
作者 | Zhongzhu Zhou, Donglin Zhuang, Jisen Li, Ziyan Chen, Shuaiwen Leon Song, Ben Athiwaratkun, Xiaoxia Wu
从 KV Cache 瓶颈说起
长上下文模型的能力还在往前走,但在线推理服务遇到的压力,很多时候已经不只是计算量本身。每生成一个新 token,系统都要反复访问越来越长的历史 Key 和 Value;上下文拉长、batch 放大之后,KV Cache 同时吞掉显存容量和显存带宽。最新论文 OSCAR: Offline Spectral Covariance-Aware Rotation for 2-bit KV Cache Quantization 直接瞄准这个痛点,给出了一套面向长上下文 serving 的近 2-bit KV Cache 方案,并且已经接入 SGLang,可用于真实服务链路。相比之前量化的工作,比如 TurboQuant ,压缩的是向量,但忽略了真正影响模型的是 attention 的质量, OSCAR 保留的是 attention 真正会读的方向。 朴素 INT2 和全模型层的 3-bit K/V TurboQuant 都会在困难推理任务上明显掉分;OSCAR 在约 2.28 effective bits per KV element 下仍能接近 BF16,并在 Qwen3-4B-Thinking 上相对 3-bit K/V TurboQuant 最高提升 40.1 分。
如果历史 KV 能稳定压到 2-bit,理论上历史缓存的存储开销可以接近缩小 8 倍。不过,低比特 KV Cache 真正困难的地方从来不是“能不能压”,而是压缩之后模型推理质量不能塌,系统实现也不能停留在离线实验脚本里。OSCAR 的价值正是在这两个问题上同时给出了答案。
2-bit INT 只有 4 个离散等级,而 KV activation 里经常会出现少量幅值很大的 outlier channel。一旦量化尺度被这些极端通道牵着走,大部分正常值就会挤在很窄的有效区间内,attention 分布也随之偏移。普通 Hadamard 旋转可以把 outlier 打散,却没有区分模型在 attention 里真正使用的方向。OSCAR 的核心思路是:不要只追求还原 K/V 向量本身,而要尽量保住 attention 消费这些 KV 的方式。
从这个角度看,TurboQuant 等方法更偏向于把向量表示压得更紧;OSCAR 则把目标进一步对准 attention 质量本身。朴素 INT2 和全层 3-bit K/V 的 TurboQuant 在难推理任务上会出现明显掉分,而 OSCAR 在约 2.28 effective bits per KV element 的预算下依然能接近 BF16,并且在 Qwen3-4B-Thinking 上相比 3-bit K/V TurboQuant 最高提升 40.1 分。
OSCAR 的动机
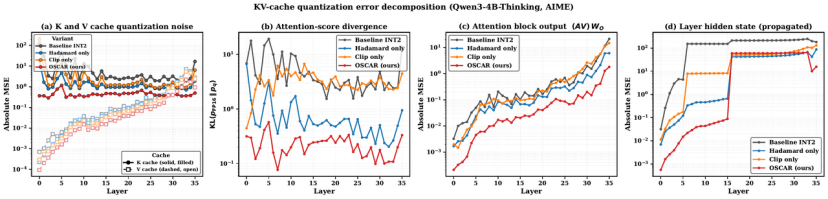
图 1:只用 K/V 重建误差判断低比特效果,容易看漏真正的误差传播
图 1 把 naive INT2、Hadamard-only、clip-only 和 OSCAR 放在同一条误差链路里比较。它想说明的是,原始 K/V 的重建误差并不能充分预测最终生成质量。更直接影响模型表现的,是 attention-score KL、attention block output MSE,以及这些偏差继续传到后续 hidden state 后形成的误差。OSCAR 的优势并不只是让数值分布看起来更平滑,而是把量化噪声尽量推到 attention 相对不敏感的方向上。
OSCAR 的设计
具体到 key,量化误差会通过 QKᵀ 进入 attention logits,所以 OSCAR 使用 query covariance,也就是 QᵀQ,来决定 key 的旋转目标。对于 value,误差会先被注意力权重加权,再进入 attention 输出,因此 OSCAR 采用 score-weighted value covariance,即 VᵀSᵀSV。离线校准时,系统用少量样本估计这些 attention-aware covariance,并为每一层、每一个 head 生成固定旋转矩阵和 clipping 阈值。
最终旋转可以写成 R = U · Hadamard · bit-reversal。其中,U 用来对齐 attention 相关方向,Hadamard 负责把 outlier 能量摊开,bit-reversal 则让 INT2 分组更加均衡,避免某个 group 被少数通道主导。也就是说,OSCAR 不是简单地“加一个旋转”,而是把旋转、裁剪和分组都放进了 attention 质量这个目标函数里。
更关键的是,OSCAR 并不是只在离线量化评测里报告分数。它已经进入 SGLang 的服务路径,在运行时维护一个三段式 token pool:
BF16 sink (64 tokens) | INT2 history | BF16 recent (256 tokens)
sink token 和 recent window 继续用 BF16 保存,用来保护 attention sink 与最近上下文;中间占比最大的历史段则保存为旋转后的 INT2。新 token 会先写入 recent window,随着解码向前推进,最老的 recent token 再由融合 Triton kernel 完成 rotate、clip、quantize 和 pack,并降级进入 INT2 history。存储上,每 4 个 2-bit 数值被打包进 1 个 byte。
decode 阶段,OSCAR 在 GPU 上分别处理 BF16 段和 INT2 段:INT2 kernel 负责 unpack、scale/zero point 反量化以及浮点累加,BF16 kernel 处理 sink/recent,最后再通过 online softmax merge 合并两部分结果。由于它兼容 paged KV、radix prefix cache 和 SGLang 的 fused kernel pipeline,所以 OSCAR 面向的是可落地的长上下文 workload,而不是只展示论文曲线。
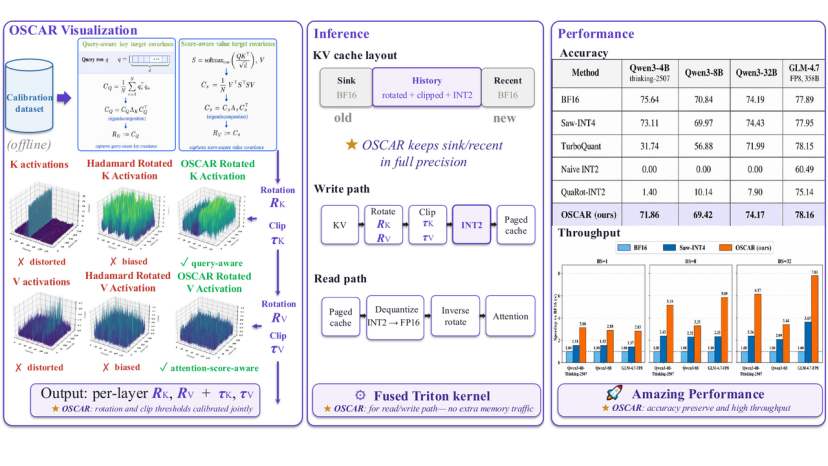
图 2:OSCAR 从离线校准到在线推理的整体链路
图 2 展示了这条 pipeline 的完整路径。左侧是校准阶段:系统从少量样本中估计 attention-aware rotation 和 clipping threshold,让 KV activation 在进入 INT2 之前更适合低比特表示。右侧是在线阶段:sink/recent 保留 BF16,中间最长的 history KV 进入旋转后的 INT2 cache,并在 SGLang paged KV 体系里完成真实 serving。换句话说,OSCAR 不是一个孤立量化技巧,而是一整套 2-bit KV Cache 服务方案。
评估结果
论文在 Qwen3-4B-Thinking、Qwen3-8B、Qwen3-32B 和 GLM-4.7-FP8 上做了测试,任务覆盖 GPQA、HumanEval、LiveCodeBench v6、AIME25 和 MATH500,最长生成长度达到 32K,并且每个配置运行 5 次取平均。OSCAR 在 2.28 BPE 下,Qwen3-4B-Thinking 距离 BF16 只差 3.78 分,Qwen3-8B 距离 BF16 只差 1.42 分;到 Qwen3-32B 和 GLM-4.7-FP8 时,整体表现已经基本贴近 BF16。
对照组的情况要残酷得多:QuaRot-INT2 和 naive INT2 在 reasoning / coding 任务上经常直接失效;TurboQuant 在全层 3-bit K/V、没有 mixed-precision 保护的公平设置下,小模型推理分数也有明显损失。论文还在 128K 长上下文下做了 RULER-NIAH 测试,OSCAR 在 Qwen3-8B 与 GLM-4.7-FP8 上都保持了更稳定的检索能力,说明 attention-aware rotation 不只适用于短 benchmark,也能缓解超长历史中 KV 误差逐步累积的问题。
系统层面的收益同样直接。相较 BF16 history storage,OSCAR 可以把 KV Cache memory 压低约 8 倍;在 100k context、batch-size-1、full prefix-cache hit 的设置下,decode 最高约 3 倍加速;在大 batch 且显存预算固定时,job-level throughput 最高约 7 倍。prefix cache 命中率越高,更小的 KV footprint 就越能转化为并发吞吐,这对共享系统提示、多轮 Agent 和工具调用循环等长前缀复用场景很有意义。
精度表现
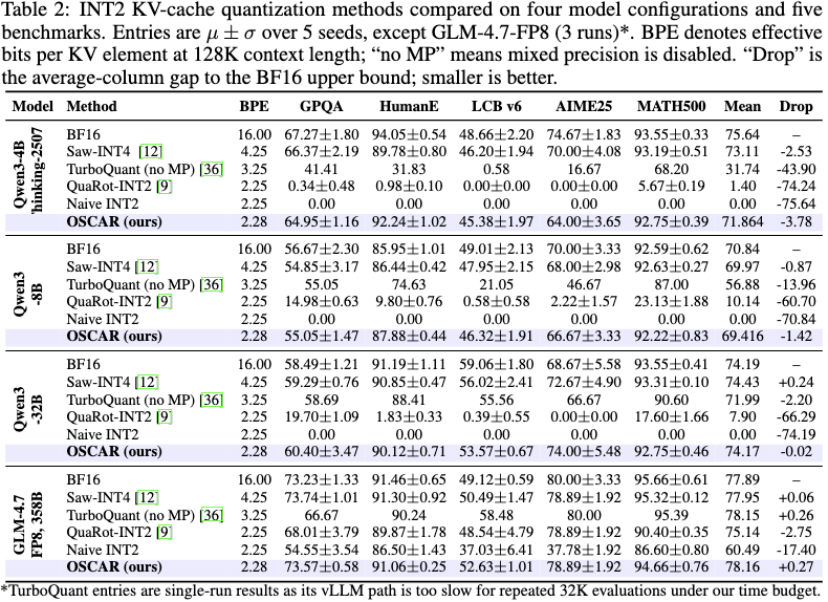
图 3:主结果表,多种 KV 量化方法在同一评测设置下对比
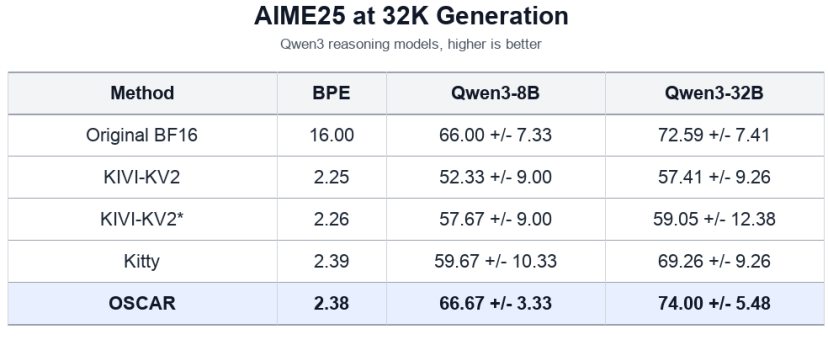
图 4:AIME25 32K 生成场景下,OSCAR 与 KIVI / Kitty 的专项比较
图 3 是论文的核心结果表,把 BF16、Saw-INT4、TurboQuant、QuaRot-INT2、Naive INT2 和 OSCAR 放在四个模型、五个任务上比较。BF16 作为精度上界;Saw-INT4 是 4-bit 强参考,BPE 为 4.25;TurboQuant 在这里采用无 mixed-precision 保护的全层 3-bit K/V,BPE 为 3.25;QuaRot-INT2 与 Naive INT2 则代表接近 2-bit 的旋转基线和朴素基线,BPE 约为 2.25;OSCAR 的运行预算为 2.28 BPE。
这张表真正要看的不是某一个任务的波动,而是低比特方案能否跨模型稳定工作。以 Qwen3-4B-Thinking 为例,TurboQuant mean 为 31.74,QuaRot-INT2 只有 1.40,Naive INT2 为 0.00;OSCAR 达到 71.86,距离 BF16 只差 3.78,并且比 TurboQuant 高 40.1 分。在 Qwen3-8B 上,OSCAR mean 为 69.42,BF16 为 70.84,TurboQuant 为 56.88。到了 Qwen3-32B 和 GLM-4.7-FP8,OSCAR 与 BF16 基本持平。
图 4 专门看 AIME25 这个高难数学推理任务,同时加入 KIVI-KV2、Kitty 和 OSCAR 的对比。由于 KIVI 和 Kitty 没有可直接用于 long context run 的 framework 支持,论文选取了它们唯一在 32K 下汇报的 AIME25 结果。在 Qwen3-8B 上,OSCAR 以 2.38 BPE 达到 66.67,几乎追平 BF16 的 66.00,并明显高于 KIVI-KV2 与 Kitty;在 Qwen3-32B 上,OSCAR 达到 74.00,略高于 BF16 的 72.59,也超过 Kitty 的 69.26。这说明 OSCAR 的优势不只体现在与 TurboQuant 的比较中,在现有 KV-cache 量化方法里,它也能以接近 2-bit 的预算守住困难数学推理能力。
系统加速

图 5:100k 长上下文下的 decode 加速与 batch throughput
图 5 关注 100k 上下文时的系统性能。在 batch-size-1 且 full prefix-cache hit 的纯 decode 场景里,OSCAR 最高带来约 3 倍加速;当显存预算固定、batch size 继续增大时,INT2 history 让 KV footprint 明显下降,从而把 job-level throughput 推高到最多约 7 倍。它的含义很直白:OSCAR 不只是精度曲线好看,也确实减轻了显存和带宽压力。
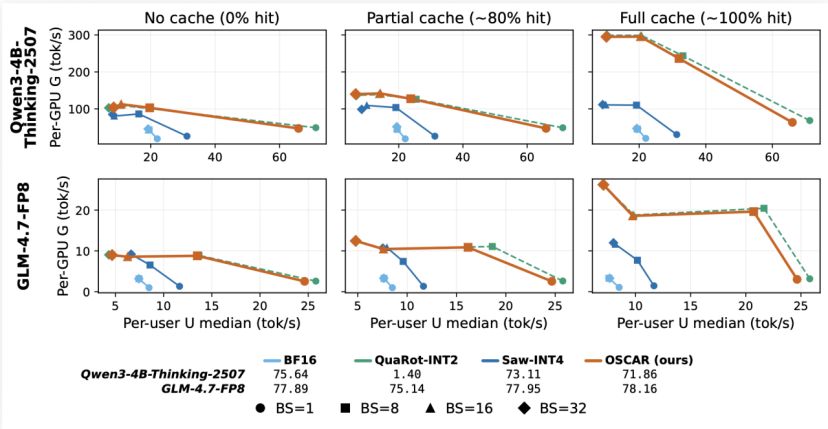
图 6:prefix cache 命中率提升后,吞吐前沿继续外移
图 6 展示了 prefix-cache hit ratio 对端到端 serving throughput 的影响。横轴是单用户吞吐,纵轴是单 GPU 吞吐;从关闭 cache,到 normal cache,再到接近 100% warmup replay,吞吐前沿会逐步向外扩张。由于 OSCAR 保留标准 paged KV / prefix cache 抽象,共享系统提示、多轮 Agent、工具调用链路这类长前缀高复用场景可以直接吃到收益。
还有一点值得注意:OSCAR 并没有通过“少数层保留高精度”来换分。很多低比特方法在部署时会把第一层、最后一层或若干敏感层保留在更高 bit,这会抬高平均 bit 数,也会让 kernel 和 cache layout 更复杂。OSCAR 的设置更接近真实服务:历史 KV 主体统一使用 INT2,只在 sink 和 recent 两个很小窗口保留 BF16。这让它更容易接进 paged cache、prefix cache 和批量调度。
总结
OSCAR 的意义不只是在小模型或短上下文上跑出好分数。论文同时覆盖 4B、8B、32B 和 GLM-4.7-FP8 这类不同规模模型;既评估了数学、代码、知识问答等 32K 推理生成任务,也测试了 128K RULER-NIAH 长上下文检索。短任务里,它能贴近 BF16;长上下文里,它也能让 attention 分布随历史增长保持更稳定。这说明 attention-aware rotation 不是只针对某个 benchmark 调参,而是在处理 KV 误差随上下文长度累积这个更根本的问题。
从应用角度看,这对长上下文 Agent 特别重要。真实 Agent 往往包含很长的系统提示、工具说明、历史对话和检索内容,不同请求之间还会存在大量共享前缀。如果 KV Cache 全部用 BF16,显存很快会成为天花板;如果直接上朴素 INT2,推理链条又可能失真。OSCAR 在二者之间给出了一种更系统的折中:长历史用 INT2 降容量和带宽,关键 sink/recent 用 BF16 保稳定,再让 prefix cache 复用共享前缀。
TurboQuant 仍然是很强的通用 online vector quantization 方法;OSCAR 更专注于 attention-aware 的 2-bit KV serving。两者也并非只能二选一,未来完全可以把 OSCAR 的 attention-aware rotation 与更强的 TurboQuant codebook 结合,把压缩率继续推向极限。OSCAR 带来的关键启发是:2-bit KV Cache 如果要真正上线,旋转不能只追求“有”,而要对准 attention;同时,它也必须被放进真实 serving 系统里一起设计。
资料链接:
论文:https://arxiv.org/abs/2605.17757
项目主页:https://oscar-quantize.github.io/
代码:https://github.com/FutureMLS-Lab/OSCAR
RotationZoo:https://huggingface.co/Zhongzhu/OSCAR-RotationZoo
作者介绍:
Zhongzhu Zhou 是 Together AI 的 Senior Research Scientist,悉尼大学博士,研究方向包括高效机器学习系统、模型训练与推理的算法系统协同设计,以及 LLM 压缩与量化。团队成员来自 Together AI、悉尼大学和伊利诺伊大学厄巴纳—香槟分校。
Together AI 创立于 2022 年 6 月,联合创始人包括苹果前高管 Vipul Ved Prakash、斯坦福大模型研究中心主任 Percy Liang、芝加哥大学副教授 Ce Zhang,以及 FlashAttention 作者 Tri Dao。




