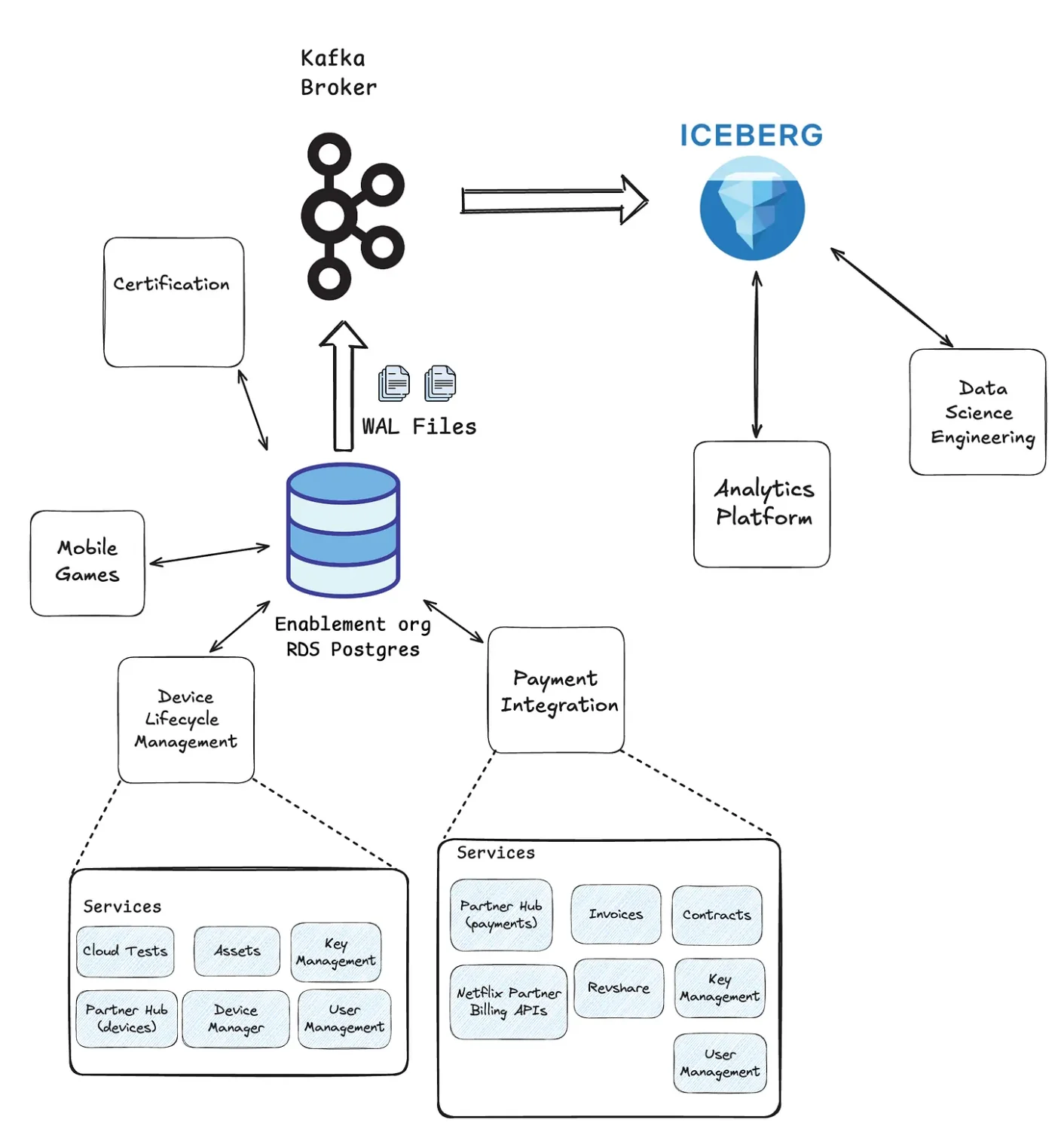
简化的 Enablement Applications 概览(图片来源:Netflix博文)
当复制延迟接近零时,系统进入受控静默阶段。修改安全组规则,重启源 RDS 实例以便在基础设施层阻止新建连接。在确认所有在途事务已成功应用并且 Aurora 副本已重放最终的 WAL 记录后,副本被提升为可写的 Aurora 集群,并且数据访问层将把流量路由到新端点。
根据 Netflix 工程师的说法,回滚被视为一个首要关注事项。在提升最终完成并且流量完全转移之前,原始 RDS 实例将保持原样,并作为权威数据源。如果在同步过程中验证检查失败,或者提升后的健康检查检测到异常,则流量可以通过数据访问层重新定向回 RDS 集群。由于应用程序与物理端点解耦,所以只要恢复路由配置就可以恢复之前的状态而无需重新部署。如果需要,CDC 消费者也可以从之前记录的原始集群槽位进行恢复。
原文链接:
https://www.infoq.com/news/2026/03/netflix-automates-rds-aurora/




