

引言
当一个新人刚加入公司的时候,我们通常告诉新人怎么去写一个自动化用例:从工程配置到如何添加接口、如何使用断言,最后到如何将一个用例运行起来。
而在实际工作和业务场景中,我们常常面临着需要编写和组织一堆用例的情况:我们需要编写一个业务下的一系列的自动化接口用例,再把用例放到持续集成中不断运行。面临的问题比单纯让一个用例运行起来复杂的多。
本人加入有赞不到一年,从写下第 1 个 case 开始,持续编写和运行了 1000 多个 case ,在这过程中有了一些思考。在本文中,和大家探论下如何编写大量自动化接口用例以及保持结果稳定。
一、执行效率
目前使用的测试框架是基于 spring ,被测接口是 dubbo 的服务。 dubbo 的架构如图(源自官网)
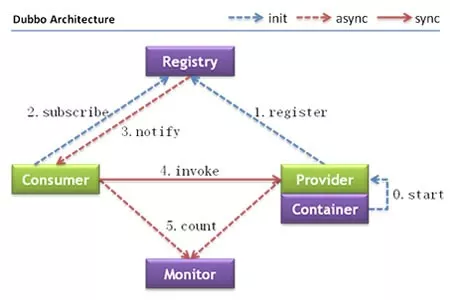
服务使用方的初始化需要经历以下这几个步骤:
监听注册中心
连接服务提供端
创建消费端服务代理
本地调试用例时,发现速度非常慢,运行一个用例需要 30s,而实际执行用例逻辑的时间大概在 1s 左右,主要时耗在服务消费者的初始化阶段。
测试工程中,各服务的 test 类继承了同一个基类,基类里面做了各服务的初始化的步骤。在对接的服务数目较少时,需要初始化的对象较少,对用例运行的影响并不大,但随着业务的增多,服务数目也增多,导致跑 A 服务接口的用例时把大量未用到的 B 服务、C 服务也一起初始化了,导致整体时耗大大增加。
解决办法:在运行用例时只初始化需要的服务使用方,减少不必要的初始化开销。
二、用例编写和维护
一个用例示例
以一个简单的业务场景为例:商家可以在后台创建会员卡给店铺的会员领取,商家可以对会员卡进行更新操作,这里需要有一个自动化用例去覆盖这个场景。
用例编写的基本步骤为:
step 1 :准备数据构造新建会员卡和更新会员卡的对象
step 2 :执行创建会员卡
step 3 :执行更新会员卡
step 4 :检查更新结果
step 5 :清理创建的会员卡
转换成代码为:
按照预期的步骤去写这个 case ,可以满足要求,但是如果需要扩展一下,编写诸如:更新某种类型的会员卡、只更新会员卡的有效期这样用例的时候,就会觉得按这个模式写 case 实在太长太啰嗦了,痛点在以下几个地方:
数据准备比较麻烦,需要逐一设值
数据检查部分逐字段检查,心好累
每个创建相关的用例都需要清理资源,每次都需要做一次,太重复了
用例本身关注的是更新这个操作,却花了太多时间和精力在其他地方,很多是重复劳动。代码编写里有一个重要原则,DRY(Don’t Repeat Yourself),即所有重复的地方都可以考虑抽象提炼出来。
三段式用例
可以将大部分用例的执行过程简化为三个部分:
数据准备
执行操作
结果检查
用简单的三个部分来完成上述用例的改写:
数据准备:
执行操作+结果检查
其中可行的优化点将在下面娓娓道来。
测试数据的优化
在这个用例中,数据准备的部分使用了 dataProvider 来复用执行过程,这样不同参数但同一过程的数据可以放在一个 case 里进行执行和维护。
数据生成使用了工厂方法 CardFactory ,好处是简化了参数,避免了大量 set 操作(本身包装的就是 set 方法);另一方面,根据实际的业务场景,可以考虑提供多个粒度的构造方法,比如以下两个构造方法需要提供的参数差别很大:
第一个主要用在验证创建接口的场景,检查各个传入的参数是否生效。
第二个用在如删除的场景,所以只需要一个创建好的会员卡对象,并不是很关注创建的内容是什么。
在上面的优化过的用例中,能够执行更新操作的前置条件是需要有一个已经创建的会员卡,在实际用例编写的时候通过直接创建一个会员卡,然后执行更新完成后再回收删除这张会员卡来满足这个条件。另一种提供满足操作所需前置数据的方式是预置数据(预先生成数据)。
以下情况可以考虑预置数据的方式:
提高用例稳定性,解依赖,加快执行速度
需要对特定的类型、状态的对象进行查询
创建或者构造比较麻烦
典型的场景:比如编写查询的用例时预先创建满足条件的对象供查询用例使用。
谈到预置数据,不得不谈的一个问题是数据管理。在编写用例的时候,“我们往往需要一个____的资源”,框框里面的即是对数据的描述和要求,比如我需要一个全新的账号,一个支付过的订单号,一张免费的会员卡,来完成我们的用例。所以需要对数据进行标记而不是简单硬编码的方式在用例中使用。
如:通过特定名字的变量名和数据进行关联。
对数据进行标记后,会发现有一部分数据是用来验证写操作(如创建、更新),有一部分数据是查询使用。如果数据又要被写操作的 case 使用,又要被读操作的 case 使用,那么写操作的问题和异常就会影响读操作 case 的执行结果。所以,在代码工程中,可以进行约定,将读写用到的资源进行分离来降低数据的耦合:
查询 case 用的账号不做更改对象的操作
查询 case 用的对象不做修改、删除的操作
验证增、删、改行为的资源使用特定账号,且资源最后做回收删除处理(因为资源总数有限)
最后,用例执行完成后需要清理资源。这里的清理资源采用的是一个全局的 list 的方式保存需要清理的资源信息,在用例执行过程中往里增加数据:recycleCardAlias.add(cardBaseDTO.getCardAlias());,
然后用对应的方法取其中的数据进行删除,类似垃圾桶。与原有执行完就执行清理动作相比,使用垃圾桶更加灵活,可以选择控制下清理频率。
比如每次在 AfterMethod 或 AfterClass 中去清理。
对方法的适度封装
在实际编写用例的时候,有两个地方可以考虑进行方法封装,从来简化调用,方便维护:
封装基本操作。如果删除操作依赖创建操作,查询操作依赖创建操作,那么创建操作可以看作是个基本操作,可以对创建操作包装一下,将注意力关注于实际需要执行和验证的地方。可以封装的东西很多,有参数封装、异常处理的封装、一些轮训、重新逻辑的封装。
createCard()、getCard()、deleteCard方法就是将接口、参数组装、检查等封装好的方法。封装检查方法。上述用例中的检查采用了一个检查方法代替了以往的多个 assert:
checkUpdateCardResult(ori,updated,updateDesc,kdtId);,在方法里包装了一些关键字段的比较,包括两个对象之间成员是否一致的比较。所有的更新操作的结果都需要满足:有变更的字段值变成新的值,未发生变更的值和原有一致。该方法实现了这种检查逻辑,所以写更新操作用例的同学不需要关注如何校验,而是关心如何更新,因为检查逻辑是现成的、通用的。将来检查逻辑发生变更,也只需要维护这一个方法即可。
稳定性
当大批量用例进行运行时,用例集的失败率会变得较高,几个微小的瑕疵都会造成用例的失败,此时我们需要更加关注用例的稳定性。一些实践中比较好的措施和方式:
减少外部依赖。如果执行过程需要依赖其他系统的接口的话,那么其他系统发生了变更或故障就会影响自身用例的进行。可以考虑通过预先生成的数据来替代调用外部接口生成数据在用例中使用。
预置数据代替创建过程。由于操作越多稳定性越低,使用预置数据而不是实时生成它,速度更快,稳定性更高。
使用不同账号等进行隔离。通过隔离,用例执行失败的脏数据就不会影响其他用例。
调优:超时、等待时间。线上超时时间设置的比较短,测试环境的机器配置不如线上,需要适时调大超时和等待时间来保证接口调用不会超时。
防御式编程。编写测试代码时不能假设数据已存在或者没有脏数据残留,所以预先的判断和清理很重要,比如检查到数据缺失就实时修复、用例运行之前考虑清除临时数据。
定位并解决不稳定的问题。有时候偶现用例失败,可以考虑给被测应用增加日志,同时持续多次运行用例多次(如 testNg 里增加
threadPoolSize=1,invocationCount=50)来复现问题,最终解决问题。
总结
对于大规模用例的编写、组织和运行的问题,文中从三个方面给出了有赞测试的实践和思考:精简初始化来提高执行速度、优化用例编写降低编写和维护成本、多种方式提高用例稳定性,希望能给大家一些启发。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论